
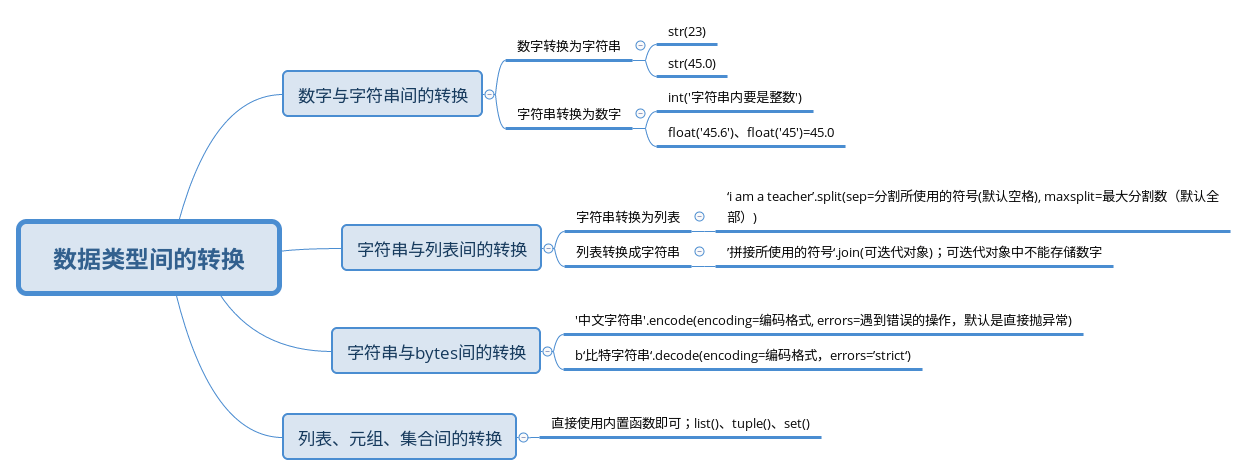
数据类型转换:将自身数据类型转化成新的数据类型,并拥有新数据类型相关操作的过程;
为方便更好的帮助处理业务,将数据变更为更适合业务场景的类型;
a = ‘1’, 此时想使用数字的数学操作,就需要先将字符串转化为数字类型;
1.数字与字符串间的转换
# 字符串转换成整数
a = '34'
b = int(a)
print(b) # 34
# 此时字符串内必须是整数,否则会报错
# print(int('45.6')) # ValueError: invalid literal for int() with base 10: '45.6'
# 字符串转换成浮点数
print(float('45.6')) # 45.6
print(type(float('45.6'))) # <class 'float'>
print(float('45')) # 45.0
# 数字转换成字符串
c = 34
print(str(c)) # 34
print(type(str(c))) # <class 'str'>
print(str(45.6)) # 45.6
2.字符串与列表之间的转换
字符串转换成列表:spring.split(sep=分割符, maxsplit=最大分割次数);
列表转换成字符串:’分割符号’.join(可迭代对象);可迭代对象存储的数据不能是数字类型;
str_test = 'i am a teacher'
print(str_test.split()) # ['i', 'am', 'a', 'teacher'] (默认分割符是空格、默认分割次数为全部)
print(str_test.split(maxsplit=2)) # ['i', 'am', 'a teacher']
print('wer#ty#67'.split('#', 1)) # ['wer', 'ty#67']
# 若指定的分割符不存在,则完整字符串作为一个元素存入列表
print('i love you'.split('!')) # ['i love you']
# 分割符不能是空字符串,会报错
# print(a.split('')) # ValueError: empty separator
text = "23,王伟,2-1"
print(text.split(',')) # ['23', '王伟', '2-1'] (此时2-1属于字符串)
# print(' '.join(['python', 56])) # TypeError: sequence item 1: expected str instance, int found
print(' '.join(['python', 'go'])) # python go
print('!!!'.join(('python', 'go'))) # python!!!go
print(' '.join({'python', 'go'})) # go python
print(' '.join({'name': 'll', 'height': 178})) # name height (字典拼接的是key)
3.字符串类型与比特类型的转换
比特类型是一种特殊的二进制的数据流, bytes;
可以看做是一种特殊的字符串,写法是字符串前加b;
字符串转换bytes, string.encode(encoding=编码格式, errors=’strict’)
encoding是编码格式、默认是utf-8, 还可以是ascii或gbk等,errors是遇到错误时的操作,默认是strict直接抛异常、也可以指定为ignore, 忽略错误;
bytes转换成字符串,bytes.decode(encoding=编码格式,errors=’strict’)
a = b'hello world'
print(a) # b'hello world'
print(type(a)) # <class 'bytes'>
# bytes类型也可以使用一些字符串的方法, 可以利用dir()函数查看所用相关方法
print(dir(bytes))
'''
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__',
'__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__',
'__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__',
'capitalize', 'center', 'count', 'decode', 'endswith', 'expandtabs', 'find', 'fromhex', 'hex', 'index', 'isalnum',
'isalpha', 'isascii', 'isdigit', 'islower', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip',
'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split',
'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
'''
# replace()
new_a = a.replace(b'h', b'aaa') # 注意传的参数也要是比特类型
print(new_a) # b'aaaello world'
# 比特数据中不能带中文,可以先将字符串转换下
# b = b'你好 world' # SyntaxError: bytes can only contain ASCII literal characters.
# print(b)
b = '你好 world'
new_b = b.encode('utf-8')
print(new_b) # b'\xe4\xbd\xa0\xe5\xa5\xbd world'
reduction_b = new_b.decode('utf-8')
print(reduction_b) # 你好 world
4.列表、元组、集合间的转换
直接调用相关内置函数即可;
list()、tuple()、set()
test_list = [34, 56]
tuple_test = tuple(test_list)
print(tuple_test) # (34, 56)
print(type(tuple_test)) # <class 'tuple'>
new_tuple = (45,)
set_test = set(new_tuple)
print(set_test) # {45}
print(type(set_test)) # <class 'set'>
print(list(set_test)) # [45]
print(type(list(set_test))) # <class 'list'>
总结
原文地址:http://www.cnblogs.com/white-list/p/16813764.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性