
微服务架构学习与思考(11):开源 API 网关02-以 Java 为基础的 API 网关详细介绍
上一篇关于网关的文章:
微服务架构学习与思考(10):微服务网关和开源 API 网关01-以 Nginx 为基础的 API 网关详细介绍,介绍了为什么会有网关及以 Nginx 为基础的网关。
一、网关 zuul
zuul 网关使用 java 语言开发,是 Netflix 公司出品的开源网关。它是 SpringCloud 的组件之一。zuul 有 2 个大的版本:
-
zuul1:zuul1 wiki
-
zuul2:zuul2 wiki
1.1 zuul1 架构
zuul1 是基于 Servlet 构建的,采用的是阻塞和多线程方式,它一个线程处理一次连接。I/O 操作是通过从线程池中选择一个工作线程执行 I/O 来完成的,并且请求线程将阻塞,直到工作线程完成为止。工作线程在其工作完成时通知请求线程。如下图:
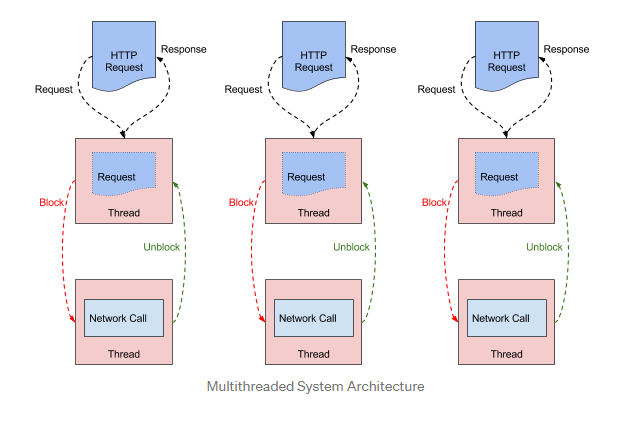
(netflix blog: https://netflixtechblog.com/zuul-2-the-netflix-journey-to-asynchronous-non-blocking-systems-45947377fb5c)
这种处理线程模型,当后端API延迟增加或错误导致重试,线程数也会随之增加。这种情况发生时,就会给节点服务器带来麻烦,使服务器负载激增,为了消除这种麻烦,构建了限流机制(比如hystrix)保持系统的稳定。
zuul1 中网关功能怎么实现,在请求周期通过 Filter 实现,如下图:
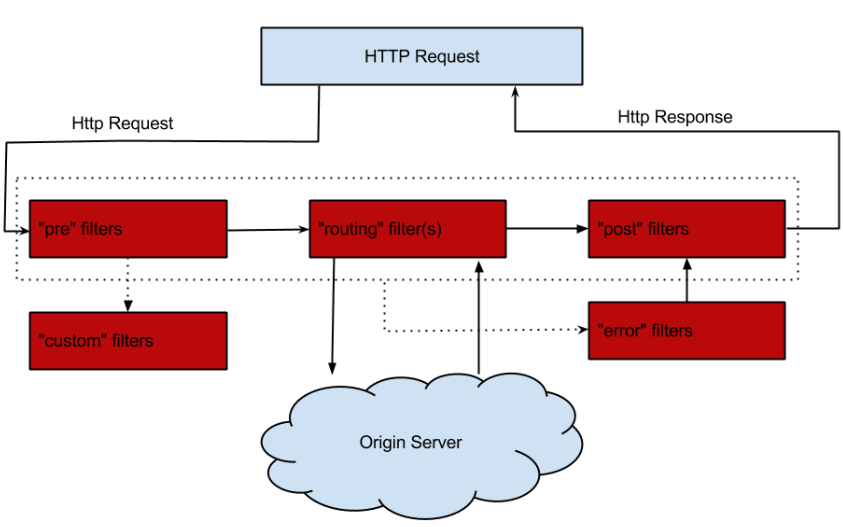
(from:https://github.com/Netflix/zuul/wiki/How-it-Works)
1.2 zuul2 架构
zuul2 对 zuul1 进行了重大的重构,采用异步和事件驱动模式处理程序。请求和响应的生命周期通过事件和回调机制来处理。没有像 zuul1 那样针对每个请求使用一个线程,不需要大量的线程成本,只需要一个文件描述符和一个监听器。而且像 zuul1 发生后端延迟和“重试风暴”,不是增加线程,zuul2 中是在队列中增加事件,这个开销比多个线程开销小得多。
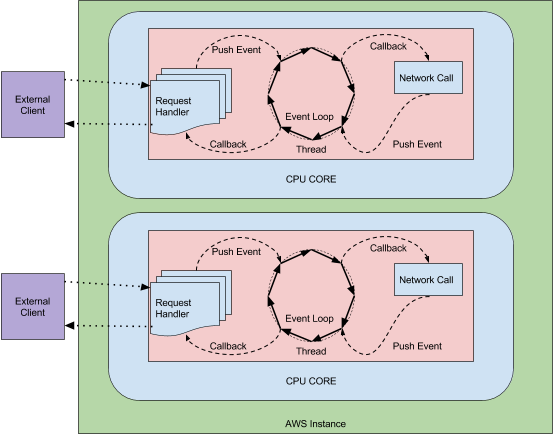
(netflix blog: https://netflixtechblog.com/zuul-2-the-netflix-journey-to-asynchronous-non-blocking-systems-45947377fb5c)
关于高性能网络IO编程模型,可以看我之前的文章,点击这里看文章
zuul2 网关中那么多功能是怎么实现的呢?是在请求周期(request cycle)中,通过 Filter 来处理实现。
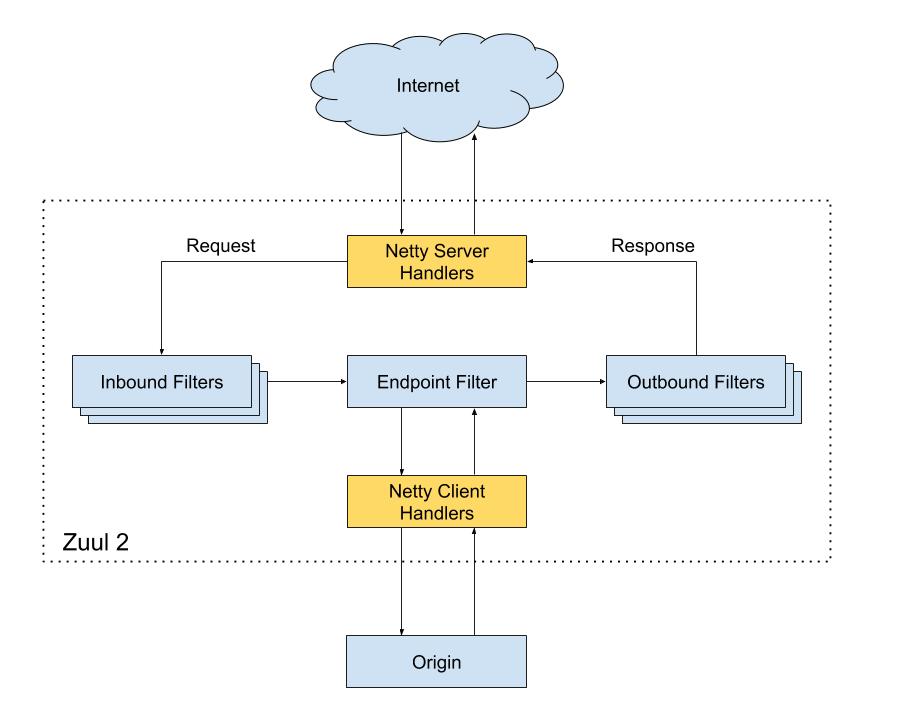
(from:https://github.com/Netflix/zuul/wiki/How-It-Works-2.0)
Filter:
Filter 过滤器是 zuul2 业务逻辑处理的核心,它可以在请求-响应周期的不同部分运行。分为 3 个 Filter:
- Inbound Filters:Inbound 过滤器,在请求到源之前执行,可用于身份验证、路由和装饰请求等处理操作
- Endpoint Filters:Endpoint 过滤器,可用于返回静态响应,否则内置的 ProxyEndpoint 过滤器会将请求路由到源。
- Outbound Filters:Outbound 过滤器,请求处理之后执行,可用于度量、装饰处理之后的请求或增加自定义 header。
更多 zuul2 Filter 用法请查看 Filter wiki。
说明:在 zuul2 中编写 Filter,使用的是 groovy 语言,它可以动态更新,不需要重启服务器。
1.3 zuul2 特性
- Core Features
- Push Messaging
二、SpringCloud Gateway
2.1 介绍
Spring Cloud Gateway3.1.x 旨在提供一种简单而有效的方式路由到 API,并为它们它们提供横切关注,比如:安全、监控和弹性。
它是构建在 Spring 生态之上,包括 Spring5、Spring2 和 Project Reactor(Spring WebFlux)。
Spring WebFlux 框架底层使用了 Reactor 模式高性能通信框架 Netty。
官网:官网地址
github: github 地址
Spring Cloud Gateway 是用来替代 zuul 网关,因为 zuul2 开发进度落后。
2.2 Spring Cloud Gateway 特性
Features:
- 基于 Spring Framework 5、Project Reactor 和 Spring 2.0 构建
- 能够在任何请求属性上匹配路由
- Predicates 和 Filters 作用于特定路由,易于编写的 Predicates 和 Filters
- 集成了断路器
- 集成了 Spring Cloud DiscoveryClient
- 很容易编写 Predicates 和 Filters
- 具备网关一些高级功能:动态路由、限流、路由重写
Spring Cloud Gateway 与 Eureka、Ribbon、Hystrix 等组件配合使用,实现路由转发、负载均衡、鉴权、熔断、路由重写、日志监控等功能。
Spring Cloud Gateway 中的重要概念:
(1) Filter(过滤器)
可以使用它来拦截和修改请求,并且对它的上文的响应进行处理。
(2) Route(路由)
网关配置的基本组成模块。一个 Route 模块由一个 ID,一个目标 URI,一组断言(Predicate)和一组过滤器(Filter)组成。如果断言为真,则路由匹配,目标 URI 会被访问。
(3)Predicate(断言):
路由转发的判断条件,可以使用它来匹配来自 HTTP 请求的任何内容,例如修改请求方式、请求头内容、请求路径、请求参数等。如果匹配成功,则转发到相应的服务里。
Predicate 是路由的匹配条件,匹配之后,Filter 就对请求和响应进行精细化处理。有了这两个工具,再加上目标 URI 可以实现一个具体的路由,就可以对具体的路由进行处理操作。
2.3 Gateway 处理流程
流程图:
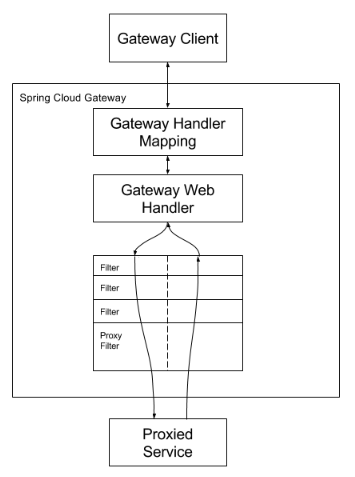
- 客户端向 Spring Cloud Gateway 发出请求
- Spring Cloud Gateway 通过 Gateway Handler Mapping 找到与请求相匹配的路由,将其发送到 Gateway Web Handler。
- Gateway Web Handler 通过指定的过滤器链(Filter Chain)来处理请求,然后发送到实际的执行业务服务中,业务逻辑执行完后返回。
- 业务逻辑执行完成后,又经过了过滤器链(Filter Chain),这里又可以对执行完后的业务逻辑进行加工处理。
说明:过滤器链中的虚线分开过过滤器,是表示过滤器会在业务逻辑处理之前进行 Filter 或处理完之后在进行 Filter。
在请求转发到服务端前(Proied Service 前),可以进行 Filter 处理(上图中虚线左边部分),例如权限检查、参数效验、流量监控、协议转换等处理。
在服务端处理完业务逻辑后,也可以进行 Filter 处理(上图中虚线右边部分),例如修改响应头、日志输出、流量监控等处理。
三、Apache ShenYu(神禹)
3.1 介绍
Apache ShenYu 是使用 Java reactor 编程方式开发的,是一个可扩展、高性能、响应式的 API 网关。
官网:ShenYu 官网
Doc: ShenYu Doc
3.2 架构
ShenYu version:2.5.0
整体架构流程图
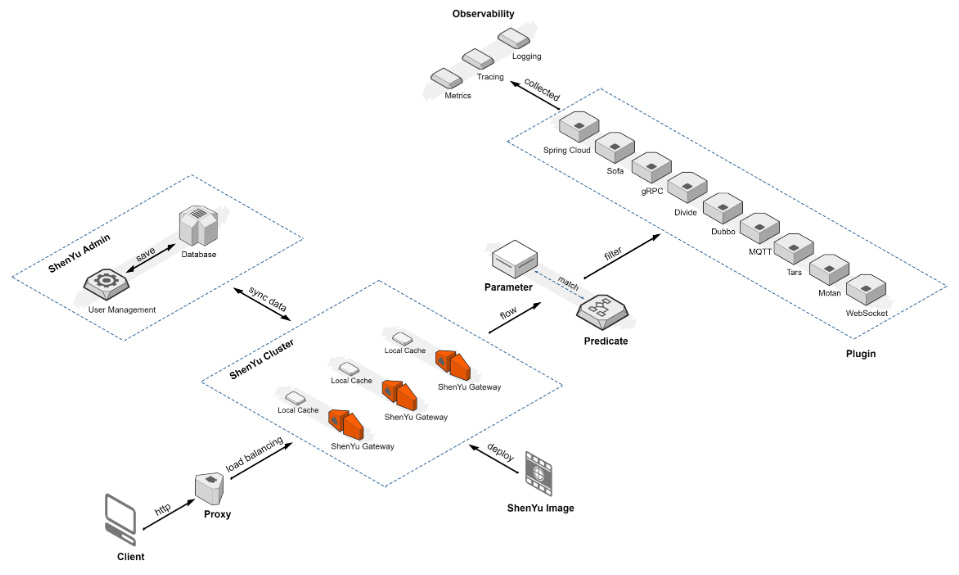
(来自:https://github.com/apache/shenyu)
- ShenYu Cluster
- ShenYu Admin,管理 ShenYu gateway
- Plugin
流量进入 -> ShenYu Cluster —> Predicate断言匹配 -> Filter -> Plugins
ShenYu 中的一些概念
插件、选择器、规则,这些元素都可以在 ShenYu Admin UI 后台进行配置管理。
- 插件:Apache ShenYu 使用插件化设计思想,可以实现插件的热插拔,易扩展。内置了丰富的插件,包括 RPC 代理、熔断和限流、权限认证、监控等等。
- 选择器:每个插件可以设置多个选择器,对流量进行初步筛选。
- 规则:每个选择器可以设置多个规则,对流量进行更细粒度的控制。
插件、选择器和规则执行规则:
当流量进入到 Apache ShenYu 网关之后,会先判断是否有对应的插件,该插件是否开启;
然后判断流量是否匹配该插件的选择器。
然后再判断流量是否匹配该选择器的规则。
如果请求流量能满足匹配条件才会执行该插件,否则插件不会被执行,处理下一个。
他们之间的数据关系,数据库 UML 图:
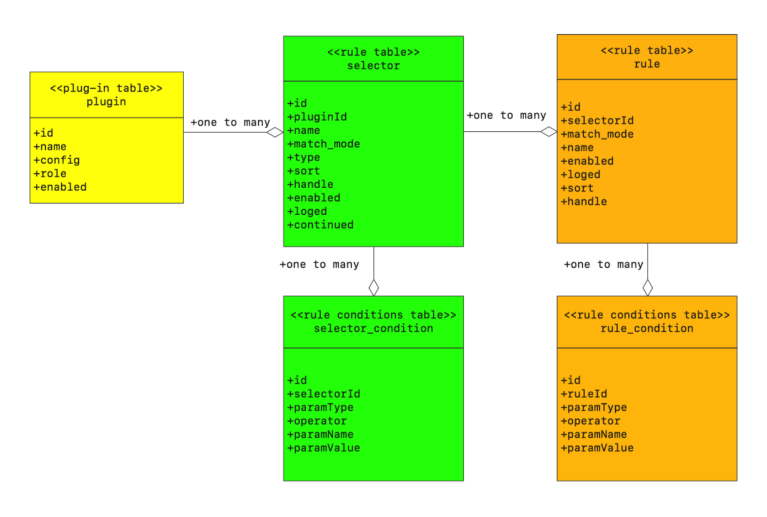
(来自:https://shenyu.apache.org/zh/docs/design/database-design)
说明:一个插件可以对应多个选择器,一个选择器可以对应多个规则,一个规则可以对应多个匹配条件。
3.3 ShenYu Admin 后台管理
Apache ShenYu Admin 是网关的后台管理系统,能够可视化管理所有插件、选择器和规则,设置用户、角色、控制资源。
这些更改通过数据同步到网关的 JVM 内存里。
Admin 使用文档:https://shenyu.apache.org/zh/docs/user-guide/admin-usage/data-permission
后台界面:

3.3 插件
内置插件
ShenYu 内置了很多插件。在 ShenYu Admin 后台可以设置这些插件。
比如设置 hystrix 熔断保护服务的插件。添加插件、设置插进的步骤详情请查看文档。
内置插件的文档:https://shenyu.apache.org/zh/docs/plugin-center/http-process/contextpath-plugin。
ShenYu 网关内置了很多插件,详情看文档。
自定义插件
文档:https://shenyu.apache.org/zh/docs/developer/custom-plugin
3.4 扩展功能
SPI 扩展
比如自定义负载均衡策略,可以对 org.apache.shenyu.loadbalancer.spi.LoadBalancer 进行自定义扩展。
详情文档:https://shenyu.apache.org/zh/docs/developer/spi/custom-load-balance
插件扩展
也就是自定义插件功能,上文有讲到过。
自定义 Filter
这里有一个示例,对 org.springframework.web.server.WebFliter 进行扩展。文档地址 -> filter 扩展
3.5 集群
第一种:
利用 Nginx 负载均衡能力实现集群功能,文档地址->集群。
第二种:
Apache Shenyu-nginx 模块实现集群,https://github.com/apache/shenyu-nginx,在 github 上的 README 看到这个功能模块还是一个实验性质的(到目前2022.10.21)。
四、参考
- https://github.com/Netflix/zuul/wiki/Getting-Started zuul1 wiki
- https://github.com/Netflix/zuul/wiki/Getting-Started-2.0 zuul2 wiki
- https://netflixtechblog.com/zuul-2-the-netflix-journey-to-asynchronous-non-blocking-systems-45947377fb5c
- https://github.com/Netflix/zuul/wiki/Filters zuul2 filter doc
- https://spring.io/projects/spring-cloud-gateway
- https://shenyu.apache.org/ ShenYu site
- https://shenyu.apache.org/zh/docs/plugin-center/http-process/contextpath-plugin ShenYu 插件文档
- https://shenyu.apache.org/zh/docs/developer/custom-filter ShenYu Filter 扩展
- https://shenyu.apache.org/zh/docs/deployment/deployment-cluster ShenYu 集群
原文地址:http://www.cnblogs.com/jiujuan/p/16814545.html