
DataFrame
-
DataFrame 是一种以 RDD 为基础的分布式数据集,类似于二维表格。与 RDD 的区别在于,前者带有 schema 元信息,即 DataFrame。
-
DataFrame 也是懒执行的,但性能上比 RDD 要高。因为优化了执行计划,查询计划通过 Spark catalyst optimiser 进行了优化。
-
DataFrame API 允许我们使用 DataFrame 而不用必须去注册临时表活着生成 SQL 表达式。
-
DataFrame API 既有 transfomation 操作也有 action 操作。
创建 DataFrame
在 Spark SQL 中 SparkSession 是创建 DataFrame 和执行 SQL 的入口,创建 DataFrame 有三种方式:
- 通过 Spark 的数据源进行创建。
- 从一个存在的 RDD 进行转换。
- 从 Hive Table 进行查询返回。
基本操作
// DataFrame
val df: DataFrame = spark.read.json("datas/user.json")
df.show()
// DataFrame => SQL 风格语法
// 创建视图
df.createTempView("user")
spark.sql("select * from user").show()
spark.sql("select age from user").show()
spark.sql("select avg(age) from user").show()
// DataFrame => DSL 风格语法
// 特定领域语言(domain-specific language),使用 DSL 不必去创建临时视图
df.select("age", "username").show()
// RDD => DataFrame => DataSet 转换需要引入隐式转换规则
// spark 不是包名,是上下文环境对象名
// 涉及到运算时,每列都必须使用 $,或者采用引号表达式:单引号+字段名
import spark.implicits._
df.select($"age" + 1).show()
df.select('age + 1).show()
DataSet
- DataSet 是分布式数据集合, 是 DataFrame 的一个扩展。
- DataSet 是强类型,可以有
DataSet[Person]、DataSet[Car]。 - DataFrame 是 DataSet 的特例,
DataFrame = DataSet[Row],Row是一个跟Person一样的类型,所有的表结构信息都用Row表示。
基本操作
// 使用基本类型的序列创建 DataSet
val seq: Seq[Int] = Seq(1, 2, 3, 4)
val ds: Dataset[Int] = seq.toDS()
ds.show()
// 使用样例类序列创建 DataSet
case class Person(name: String, age:Int)
val ds: Dataset[Person] = Seq(Person("zhangsan", 20)).toDS()
ds.show()
三者之间的关系
共性
- 都是分布式弹性数据集。
- 都有惰性机制,在进行创建、转换操作时,不会立即执行,只有遇到 action 操作才会执行。
- 都会根据 Spark 的内存情况自动缓存运算。
- 都有 Partition 的概念。
相互转换
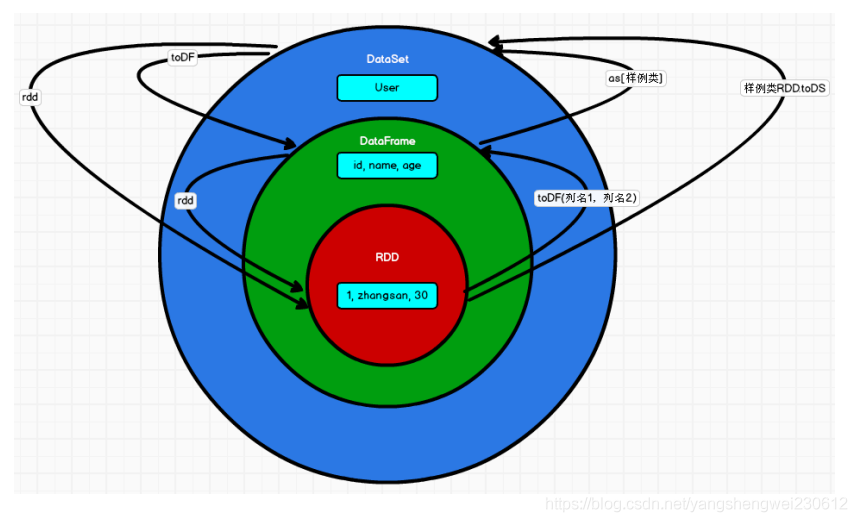
// RDD <=> DataFrame
val rdd: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(List((1, "zhangsan", 20), (2, "lisi", 30)))
val df: DataFrame = rdd.toDF("id", "name", "age")
val rowRDD: RDD[Row] = df.rdd
// DataFrame <=> DataSet
val ds: Dataset[User] = df.as[User]
val df1: DataFrame = ds.toDF()
// RDD <=> DataSet
val ds1: Dataset[User] = rdd.map {
case (id, name, age) => {
User(id, name, age)
}
}.toDS()
val userRDD: RDD[User] = ds1.rdd
case class User(id: Int, name: String, age:Int)
用户自定义函数
UDF
用户可以通过 spark.udf 功能添加自定义函数,实现自定义功能
val df = spark.read.json("datas/user.json")
df.createOrReplaceTempView("user")
// 自定义一个函数,函数名为prefixName,传入参数为name:String
spark.udf.register("prefixName", (name:String) => {
"Name: " + name
})
// 使用自定义的函数
spark.sql("select age, prefixName(username) from user").show
UDAF
强类型的 DS 和弱类型的 DF 都提供了相关的聚合函数:count()、avg() 等等。用户可以自定义聚合函数,通过继承 UserDefinedAggregateFunction 来实现用户自定义弱类型聚合函数。从 Spark3.0 开始,UserDefinedAggregateFunction 就不推荐使用了。可以统一采用强类型聚合函数 Aggregator
object UDAF {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
val df = spark.read.json("datas/user.json")
// 早期版本中,spark不能在sql中使用强类型UDAF操作
// SQL & DSL
// 早期的 UDAF 强类型聚合函数使用 DSL 语法操作
val ds: Dataset[User] = df.as[User]
// 将UDAF函数转换为查询的列对象
val udafCol: TypedColumn[User, Long] = new MyAvgUDAF().toColumn
ds.select(udafCol).show
spark.close()
}
/*
自定义聚合函数类:计算年龄的平均值
1. 继承org.apache.spark.sql.expressions.Aggregator, 定义泛型
IN : 输入的数据类型 User
BUF : 缓冲区的数据类型 Buff
OUT : 输出的数据类型 Long
2. 重写方法(6)
*/
case class User(username:String, age:Long)
case class Buff( var total:Long, var count:Long )
class MyAvgUDAF extends Aggregator[User, Buff, Long]{
// z & zero : 初始值或零值
// 缓冲区的初始化
override def zero: Buff = {
Buff(0L,0L)
}
// 根据输入的数据更新缓冲区的数据
override def reduce(buff: Buff, in: User): Buff = {
buff.total = buff.total + in.age
buff.count = buff.count + 1
buff
}
// 因为是分布式计算有多个缓冲区,需要合并每个缓冲区数据(即合并每个分区的计算结果)
override def merge(buff1: Buff, buff2: Buff): Buff = {
buff1.total = buff1.total + buff2.total
buff1.count = buff1.count + buff2.count
buff1
}
// 根据最后的结果,再执行具体的业务计算逻辑
override def finish(buff: Buff): Long = {
buff.total / buff.count
}
// 缓冲区的编码操作
override def bufferEncoder: Encoder[Buff] = Encoders.product
// 输出的编码操作
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
}
原文地址:http://www.cnblogs.com/fireonfire/p/16815903.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性