
新建core
命令添加
使用命令比较简单
~$ bin/solr create -c mytest[core名称]
这样就添加完了。Core Admin就可以看到了。
手动添加
手动添加相对复杂一些,需要提前创建目录,然后通过可视化界面添加
1、到server\solr(相对于solr根目录的路径,下同)目录下,先把要创建的core目录提前创建,复制configsets_default下的conf到core目录。
~$ cd solr-8.11.2
~$ mkdir server/solr/mytest
~$ cp -r server/solr/configsets/_default/conf server/solr/mytest/
2、点击core的部分,因为限制没有core(核)会出现添加页面。按照图示添加 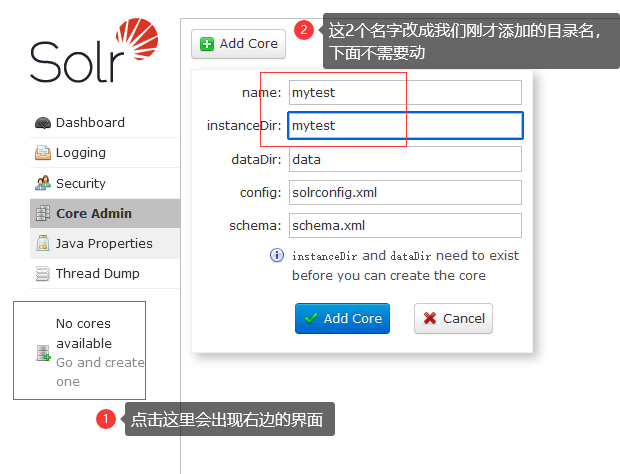
添加完成,点击“Core Admin”可以看到添加的核 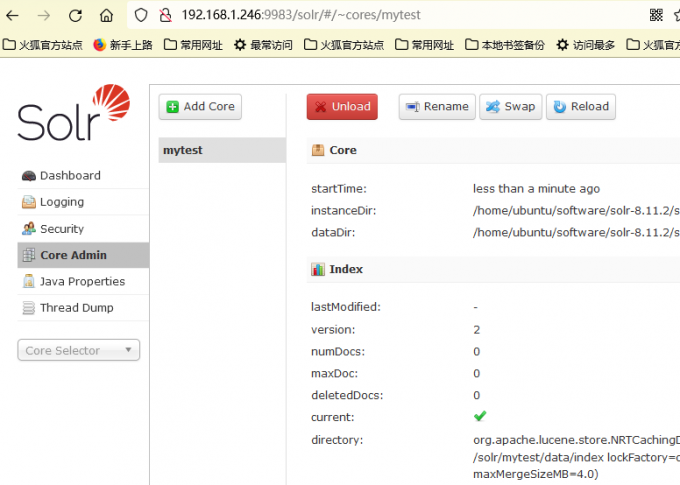
配置solr字段
添加字段有2种方法,可以通过web页面添加,也可以直接修改schema文件添加。
可视化界面增加
通过浏览器的Schema菜单添加 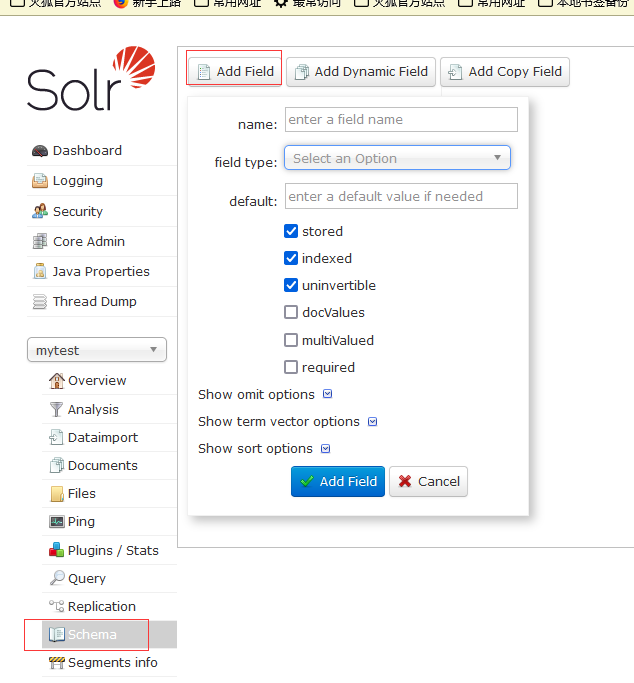
添加字段名称,选中字段类型,添加添加字段即可。
| 属性 | 说明 | 取值 | 默认值 |
|---|---|---|---|
| stored | 是否存储,一个字段是否被存储,取决于你是否想在solr的查询结果中得到它,也就是说你是否想在查询结果中看到它,它将会消耗cpu和io和磁盘空间等资源。 | true/false | true |
| indexed | 字段是否创建索引,索引的字段是在搜索的时候可以用它来查询或排序,在lucene中,被索引的字段将会建立倒排表。 | true/false | true |
| uninvertible | 如果为 true,则表示一个 indexed=“true” docValues=”false” 字段在查询时可以用“un-inverted”构建大内存数据结构以代替 DocValues。 出于历史原因,默认为 true,但强烈建议用户将其设置 false 以保持稳定性,并据需要使用 docValues=”true”。 | true/false | true |
| docValues | 字段的值是否放在面向列的 DocValues 结构中 | true/false | false |
| multiValued | 设置为true表示此字段可以存储多个值,意思是这个字段在一个文档中可以存储多个值的内容。 | true/false | false |
| required | 是否必须。如果为 true,则 Solr 拒绝任何添加没有此字段的文档。 | true/false | false |
| default | 字段的默认值,经常用在字段是必须的,但是有时候又无法提供的情况,solr就会用默认值替代。如: <field name="recordTime" type="date" indexed="true" stored="true" required="true" default="NOW+8HOUR"/> 标示recordTime如果没有提供,用当前的时间+8个小时作为recordTime的时间,加8小时是因为solr默认时区是0时区,按照中国北京时间(东8区)算,需要加上8个小时。 |
类型高级属性
1.docValue
在solr的schema定义中,基本的long、int、double、float类型设置docValue,如下:
<fieldType name="long" class="solr.TrieLongField" docValues="true" precisionStep="0" positionIncrementGap="0"/>`
当然也可以在字段里面直接定义:
<field name="_root_" type="string" indexed="true" stored="false" docValues="false" />
solr说明: 如果此字段应包含doc值,则为true。 Doc值为用于分面(faceting),分组,排序和函数查询。 虽然不是required,doc值会使索引加载更快,更多 NRT友好和更高内存利用率。 但他们有一些 限制:它们目前只受StrField,UUIDField支持 和所有Trie *字段,并且根据字段类型,它们可能要求字段为单值,是必需的或具有默认值 。 docValue值存在正排索引中,只所以在排序的时候效果更好,是因为docValue是按照列存储的,又存在正排索引中,所以可以通过文档ID快速找到它。
说明下: lucene的倒排索引是:Term(词)-> 文档ID 这样根据类似Hash算法,通过词可以迅速找到文档ID,然后把相关字段取处理。但是也有不利的方面就是如果要进行分组或排序的时候,会遍历取出所有文档的字段,然后在内存中根据排序字段进行排序,非常耗时和占用内存。
设置docValue就构建了正排索引,即文档ID->docValue字段,而且docValue字段又是排好序的,按照列存储的。只是简单说明。 设置docValue在lucene其实是增加一个字段,所以占存储,影响建索引效率。
useDocValuesAsStored:如果这一项设置为true则标示所有docValue为true的字段将被存储,即使它的stored=false。
2.omitNorms
solr对这个属性解释的有点拗口,自己理解下,就是如果这个为true,则在索引中不存在这个字段的长度属性。这在给文档打分的时候用的到。
举个例子,一个词语,在两篇文章中,一般认为段的文章比长的文章是不是要更加符合查询的需要(因为这个词在两篇文章中权重不一样,比如在100个词的文章中,这个词权重为0.01; 在100个词的文章中,这个词权重为0.001),如果是,则需要用长度来加强文档打分的策略,这就是这个属性的作用。Norm 在Lucene中是按照浮点数的形式,只占用一个字节的方式存储的。
忽略情况: 1、如果你的doc的字段的内容长度大小比较一致,则可以忽略。 2、如果在查询结果中,字段内容的长度对你的结果匹配无影响忽略。 3、需要节省空间,提高建索引和查询的性能。
使用情况: 1、字段内容长度影响了文档的打分,则需要使用。
在solr中,默认的时间、string或数字类型,这个属性为true。
3.termVectors
在solr中,我们通过查询的内容的词向量和文档中的此向量之间的夹角来求相关性,给文档相关性打分(词向量比较复杂,回头单独写一篇文章来阐述)。 solr中有个MoreLikeThis 的功能,现在很多电商的查询里面的找类似就是这个功能,solr利用term Vectors来计算相关度,通常是是利用存储在索引中查询信息计算的,设置termVectors为true,则可以在建索引的时候计算term Vector信息,且保存在索引中。
这对大数据量的索引来说,影响很大。如果你重度使用MoreLikeThis 的功能,可以开启这个属性。
4.termPositions和termOffset、termPayLoads
这三项和前面的termVectors关系很大,是在前面一项为true的情况下,这三项才有效果。分别是指词在文档中所处位置、词的偏移量、词在词向量中比重信息(词在文章中重要性?不确定此处)。 可以加速高亮功能和其他辅助功能,当然如果设置为true也会增加索引的大小和降低建索引的速度。
omitTermFreqAndPositions: 如果设置为true,则忽略词出现的频次、位置和在文章中这个字段的比重信息。在不需要这些信息时候可以改进索引性能。减少索引的大小。依赖这个词的位置的查询将默默地显示找不到信息,除了textField字段类型,其他字段类型默认设置为true。
omitPositions : 和omitTermFreqAndPositions 类似仅仅忽略位置。
5.precisionStep 和positionIncrementGap
precisionStep 这可能是这几个属性里面最难理解的属性了,不过这个属性用在数字或时间字段的范围查询或者排序的时候。通过字面理解就是精度步长,简单来说就是通过保存数据的多个精度来加快数据的范围定位。
举个例子,比如你在电商网站查询价格范围在1000 到10000之间的所有手机,这里面就用到了范围搜索。如果价格值的范围很小,用precisionStep 没多大意义,只有大量数据的时候使用它才可能起到加快搜索的作用。 假设手机价格如下定义: <field name="phone_price" type="tint" indexed="true" stored="true" / 和 <fieldType name="tint" class="solr.TrieIntField"precisionStep="8"positionIncrementGap="0"/> 首先说明在solr中(在lucene中),一个数字类型(Date类型实际是按照Long来存储的)最高精度是其本身,这也称为基数据。 solr对于一个具有precisionStep非0的值保存了多个不同精度的term。 按照Solr In Action举例如图:
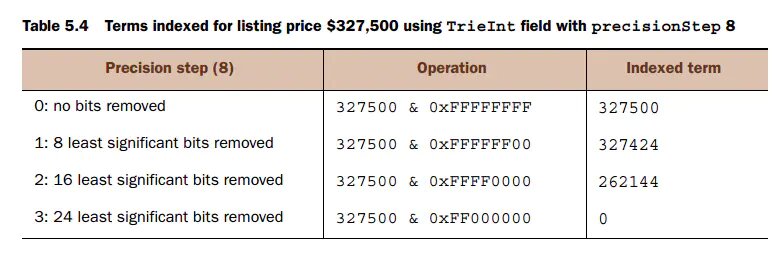
图来自Solr In Action
tint四个字节,按照precisionStep=8 ,则说明精度按照8位切分,4个字节一共32位,刚好保存四个值。
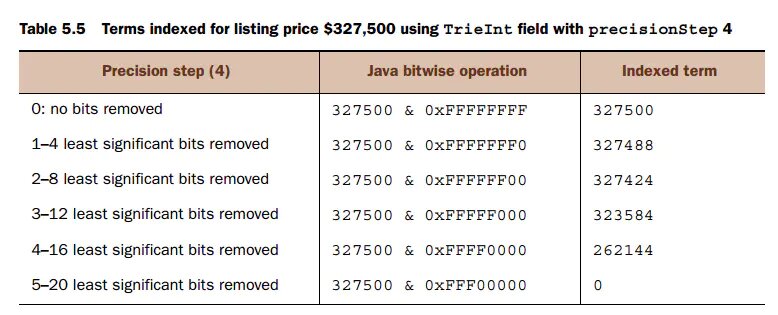
图来自Solr In Action
通过这两个图的对比,更小的步长,则同一个值需要保存更多的term, 当然范围搜索也更加精确,查找速度更快,但是也同样会增大索引的大小。
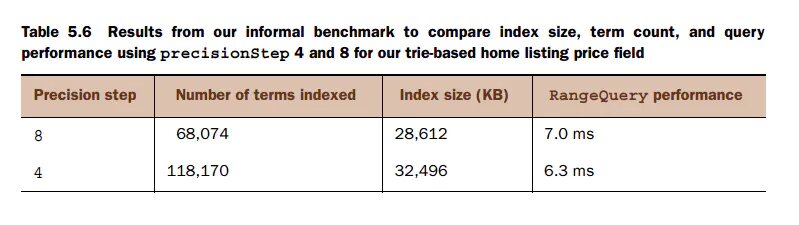
图来自Solr In Action
同样是50000个价格随机数,在不同的precisionStep下的索引大小和范围查询速度的快慢。 positionIncrementGap 它是和multiValued一起使用的,标示多值之间虚拟空白的数量。 举个网上的例子:
title1: ab cd title2: xy zz 如果positionIncrementGap=0,那么这四个term的位置为0,1,2,3。如果检索”cd xy”那么能够找到,如果你不想让它找到,那么就需要调整positionIncrementGap值。如100,那么这是位置为0,1,100,101。这样就不能匹配了。
6.sortMissingFirst 和sortMissingLast
这两个比较好理解,是文档在排序的时候,如果排序字段的值缺失,那么是排在前面还是排在后面。
修改managed-schema
也可以直接修改managed-schema文件,在core的conf下的managed-schema文件中增加字段配置
<!-- 自定义的字段,id已经存在不需要设置 -->
<field name="dd" type="string" indexed="true" stored="true"/>
<field name="age" type="pint" indexed="true" stored="true" />
<field name="description" type="text_ik" indexed="true" stored="true" />
<field name="createTime" type="pdate" indexed="true" stored="true" />
<field name="updateTime" type="pdate" indexed="true" stored="true" />
添加后到“Core Admin”中刷新一下核即可  就添加上了。
就添加上了。
添加数据
现在core已经建好了,但是里面还没有数据,这里我们使用json添加以便快速演示(支持 JSON,、CSV、XML等格式),一般生产环境下都是从数据库访问。
准备json数据:
{"id": "11","age": 40,"name": "李白","description": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"},
{"id": "12","age": 31,"name": "杜甫","description": "唐代伟大的现实主义文学作家,唐诗思想艺术的集大成者"}
找到该core的Documents菜单,选择文档类型未JSON,把刚才准备的数据粘贴进来,确认无误提交。 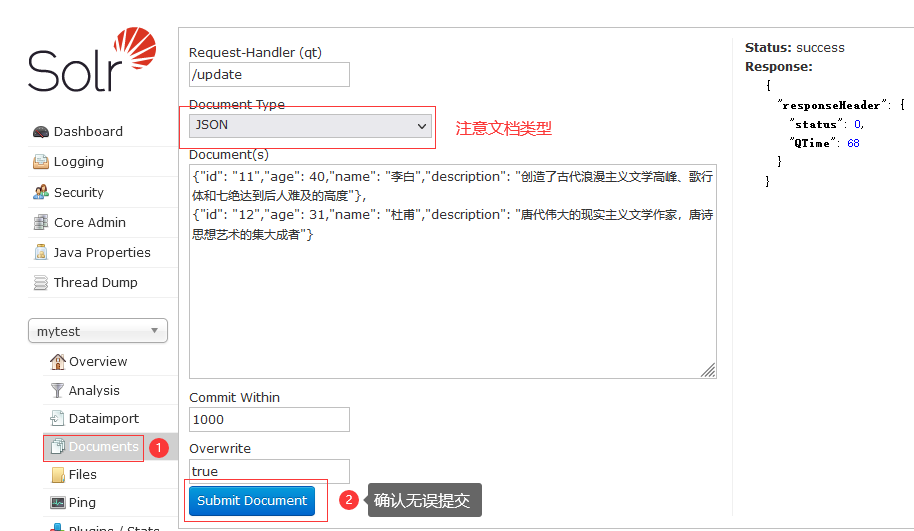
查询
刚才已经添加了数据,我们现在验证一下查询一下
点击Query菜单,然后直接点击Execute Query按钮查询可以看到刚才添加的2条数据已经能查询到了。
原文地址:http://www.cnblogs.com/donggongai/p/16844601.html