
导入资源包
import requests
import bs4
获取链接
url = 'https://www.17k.com/top/refactor/top100/18_popularityListScore/18_popularityListScore_finishBook_top_100_pc.html?TabIndex=1&typeIndex=0'
伪装用户
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
发送网络请求
req=requests.get(url=url,headers=headers)
将网络请求的响应由二进制转换为可读模式
req.encoding='utf-8'
将爬取到的内容进行装饰
soup=bs4.BeautifulSoup(req.text,"html.parser")
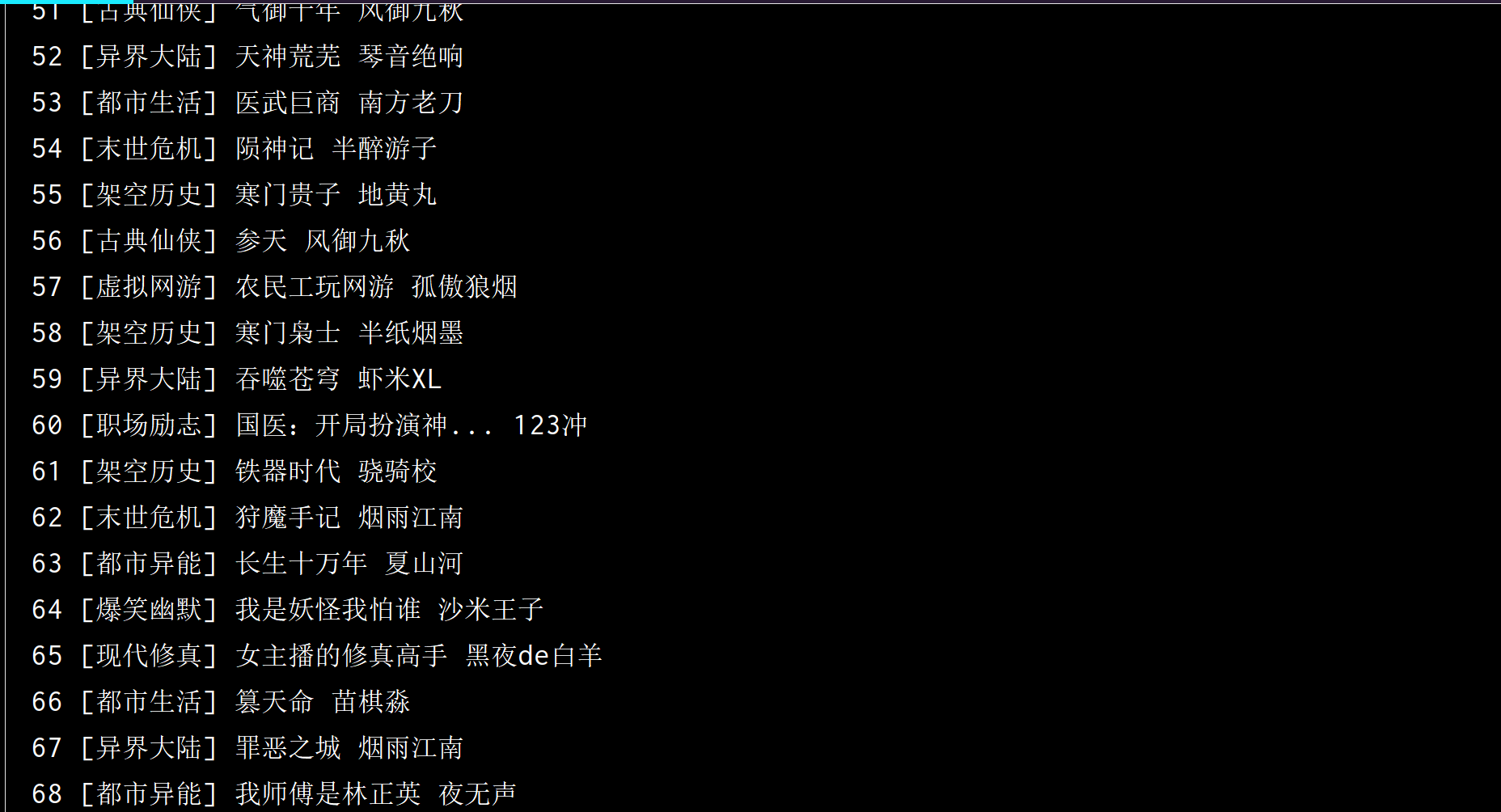
将小说的序号,分类,名称,作者分别爬取出来
div=soup.find_all('div',attrs={'class':'BOX'})[1]
tr_list=div.find_all('tr')
try:
for item in tr_list[1:]:
id=item.find('td').text
sign=item.find('a').text
book=item.find('a',attrs={'class':'red'}).text
author=item.find_all('a')[3].text
print(id,sign,book,author)
except Exception:
print('异常')
原文地址:http://www.cnblogs.com/JK8395/p/16831091.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性