
1.简介
K-近邻算法(K-Nearest Neighbor, KNN),属于监督学习,是一中基本分类与回归方法。k 近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类, k 近邻法假设给定一个训练数据集,其中的实例类别已定,分类时,对新的实例,根据其 k 个最近邻的训练实例的类别,通过多数表决等方式进行预测。
2.基本要素
①K值的选择
②距离量度
(1)欧氏距离
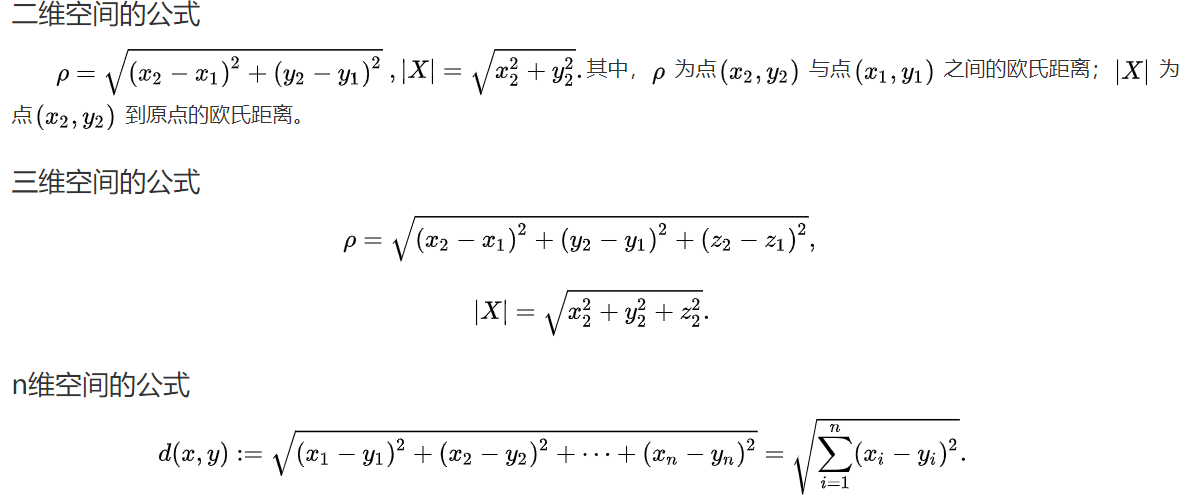
(2)曼哈顿距离

③分类决策规则
3.实现knn算法的代码实现
from numpy import *
import operator
#训练样本集以及对应的类别
def createDateSet():
group = array([[3,53],[2,48],[1,49],[101,10],[99,5],[98,2]])
labels = [‘西苑’,’西苑’,’西苑’,’万人’,’万人’,’万人’]
return group,labels
def classify(inX, dataSet, labels, k):
#dataSetSize是训练样本集数量
dataSetSize = dataSet.shape[0]
#距离计算——欧式距离公式
#tile函数,把inX变成能与dataSet相减的二维数组
diffMat = tile(inX, (dataSetSize, 1)) – dataSet
sqDiffMat = diffMat ** 2
#axis=1是列相加求和,即得到(x1-x2)^2+(y1-y2)^2的值
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances ** 0.5
#按照距离递增次序排序,返回下标
sortedDistIndicies = distances.argsort()
#选择距离最小的k个点
classCount = {}
for i in range(k):
voteILabel = labels[sortedDistIndicies[i]]
classCount[voteILabel] = classCount.get(voteILabel,0) + 1
#按照字典里的关键字的值排序,reverse=True降序排序
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
#返回类别最多的标签
return sortedClassCount[0][0]
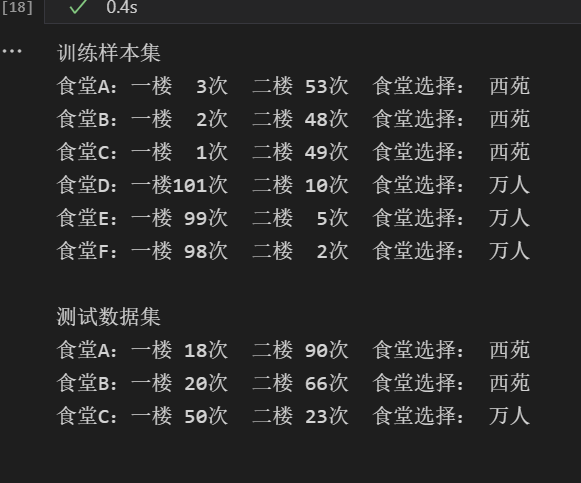
测试算法:
i = 0
print(“训练样本集”)
group, labels = createDateSet()
for item in group:
print(‘食堂%c:一楼%3d次 二楼%3d次 食堂选择: %s’%(chr(ord(‘A’)+i),item[0],item[1],labels[i]))
i += 1
print(“\n测试数据集”)
myTests = array([[18,90],[20,66],[50,23]])
myLabels = []
for i in range(3):
myLabels.append(classify(myTests[i], group, labels, 3))
print(‘食堂%c:一楼%3d次 二楼%3d次 食堂选择: %s’%(chr(ord(‘A’)+i),myTests[i][0],myTests[i][1],myLabels[i]))
测试结果:
原文地址:http://www.cnblogs.com/Moonee/p/16830658.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性