
【ACMMM 2022】Learning Hierarchical Dynamics with Spatial Adjacency for Image Enhancement
代码:https://github.com/DongLiangSXU/HDM
该论文的研究动机:近年来动态网络非常流行,因此作者引入了 channel-spatial-level,structure-level 和 region-level 的动态机制用于图像增强。具体来说:
- channel-spatial-level:使用了 CBAM 注意力机制
- structure-level:使用了 Deformable convolution
- region-level:使用了 CVPR2021的Dynamic Region-Aware Convolution(DRConv)的思想,把图像分割为多个区域,然后不同区域使用不同的卷积核处理。不同的是,在进行区域分割时,使用 暗通道 特征,直接用域值分割来得到5个区域。
CBAM 和 Deformable conv 比较经典了,这里不再回顾,只简单回顾下 DRConv,其结构如下图所示,使用卷积生成m个feature map,每个位置就有m个数值,直接用 argmax() 即可以得到最大值的index,这样就可以分割为m个区域。接着使用动态卷积的思路,就可以对各个区域使用不同的卷积核处理(详细可以参考以前的解析)

因为 argmax 不可以反向传播,还需要使用 gamble-softmax 神器来优化。为了避免这个问题,这个论文使用了暗通道( Dark channel prior, DCP)来直接分割得到各个区域。感兴趣的可以阅读何恺明大神CVPR2009的Single Image Haze Removal Using Dark Channel Prior。统计发现,对于无模糊的自然图像,RGB各个通道的最小值形成一个暗通道,近似为零。
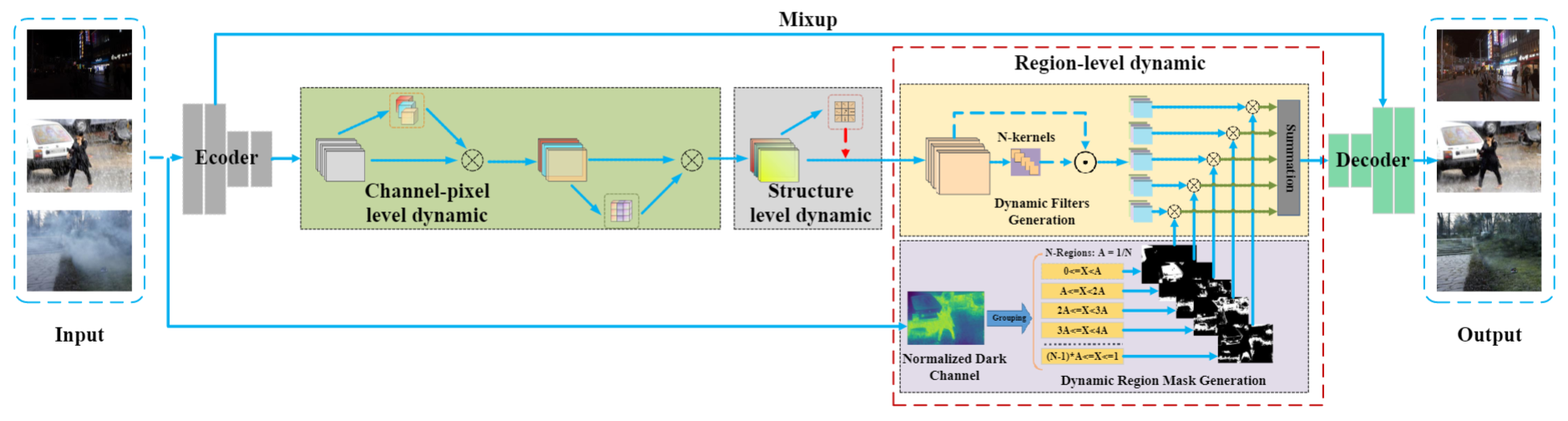
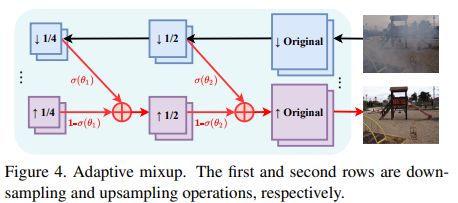
该方法的整体架构如上图所示,总体是 UNet 结构,只不过中间串行了上述三个动态模块。同时,skip connection 还使用了Mixup。不过,和分类中使用的 Mixup 有一定区别,该思想来自于论文:Contrastive Learning for Compact Single Image Dehazing,如下图所示,UNet 的skip connection 一般是直接相加,但 Mixup 的思想是加入一个参数来自适应的调节特征输入的权重。
实验方面,作者在图像去雾、图像去雨、弱光增强三个任务上进行了实验,均取得了非常好的性能。这里提一下 ablation study,作者调节了三个动态模块的顺序,发现论文中的顺序是最合理的,解释是:从像素到语义的安排会更合理 (the importance of local to global philosophy)。此外,作者还研究了使用 暗通道 和 DRConv 的区别。
其它实验可以参考作者论文,这里不再多说。
原文地址:http://www.cnblogs.com/gaopursuit/p/16837533.html