
两个月因为忙于工作毫无输出了,最近想给团队小伙伴分享下kafka的相关知识,于是就想着利用博客来做个提前的准备工作了;接下来会对kafka做一个简单的介绍,包括利用akf原则来解析单机下kafk的各个角色介绍、集群下kafka的架构、生产者消费者实操、offset的维护粒度、ack取不同值时kafka集群的表现等;
一、结合AKF来聊聊单机kafka的架构
简单介绍下AKF
- AKF是微服务的拆分原则,或者说可以跟任何分布式系统挂钩,AKF以坐标系的概念把系统划分为X、Y、Z三个轴,不同轴解决不同的问题
X轴:解决单点故障问题,对服务进行水平扩容,即集群中常见的主从、主备复制,把主机复制一份到远端来解决单点故障的问题
Y轴:解决系统压力问题,可将服务按业务拆分,不同的业务打到不同的集群节点;
Z轴:针对Y轴的补充,当Y轴扛不住压力时可对Y轴的服务做拓展
整合KAFKA来理解,如图:
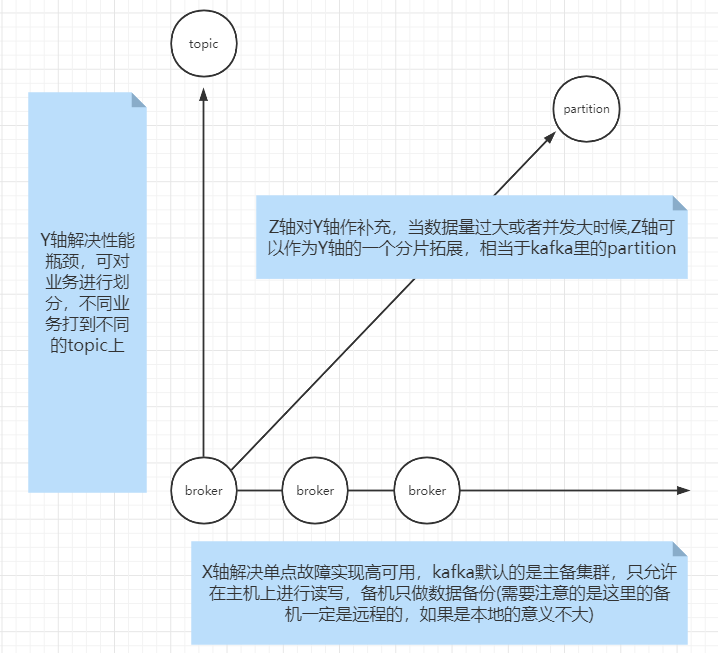
kafka常用角色介绍
- broker
可以理解为一个JVM进程,kafka的服务节点 - topic
一个逻辑概念,可以跨broker,可以拥有多个分区,用来对业务进行区分 - partition
真正存储数据的物理分区,存在于broker进程所在的物理机上
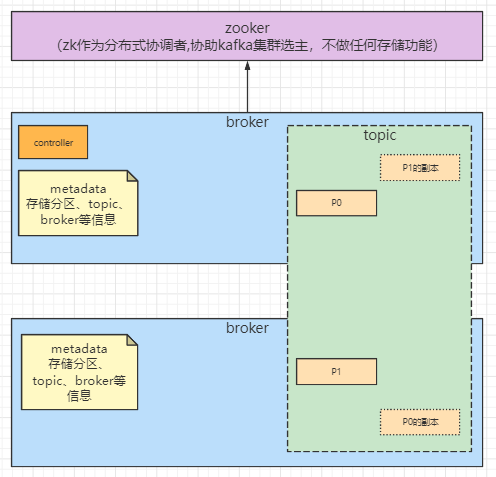
二、集群下kafka的结构
kafka的集群由zookeeper调度,现在的版本中zk更单纯的只做分布式的协调者,即为kafka集群选主,集群中各节点的信息由每个节点中存储的元数据(metadata)持有,所以生产者消费者可以直连broker集群从而降低zk的压力,详见下图:
三、入门实操
kafka和zk的安装与启动
为了方便测试的环境我是直接在windows上搭建的,下面简单介绍下
- 首先去官网分别下载zk和kafka的安装包然后解压出来
- 启动zk:进入zk的bin目录双击zkServer.cmd启动zk服务端
- 启动kafka:进入kafka安装目录,使用:.\bin\windows\kafka-server-start.bat .\config\server.properties启动kafka服务;需要注意的是为了zk根目录的简结也为了后续其他服务接入zk时能够区分,建议在kafka的config/server.properties文件中将zookeeper.connect的值再加一个目录后缀,如:localhost:2181/kafka01;这样也方便去zk查询当前kafka的节点信息
整合springboot搭建单元测试
- 首先可以通过命令行创建一个topic
进入kafka的bin/windows目录,调用:kafka-topics.bat –create –zookeeper localhost:2181/kafka01 –replication-factor 1 –partitions 2 –topic dll_test_01 - 生产者用例
package com.darling.controller.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.Test;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
/**
* @description: 生产者用例
* windows创建topic命令:kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
* @author: dll
* @date: Created in 2022/10/10 10:06
* @version:
* @modified By:
*/
public class ProducerTest {
@Test
public void producer() throws ExecutionException, InterruptedException {
String topic = "dll_test_01";
Properties p = new Properties();
// broker的地址
p.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
// k-v的序列化设置
p.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
p.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// ack设置,0
p.setProperty(ProducerConfig.ACKS_CONFIG, "-1");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(p);
while(true){
for (int i = 0; i < 3; i++) {
for (int j = 0; j <3; j++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "item"+j,"val" + i);
Future<RecordMetadata> send = producer.send(record);
RecordMetadata rm = send.get();
int partition = rm.partition();
long offset = rm.offset();
System.out.println("==============key: "+ record.key()+" val: "+record.value()+" partition: "+partition + " offset: "+offset);
}
}
}
}
}
- 消费者用例
package com.darling.controller.kafka;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.junit.Test;
import java.time.Duration;
import java.util.*;
/**
* @description: 消费者用例
* @author: dll
* @date: Created in 2022/10/10 12:33
* @version:
* @modified By:
*/
@Slf4j
public class ConsumerTest {
@Test
public void consumer() {
//基础配置
Properties p = new Properties();
// 设置brokers
p.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
// k-v序列化
p.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
p.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//设置消费组
p.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"GROUP_TEST");
/**
* 设置消费时消费消息的位置
* earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
* latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
* none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
*/
p.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest");
//是否自动提交offset,默认是true
p.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(p);
//kafka 的consumer会动态负载均衡
consumer.subscribe(Arrays.asList("dll_test_01"), new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("---onPartitionsRevoked:");
Iterator<TopicPartition> iter = partitions.iterator();
while(iter.hasNext()){
System.out.println(iter.next().partition());
}
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
System.out.println("---onPartitionsAssigned:");
Iterator<TopicPartition> iter = partitions.iterator();
while(iter.hasNext()){
System.out.println(iter.next().partition());
}
}
});
while(true){
// 拉取数据
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(0));// 0~n
if(!records.isEmpty()){
log.info("-----当前拉取的消息数量------{}-------------",records.count());
// 获取当前批次拉取的消息分区
Set<TopicPartition> partitions = records.partitions(); //每次poll的时候是取多个分区的数据
// 遍历分区获取消息数据
for (TopicPartition partition : partitions) {
List<ConsumerRecord<String, String>> pRecords = records.records(partition);
Iterator<ConsumerRecord<String, String>> piter = pRecords.iterator();
while(piter.hasNext()){
ConsumerRecord<String, String> next = piter.next();
int par = next.partition();
long offset = next.offset();
String key = next.key();
String value = next.value();
long timestamp = next.timestamp();
log.info("key: "+ key+" val: "+ value+ " partition: "+par + " offset: "+ offset+"time:: "+ timestamp);
}
}
}
}
}
}
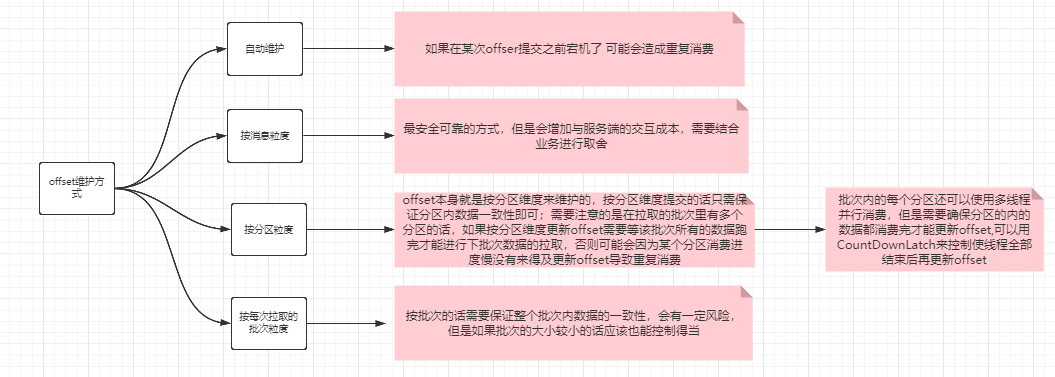
四、offset的维护粒度
- offset即偏移量,表示消费者的消费进度,对kafka的服务端来说是基于partition来维护的,即分区的数据被某组的某个consumer消费的进度;kafka只关注与数据的存储和传输,不负责加工,不维护状态,每次从哪开始消费需要consumer提供offset来确定;通过上面的用例我们可以看到消费者消费的时候可选择是否对ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG属性进行设置,默认值是true,表示系统自动提交offset,下面分析下自动提交、以消息维度、分区维度和批次维度来维护offset的优缺点
- 自动提交offset
即消息者不显示维护offset,由程序自动在指定时间内提交;这样做的优点就是降低开发复杂度,缺点就是自动提交不可控,有丢失和重复消费的风险出现 - 按消息维度 每次消息消费完向服务端发送offset,是最安全可靠的方式,但是明显会增加与服务端的交互成本,需要结合业务进行取舍
- 按分区粒度 offset本身在服务端就是按分区维度来维护的,按分区维度提交的话只需保证分区内数据一致性即可;需要注意的是在拉取的批次里有多个分区的话,如果按分区维度更新offset需要等该批次所有的数据跑完才能进行下批次数据的拉取,否则可能会因为某个分区消费进度慢没有来得及更新offset导致重复消费;另外,批次内的每个分区还可以使用多线程并行消费,但是需要确保分区的内的数据都消费完才能更新offset,可以用CountDownLatch来控制使线程全部结束后再更新offset
- 按每次拉取的批次粒度 按批次的话需要保证整个批次内数据的一致性,会有一定风险,但是如果批次的大小较小的话应该也能控制得当
也可参照下方的图示:
五、ACK
kafka的ACK指的是生产者发送消息的确认机制,有三个候选值,分别为-1,0,1;
- ack=-1表示消息发送到集群的leader后,然后同步到各个follower成功后才表示消息发送成功,需要注意的是这里的各个follower的个数等于ISR的个数,并不需要真的等完全同步完集群内所有的follower
- ack=0表示生产者发送完消息无论kafka接收成功与否都视为发送成功
- ack=1表示消息发出到leader且磁盘持久化成功表示发送成功,至于是否同步到集群中其他follower并不关注
0和1的取值一般针对单机才有意义
数据一致性策略
kafka默认的ack的值为1,需要注意的是kafka并有做到完全的读写分离,写操作只能发生在leader身上,所以就会涉及到数据同步的问题,数据同步必然会牵扯到数据一致性的问题,下面罗列一下数据一致性的不同策略以及kafka选择的同步策略;
- 强一致性
强一致性即数据发到leader,等所有的follower都同步完成才是为消息发送成功;很显然,强一致性破坏了整个集群的可用性; - 弱一致性
弱一致性即数据发送到leader即认为发送成功,不关注其follower是否同步成功,这样的话数据一致性得不到任何保证 - 最终一致性
最终一致性有两种策略,一是数据发到leader后成功同步到过半的follower即认为同步成功,二是在leader和follower之间加一个可靠的中间件,主机将需要同步的数据扔到中间件,由follower消费数据直至完全消费从而实现最终一致性
kafka如何实现一致性的
kafka的一致性策略
kafka使用的是最终一致性的策略,不过并不是过半通过或是添加中间件来实现而是利用了ISR来实现的,下面就来介绍下kafka特有的一些术语名词,看看kafka是如何通过自己的方式保证集群间消息的一致性的
- ISR(In-Sync Replicas):能够和leader保持一致性的所有follower的副本集合,并且包括leader本身
- AR(Assigned Repllicas):一个分区里面所有的副本
- OSR(Out-Sync Replicas):不能在指定时间(默认10秒)内和leader保持一致性的follower的副本集合
- 公式:AR=ISR+OSR
针对上面的术语解释做以下补充以便理解:kafka在创建topic的时候就指定了分区的个数和副本数,所以leader在此时就已经维护了broker和分区的关系,并且也知道了每个分区对应分配到哪些broker上了,所以根据ISR、OSR和AR集合就能知悉对应的broker列表
ack等于-1
当ack=-1时,kafka通过ISR集合的数量来取代了过半通过的半加1的数量,ISR可以根据集群内部同步数据的实际情况动态改变,并且kafka还支持通过设置ISR集合的个数来确定ACK是否确认成功;kafka还需要保证ISR集合中所有副本的消息进度是一致的;
ack等于1
当ack=1时,即消息发送到leader且持久化成功即表示发送成功且并不保证集群其他follower同步数据成功,所以又衍生出了一堆名词,下面一一介绍
- LEO(LogEndOffset)
我觉得可以理解成功leader中最新消息的offset,之所以拎出来,是因为此时有可能集群中其他follower的消息并没同步到此处 - HW(Hight Watermark)
针对上面的LEO,假设存在其他follower同步消息延迟或者失败的情况,此时集群对外提供的消息肯定不能到LEO的位置,因为其他follower可能还没有该位置的数据,所以此时集群能对外提供消息位置的offset肯定是整个集群同步一致的位置,该位置被称为HW(即高水位) - LW(Low Watermark)
低水位,kafka保存历史消息的最早节点,即该节点的之前的数据kafka中已经不存在
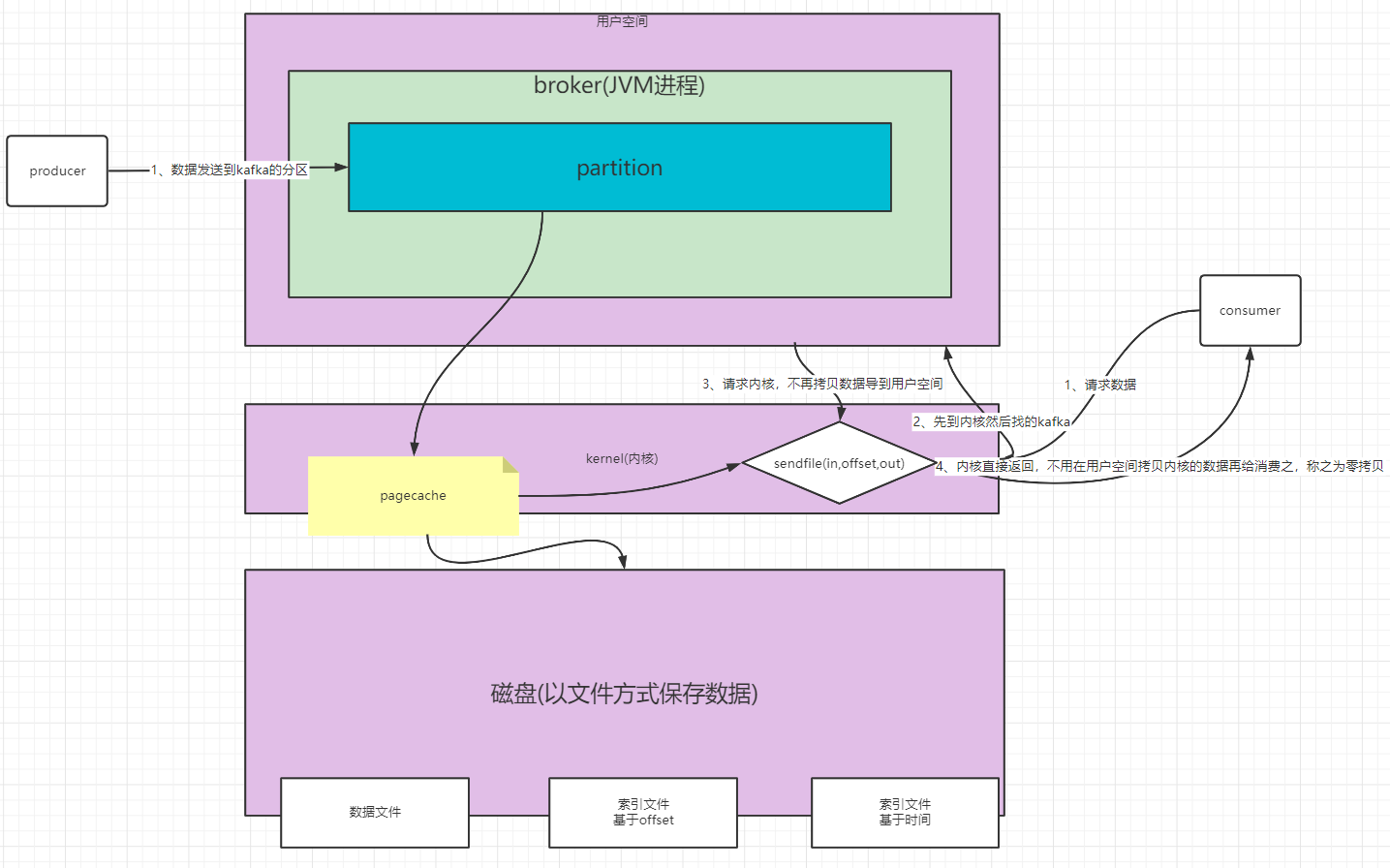
六、kafka为什么快
kafka的读取速度快是因为它的零拷贝机制,即数据不用在磁盘、内核空间、用户空间拷贝传递,而是通过sendFile在内核空间直接返回给消费者;而其写入快是因为其是以文件的形式保存到磁盘,且写入是按顺序的,为了提高查询的速度其在磁盘除了有数据文件还维护了一份索引文件,祥见下图
原文地址:http://www.cnblogs.com/darling2047/p/16789902.html