
分词:jieba.cut
words = jieba.cut("我来到北京大学",cut_all=True)
print('全模式:'+'/'.join([w for w in words])) #全模式
words = jieba.cut("我来到北京大学",cut_all=False)
print('精确模式:'+'/'.join([w for w in words])) #精确模式,默认
words = jieba.cut_for_search("小明毕业于北京大学,后在美国哈佛大学深造")
print('/'.join([w for w in words])) #搜索引擎模式,在精确模式的基础上,对长词在此划分
全模式:我/来到/北京/北京大学/大学
精确模式:我/来到/北京大学
请练习添加自定义词典
词性:jieba.posseg
import jieba.posseg as pg
for word, flag in pg.cut("你想去学校填写学生寒暑假住校申请表吗?"):
print('%s %s' % (word, flag))
‘你/学校/填写/学生/寒暑假/住校/申请表’
分词引入停用词
import jieba
import pandas as pd
import numpy as np
paths = '中英文停用词.xlsx'
dfs = pd.read_excel(paths,dtype=str)
stopwords = ['想','去','吗','?']
words = jieba.cut("你想去学校填写学生寒暑假住校申请表吗?")
'/'.join([w for w in words if (w not in stopwords)])#此处’/'表示换行
‘你/学校/填写/学生/寒暑假/住校/申请表’
txt转dataframe函数
import random
import jieba.posseg as pg
import pandas as pd
import numpy as np
def generatorInfo(file_name):
# 读取文本文件
with open(file_name, encoding='utf-8') as file:
line_list = [k.strip() for k in file.readlines()]
data = []
for k in random.sample(line_list,1000):
t = k.split(maxsplit=1)
#data_label_list.append(t[0])
#data_content_list.append(t[1])
data.append([t[0],' '.join([w for w,flag in pg.cut(t[1]) if (w not in dfs['stopwords']) and (w !=' ') and (len(w)>=2)])])
return data
file_name = 'cnews.train.txt'
df = pd.DataFrame(np.array(generatorInfo(file_name)),columns=['类别','分词'])
path = '训练集分词结果(随机选取1000个样本).xlsx'
df.to_excel(path,index=False)
df

词云图:wordcloud
%pylab inline
import matplotlib.pyplot as plt
from wordcloud import WordCloud
text = ' '.join(list(df['分词']))
wcloud = WordCloud(
font_path='simsun.ttc', #字体路径
background_color='white', #指定背景颜色
max_words=500, #词云显示最大词数
max_font_size=150, #指定最大字号
#mask = mask #背景图片
)
wcloud = wcloud.generate(text) #生成词云
plt.imshow(wcloud)
plt.axis('off')
plt.show()

提取关键词:jieba.analyse.extract_tags
import jieba.analyse
import pandas as pd
import numpy as np
path = '训练集分词结果(随机选取1000个样本).xlsx'
df = pd.read_excel(path,dtype=str)
s = ' '.join(list(df['分词']))
for w,x in jieba.analyse.extract_tags(s,withWeight=True):
print('%s %s' % (w,x))

请练习基于TextRank算法抽取关键词
import jieba.analyse
import pandas as pd
import numpy as np
path = '训练集分词结果(随机选取1000个样本).xlsx'
df = pd.read_excel(path,dtype=str)
tag = list(set(list(df['类别'])))
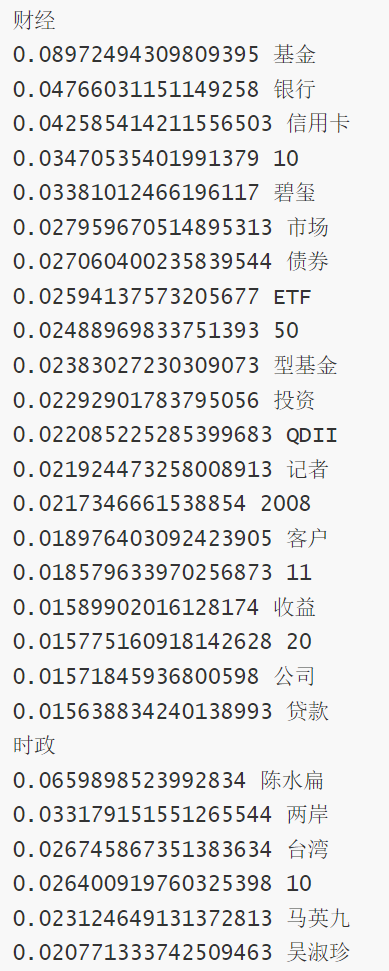
for t in tag:
s = ' '.join(list(df[df['类别']==t]['分词']))
print(t)
for w,x in jieba.analyse.extract_tags(s,withWeight=True):
print('%s %s' % (x,w))
构建词向量
构建词向量简单的有两种分别是TfidfTransformer和 CountVectorizer
#CountVectorizer会将文本中的词语转换为词频矩阵
from sklearn.feature_extraction.text import CountVectorizer
path = '训练集分词结果(随机选取1000个样本).xlsx'
df = pd.read_excel(path,dtype=str)
corpus = df['分词']
#vectorizer = CountVectorizer(max_features=5000)
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(X)

from sklearn.feature_extraction.text import TfidfTransformer
import datetime
starttime = datetime.datetime.now()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
word = vectorizer.get_feature_names()
weight = tfidf.toarray()
print(weight)

词语分类:人工vsKmeans
from sklearn.cluster import KMeans
starttime = datetime.datetime.now()
path = '训练集分词结果(随机选取1000个样本).xlsx'
df = pd.read_excel(path,dtype=str)
corpus = df['分词']
kmeans=KMeans(n_clusters=10) #n_clusters:number of cluster
kmeans.fit(weight)
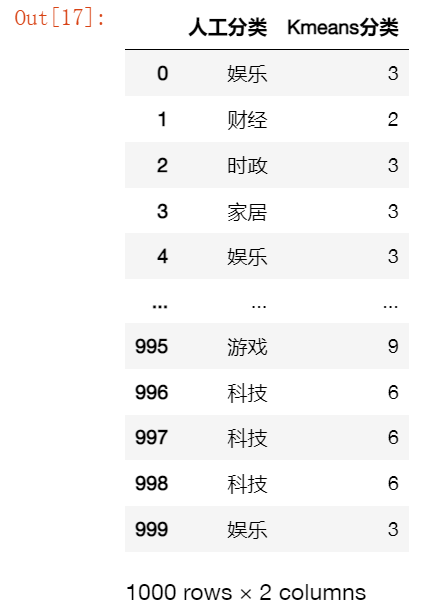
res = [list(df['类别']),list(kmeans.labels_)]
df_res = pd.DataFrame(np.array(res).T,columns=['人工分类','Kmeans分类'])
path_res = 'Kmeans自动分类结果.xlsx'
df_res.to_excel(path_res,index=False)
df_res
path = 'Kmeans自动分类结果.xlsx'
df = pd.read_excel(path,dtype=str)
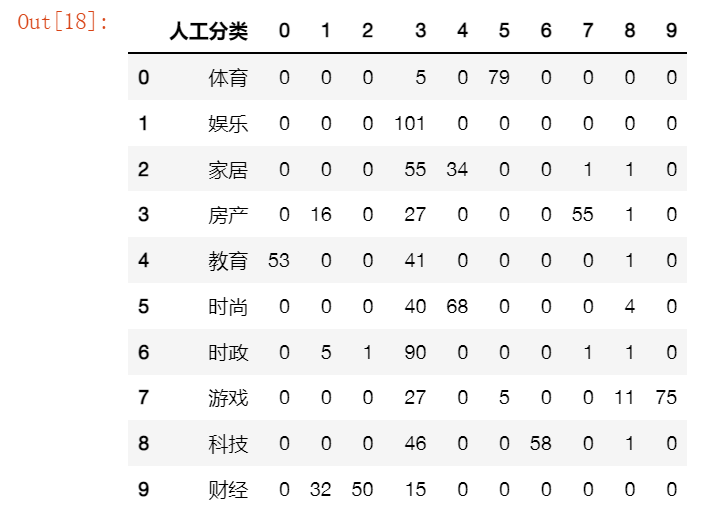
df['计数'] = [1 for m in range(len(df['人工分类']))]
df1 = pd.pivot_table(df, index=['人工分类'], columns=['Kmeans分类'], values=['计数'], aggfunc=np.sum, fill_value=0)
co = ['人工分类']
co.extend(list(df1['计数'].columns))
df1 = df1.reset_index()
df2 = pd.DataFrame((np.array(df1)),columns=co)
path_res = '人工与Kmeans分类结果对照.xlsx'
df2.to_excel(path_res,index=False)
df2
import random
def is_contain_chinese(check_str):
for ch in check_str:
if u'\u4e00' <= ch <= u'\u9fff':
return 1
return 0
def generatorInfo(file_name):
"""
batch_size:生成数据的batch size
seq_length:输入文字序列长度
num_classes:文本的类别数
file_name:读取文件的路径
"""
# 读取文本文件
with open(file_name, encoding='utf-8') as file:
line_list = [k.strip() for k in file.readlines()]
#data_label_list = [] # 创建数据标签文件
#data_content_list = [] # 创建数据文本文件
data = []
for k in random.sample(line_list,1000):
t = k.split(maxsplit=1)
#data_label_list.append(t[0])
#data_content_list.append(t[1])
data.append([t[0],' '.join([w for w,flag in jieba.posseg.cut(t[1]) if (w not in dfs['stopwords']) and (w !=' ') and (flag not in ["nr","ns","nt","nz","m","f","ul","l","r","t"]) and (len(w)>=2)])])
return data
#导入中文停用词表
paths = '中英文停用词.xlsx'
dfs = pd.read_excel(paths,dtype=str)
file_name = 'cnews.train.txt'
df = pd.DataFrame(np.array(generatorInfo(file_name)),columns=['类别','分词'])
df

汇总
import random
import jieba
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfTransformer
def is_contain_chinese(check_str):
for ch in check_str:
if u'\u4e00' <= ch <= u'\u9fff':
return 1
return 0
def generatorInfo(file_name):
"""
batch_size:生成数据的batch size
seq_length:输入文字序列长度
num_classes:文本的类别数
file_name:读取文件的路径
"""
# 读取文本文件
with open(file_name, encoding='utf-8') as file:
line_list = [k.strip() for k in file.readlines()]
#data_label_list = [] # 创建数据标签文件
#data_content_list = [] # 创建数据文本文件
data = []
for k in random.sample(line_list,1000):
t = k.split(maxsplit=1)
#data_label_list.append(t[0])
#data_content_list.append(t[1])
data.append([t[0],' '.join([w for w,flag in jieba.posseg.cut(t[1]) if (w not in dfs['stopwords']) and (w !=' ') and (flag not in ["nr","ns","nt","nz","m","f","ul","l","r","t"]) and (len(w)>=2)])])
return data
#导入中文停用词表
paths = '中英文停用词.xlsx'
dfs = pd.read_excel(paths,dtype=str)
file_name = 'cnews.train.txt'
df = pd.DataFrame(np.array(generatorInfo(file_name)),columns=['类别','分词'])
#统计词频
corpus = df['分词'] #语料中的单词以空格隔开
#vectorizer = CountVectorizer(max_features=5000)
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
#文本向量化
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
word = vectorizer.get_feature_names()
weight = tfidf.toarray()
kmeans=KMeans(n_clusters=10) #n_clusters:number of cluster
kmeans.fit(weight)
res = [list(df['类别']),list(kmeans.labels_)]
df_res = pd.DataFrame(np.array(res).T,columns=['人工分类','Kmeans分类'])
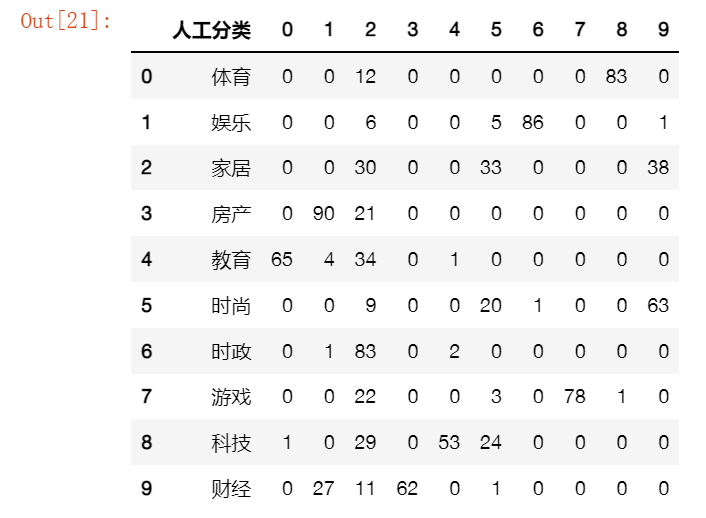
df_res['计数'] = [1 for m in range(len(df_res['人工分类']))]
df1 = pd.pivot_table(df_res, index=['人工分类'], columns=['Kmeans分类'], values=['计数'], aggfunc=np.sum, fill_value=0)
co = ['人工分类']
co.extend(list(df1['计数'].columns))
df1 = df1.reset_index()
df2 = pd.DataFrame((np.array(df1)),columns=co)
df2
df['Kmeans分类'] = df_res['Kmeans分类']
df

原文地址:http://www.cnblogs.com/ranxi169/p/16833336.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性