
前言
- 明确需求, 我们采集网上什么数据内容, 在什么地方
- 分析我们想要高清原图在什么地方有
- 浏览器自带工具: 开发者工具 F12
- 鼠标右键点击 插件 选择 network 刷新网页
- 点击选择 Img 可以直接找到图片地址
- 通过搜索分析, 可以知道, 我们想要图片原图url 就在 图片详情页网页源代码里面
- 发送请求, 模拟浏览器对于 图片目录页面 发送请求
- 获取数据, 获取服务器返回响应数据
- 解析数据, 提取我们想要数据内容
- 发送请求, 模拟浏览器对于 图片详情页url 发送请求
- 获取数据, 获取服务器返回响应数据
- 解析数据, 提取我们想要数据内容
- 保存数据, 把图片保存文本文件夹
import requests
import re
url = f'https://m.bcoderss.com/tag/漫画/page/1/'
# 模拟浏览器 --> headers 请求头
headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36' } # 发送请求 response = requests.get(url=url, headers=headers) <Response [200]> 表示请求成功
提取详情页url地址
img_info = re.findall('<li><a target="_blank" href="(.*?)" alt="(.*?)" title=".*?">', response.text) for循环遍历 把列表里面元素 一个一个提取出来
for img, title in img_info:
html_data = requests.get(url=img, headers=headers).text # 提取原图url地址 img_url = re.findall('<img alt=".*?" title=".*?" src="(.*?)">', html_data)[0] 获取二进制数据
img_content = requests.get(url=img_url).content 替换特殊字符
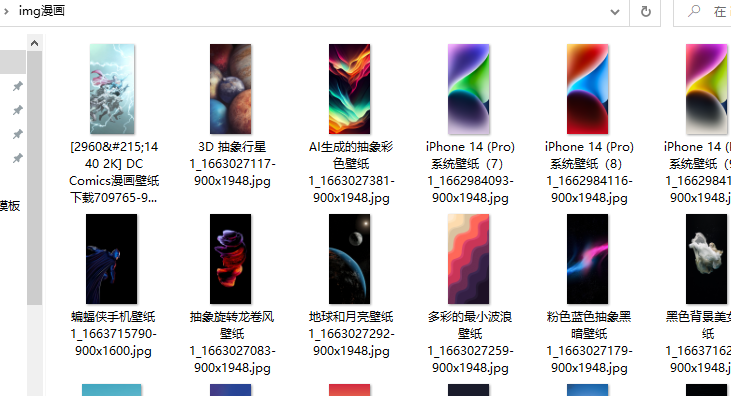
img_title = title + img_url.split('/')[-1] img_title = re.sub(r'[\/:*?:<>|]', '_', img_title) with opythonpen('img漫画\\' + img_title, mode='wb') as f: f.write(img_content) print(img_url, img_title) 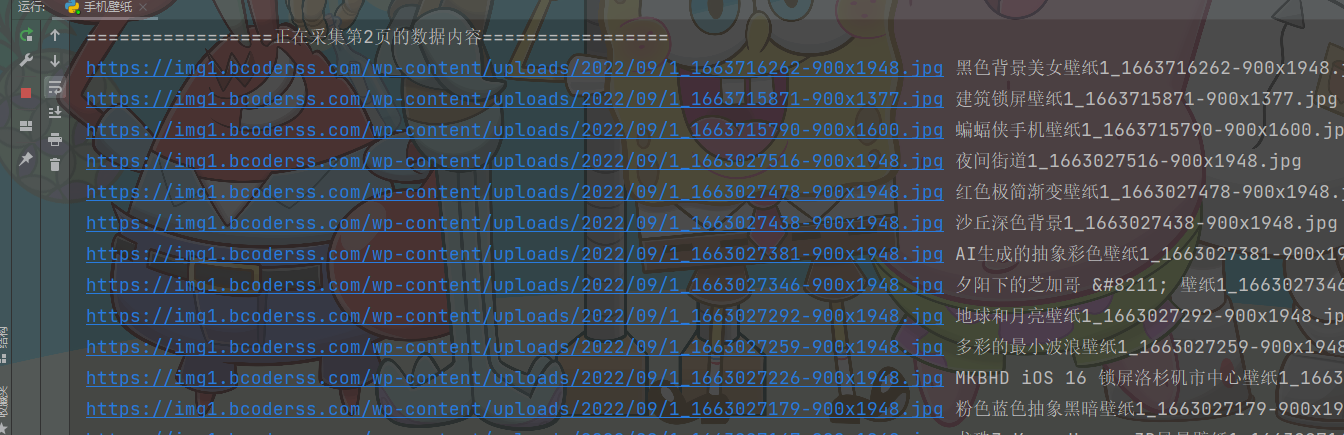
原文地址:http://www.cnblogs.com/qshhl/p/16822491.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性