
第三方模块的下载和使用
1,第三方模块就是别人大神们已经写好的模块,功能特别强大。我们如果像使用第三方模块就先要进行下载。下载完成后
才可以在python中直接调用
2.下载方式一:pip工具
pip工具
注意每个解释器都有pip工具 如果我们的电脑上有多个版本的解释器那么我们在使用pip的时候一定要注意到底用的是哪一个 否则极其任意出现使用的是A版本解释器然后用B版本的pip下载模块
为了避免pip冲突 我们在使用的时候可以添加对应的版本号
python27 pip2.7
python36 pip3.6
python38 pip3.8
下载第三方模块的句式
pip install 模块名
下载第三方模块临时切换仓库
pip install 模块名 -i 仓库地址
下载第三方模块指定版本(不指定默认是最新版)
pip install 模块名==版本号 -i 仓库地址
3.pycharm内部快捷下载
进入pycharm设置 settings页面 然后选择 python interpreter 然后选择 添加 搜索您需要的模块下载即可。
4.如果下载速度非常慢,建议更改仓库地址 pip install -i 仓库地址
pip的仓库地址有很多 百度查询即可
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
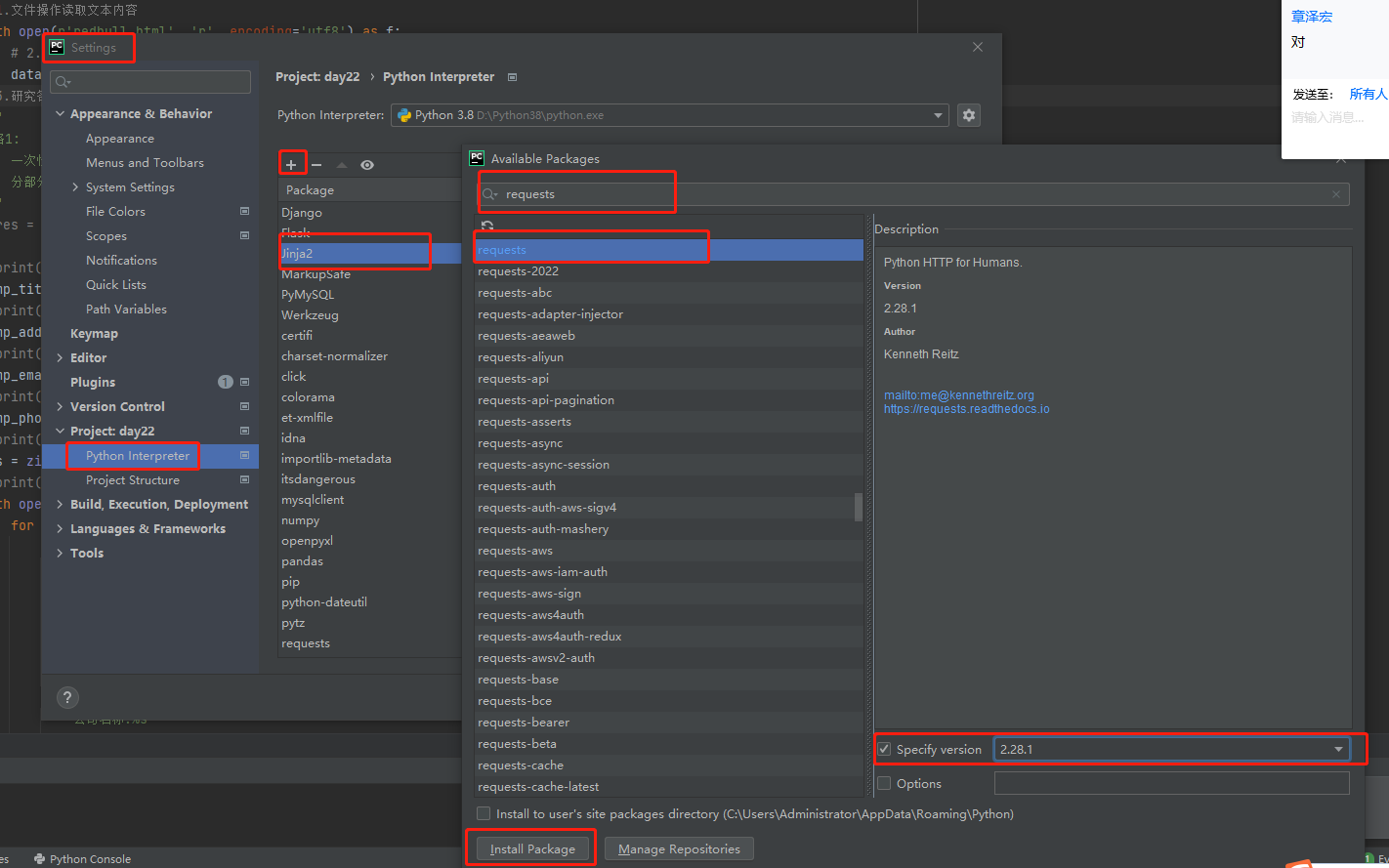
网络爬虫模块之requests模块
requests模块可以帮助我们模拟浏览器发送网络请求,
import requests
res = requests.get('需要查询的网址')
# 相当于我们获取指定网页的页面数据,相当于浏览器地址栏输入网址访问
res.text #获取字符串类型的网页数据
res.content #获取bytes类型的网页数据( 二进制 )
data = res.text
#直接可以用变量名接收到这个网页的全部数据
网络爬虫实战之爬取链接数据
import requests
import re
res = requests.get('https://xinxiang.lianjia.com/ershoufang/muyequ/l3/')
#发送网络请求
data = res.text
#将请求的文件编出字符串类型接收
with open('data.txt', 'w', encoding='utf8') as f:
f.write(data)
house_name = re.findall('data-housecode=".*?" data-is_focus="" data-sl="">(.*?)</a>', data) #通过正则法找到房名
house_place = re.findall('<a href="https://xinxiang.lianjia.com/ershoufang/.*?" target="_blank">(.*?)</a>', data)#通过正则法找到信息
house_info = re.findall('<span class="houseIcon"></span>(.*?)</div></div>', data)
house_money = re.findall('data-price=".*?"><span>(.*?)</span></div></div>', data)
house_money_all = re.findall('</i><span class="">(.*?)</span><i>万</i></div><div', data)
house_dict = zip(house_name, house_place, house_info, house_money, house_money_all)
# print(house_dict)
from openpyxl import Workbook
wb = Workbook()
wb1 = wb.create_sheet('新乡房产',0)
wb1.append(['房名','地址','信息','平方单价','总价'])
for i in house_dict:
wb1.append(i)
wb.save(r'xinxiang_house.xlsx')
自动化办公领域之openpyxl模块
1.excel文件后缀名问题
在 03 版本之前 都是 .xls
在 03 版本之后 都是 .xlsx
2.操作excel表格的第三方模块
openpyxl
pandas
3.如果用openpyxl操作表格
import openpyxl
wb = openpyxl.Workbook()
# 创建一个excel文件 workbook
wb1 = wb.create_sheet('工作薄1')
wb2 = wb.create_sheet('工作薄2')
wb3 = wb.create_sheet('工作薄3', 0) #工作薄名字,位置
wb3.title = '工作薄重命名'
wb.save(r'111.xlsx')
wb3.append(['表头1', '表头2', '表头3'])
wb3.append([1, 2, 3])
wb.save(r'111.xlsx')
# openpyxl主要用于数据的写入 至于后续的表单操作它并不是很擅长 如果想做需要更高级的模块pandas
# excel软件正常可以打开操作的数据集最多10万条 一旦数据集过大 软件操作几乎无效
原文地址:http://www.cnblogs.com/moongodnnn/p/16829805.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性