
1、pom.xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>1.6.0</version>
<exclusions>
<exclusion>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.17.Final</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.2</version>
</dependency>
<dependency><!–Hbase–>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>1.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.4.3</version>
</dependency>
<dependency><!–mysql–>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>1.6.0</version>
</dependency>
pom.xml 若hbase-server 无效则如下导入

2、RDDFromHbase.scala
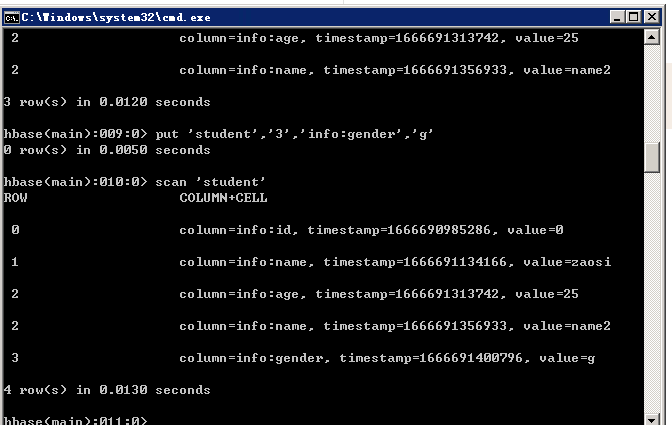
读取hbase表student记录
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.hadoop.hbase.util.Bytes
object RDDFromHbase {
def main(args: Array[String]): Unit = {
var conf=HBaseConfiguration.create()
var sparkConf=new SparkConf().setAppName(“读取hbase中的数据”).setMaster(“local”)
var sc=new SparkContext(sparkConf)
conf.set(“hbase.zookeeper.quorum”, “127.0.0.1”)
conf.set(“hbase.zookeeper.property.clientPort”, “2181”)
//查询表名
conf.set(TableInputFormat.INPUT_TABLE,”student“)
//如果表不存则创建表
/* val admin=new HBaseAdmin(conf);
if(!admin.isTableAvailable(“student”)){
var tableDesc=new HTableDescripter(TableName.valueOf(“student”))
}*/
var RDD=sc.newAPIHadoopRDD(conf,classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
var count=RDD.count()
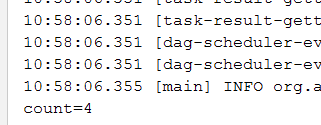
println(“Students RDD Count:…….”+count)
println(s”count=${RDD.count()}”)
RDD.cache()
//遍历输出
RDD.foreach({case (_,result)=>
val key=Bytes.toString(result.getRow)
val name=Bytes.toString(result.getValue(“info”.getBytes,”name”.getBytes))
val gender=Bytes.toString(result.getValue(“info”.getBytes,”gender”.getBytes))
val age=Bytes.toString(result.getValue(“info”.getBytes,”age”.getBytes))
println(“ROW:”+key+” name: “+name+” Gender: “+gender+” Age: “+age)
})
Thread.sleep(100000)//为监控界面,线程休眠
// sc.stop()
}
}

3、RDDToHbase.scala
往hbase表student存记录
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.mapred.JobConf
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.{SparkConf, SparkContext}
object RDDToHbase {
def main(args: Array[String]): Unit = {
var sparkConf=new SparkConf().setAppName(“往hbase中写数据”).setMaster(“local”)
var sc=new SparkContext(sparkConf)
var tableName=”student“
var conf=HBaseConfiguration.create()
val jobConf=new JobConf(conf)
jobConf.setOutputFormat(classOf[TableOutputFormat])
jobConf.set(TableOutputFormat.OUTPUT_TABLE,tableName)
//构建新记录
var dataRDD=sc.makeRDD(Array(“5,hadoop,B,29″,”6,spark,G,46”))
var rdd=dataRDD.map(_.split(“,”)).map(x=>{
var put=new Put(Bytes.toBytes(x(0))) //行键值 put.add方法接收三个参灵敏:列族,列名,数据
put.addColumn(Bytes.toBytes(“info”),Bytes.toBytes(“name”),Bytes.toBytes(x(1))) //info:name列的值
put.addColumn(Bytes.toBytes(“info”),Bytes.toBytes(“gender”),Bytes.toBytes(x(2))) //info:gender列的值
put.addColumn(Bytes.toBytes(“info”),Bytes.toBytes(“age”),Bytes.toBytes(x(3))) //info:age列的值
(new ImmutableBytesWritable,put) //转化成RDD[(ImmutableBytesWritable,put)]类型才能调用saveAsHadoopDataset
})
rdd.saveAsHadoopDataset(jobConf)
}
}

参考https://www.cnblogs.com/saowei/p/15941613.html
原文地址:http://www.cnblogs.com/smallfa/p/16828432.html