
一般情况下k-Nearest Neighbor (KNN)都是用来解决分类的问题,其实KNN是一种可以应用于数据分类和预测的简单算法,本文中我们将它与简单的线性回归进行比较。
KNN模型是一个简单的模型,可以用于回归和分类任务。大部分的机器学习算法都是用它的名字来描述的KNN也是一样,使用一个空间来表示邻居的度量,度量空间根据集合成员的特征定义它们之间的距离。对于每个测试实例,使用邻域来估计响应变量的值。估计可以使用最多k个邻域来进行,超参数控制算法的学习方式;它们不是根据训练数据估计出来的,而是基于一些距离函数选择的最近的k个邻居。
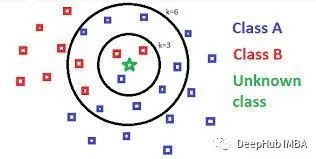
在本文中,我们将重点介绍二元分类,为了防止平局k通常设置为奇数。与分类任务不同,在回归任务中,特征向量与实值标量而不是标签相关联,KNN是通过对响应变量均值或加权均值来进行预测。
惰性学习和非参数模型
惰性学习是 KNN 的标志。惰性学习器,也称为基于实例的学习器,这种学习器很少或根本不处理训练数据。与线性回归等积极学习的算法不同,KNN 不会估计在训练阶段概括训练数据的模型的参数。惰性学习有利有弊,训练一个积极学习的成本可能很高,但使用生成的模型进行预测的成本少。通过将系数乘以特征并添加偏置参数就可以预测简单的结果,计算成本低,预测速度快。但是一个惰性的学习者做出预测的成本是很高的,因为KNN 预测需要在计算测试实例和训练实例之间的距离,也就是要访问所有的训练数据。
参数模型使用固定数量的参数或系数来汇总数据。无论使用多少个训练实例,参数的数量都保持不变。非参数可能看起来用词不当,因为它并不意味着模型没有参数;相反,它意味着参数的数量随着训练数据的数量而变化。
当不熟悉响应变量和解释变量之间的关系时,非参数模型可能会很有用。KNN 就是这种非参数模型,如果实例彼此接近,则响应变量可能具有相似的值。当训练数据稀缺或已经知道这种关系时,带有假设的模型可能会比非参数模型有用。
完整文章:
https://avoid.overfit.cn/post/25204154c52341f0bf93622a797597e1
原文地址:http://www.cnblogs.com/deephub/p/16818223.html