
1.算法简介及二分法
1.什么是算法:
算法就是解决问题的有效方法 不是所有的算法都很高效也有不合格的算法
2.算法应用场景:
各种软件、网站推送
成像算法(AI相关)
几乎涵盖了我们日常生活中的方方面面
3.算法工程师要求
待遇非常好 但是要求也非常高
4.算法部门
不是所有的互联网公司都养得起算法部分 只有大型互联网公司才有
算法部门类似于药品研发部分
5.二分法
是算法中最简单的算法 甚至都称不上是算法
"""
二分法使用要求
待查找的数据集必须有序
二分法的缺陷
针对开头结尾的数据 查找效率很低
常见算法的原理以及伪代码
二分法、冒泡、快拍、插入、堆排、桶排、数据结构(链表 约瑟夫问题 如何链表是否成环)
"""
l1 = [12, 21, 32, 43, 56, 76, 87, 98, 123, 321, 453, 565, 678, 754, 812, 987, 1001, 1232]
def get_middle(l1, target_num):
middle_index = len(l1) // 2
if len(l1) == '0':
print('很抱歉您要找的数据没有')
if target_num > l1[middle_index]:
right_l1 = l1[middle_index + 1::]
print(right_l1)
return get_middle(right_l1, target_num)
elif target_num < l1[middle_index]:
left_l1 = l1[:middle_index:]
print(left_l1)
return get_middle(left_l1, target_num)
else:
print('恭喜你,找到了')
get_middle(l1, 1232)
2.三元表达式
原代码:
user_pwd = '123'
if user_pwd == '123':
print('密码输入正确')
else:
print('密码输入错误')
1.代码简单并且只有一行,可以直接在冒号后面编写
user_pwd == '123'
if user_pwd == '123':print('密码输入正确')
else:print('密码输入错误')
2.三元表达式:
语法结构:
数据值1 if 条件 else 数据值2
条件成立则使用数据值1,条件不成立则使用数据值2
user_pwd = '123'
res = '密码输入正确' if user_pwd == '123' else '密码输入错误'
print(res)
"""
当结果是二选一的情况下,使用三元表达式较为简洁,并且不推荐多个三元表达式嵌套
"""
3.列表生成式
1.要求:name_list = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
给列表中所有人名的后面加上_NB的后缀
方法1:for 循环
name_list = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
l1 = []
for i in name_list:
new_i = i + '_NB' # 或new_i = f'{name}_NB'
l1.append(new_i)
print(l1) # ['jason_NB', 'kevin_NB', 'oscar_NB', 'tony_NB', 'jerry_NB']
方法2:列表生成式
list = ['jerry', 'liming', 'jenny', 'danny', 'oscar']
list = [name + '666' for name in list]
print(list) # ['jason_NB', 'kevin_NB', 'oscar_NB', 'tony_NB', 'jerry_NB']
"""
只适用于字符串,其它数据类型不适用
"""
2.给列表中指定的元素(字符串)加上指定的后缀
name_list = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
name_list = [name + 'NB' for name in name_list if name == 'jason']
print(name_list) # ['jasonNB']
3.在name !== 'jerry'的情况下,如果name == 'jason',打印'大佬',其他的打印小赤佬
name_list = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
new_list = ['大佬' if name == 'jason' else '小赤佬' for name in name_list if name != 'jerry']
print(new_list) # ['大佬', '小赤佬', '小赤佬', '小赤佬']
4.字典生成式
1.enumerate()中添加数据类型可以进行for循环,打印这两个数据发现是索引值和数据的元素。
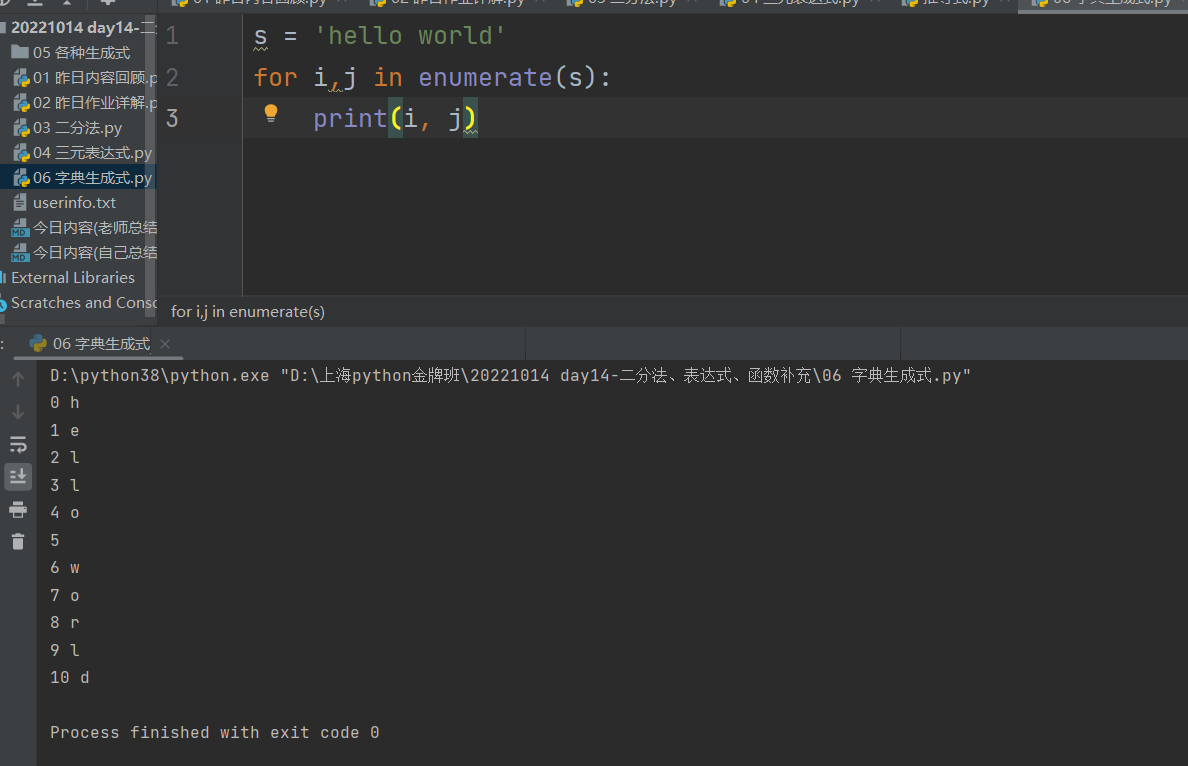
s = 'hello world'
for i,j in enumerate(s):
print(i, j)
l = ['jason', 'danny', 'jenny', 'jerry']
for i,j in enumerate(l):
print(i, j)

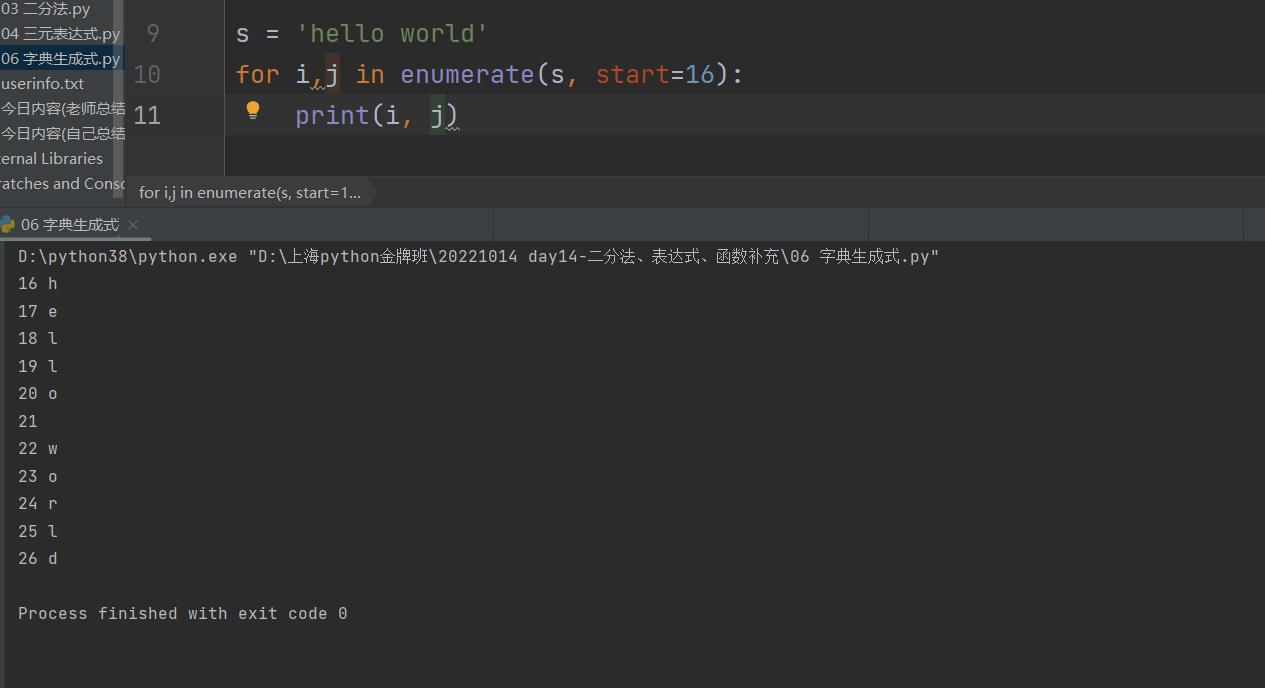
"""也可以指定起始位数"""
s = 'hello world'
for i,j in enumerate(s, start=16):
print(i, j)
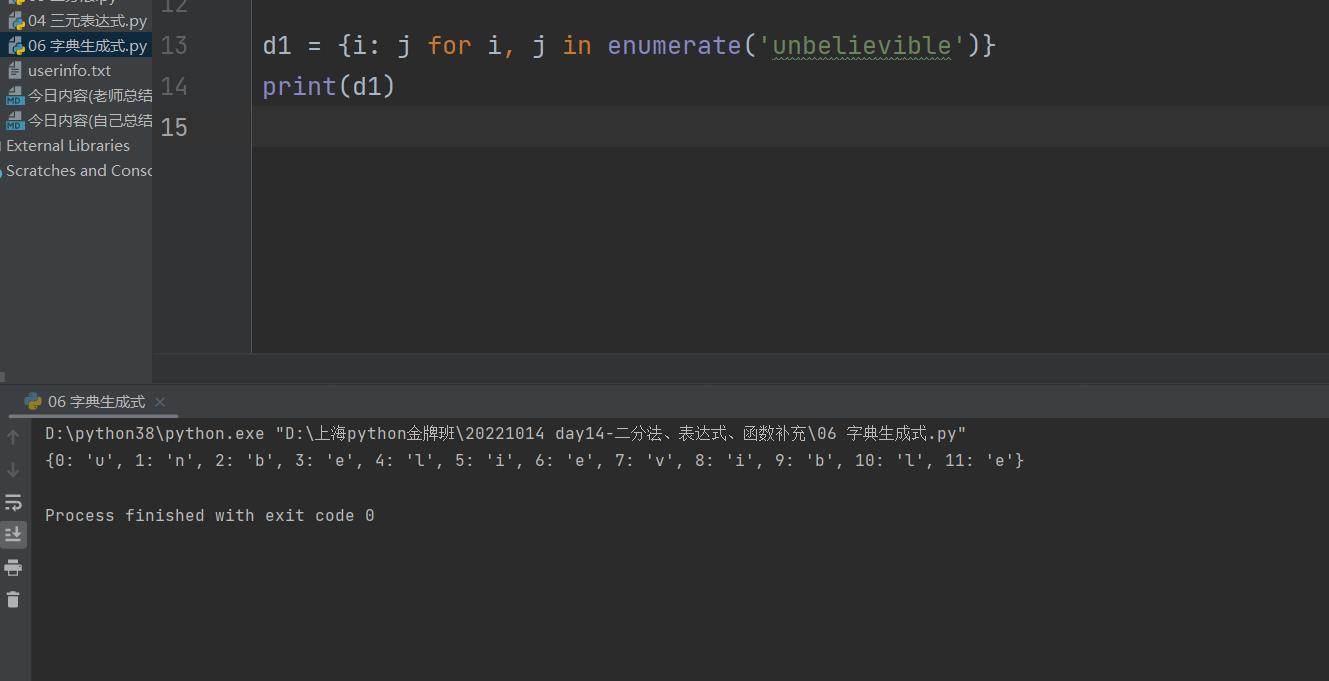
2.也可以放在字典中,构成一个字典
d1 = {i: j for i, j in enumerate('unbelievible')}
print(d1) # {0: 'u', 1: 'n', 2: 'b', 3: 'e', 4: 'l', 5: 'i', 6: 'e', 7: 'v', 8: 'i', 9: 'b', 10: 'l', 11: 'e'}
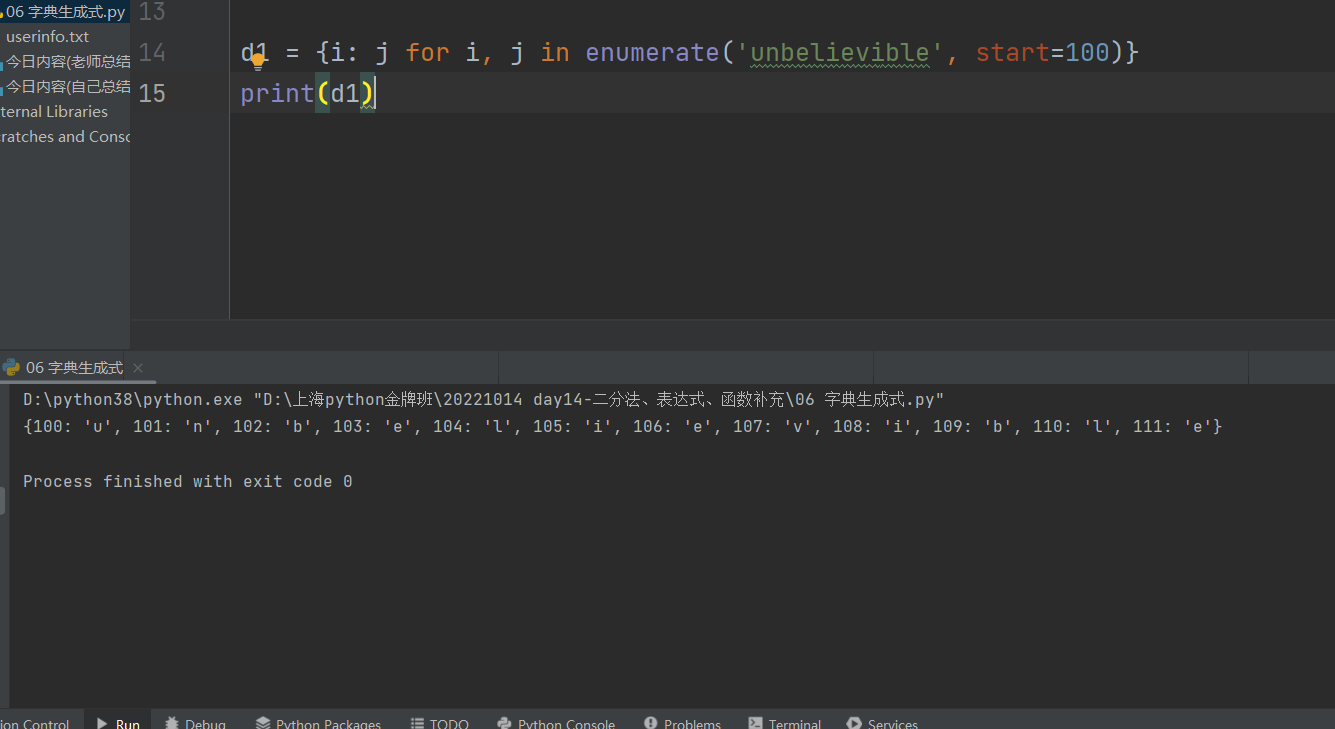
"""
也可以指定起始位数
"""
d1 = {i: j for i, j in enumerate('unbelievible', start=100)}
print(d1)
原文地址:https://www.cnblogs.com/zkz0206/p/16788681.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性