
Hadoop YARN
直接源于MRv1在几个方面的缺陷,扩展性受限、单点故障、难以支持MR之外的计算。多计算框架各自为战,数据共享困难。
MR:离线计算框架,Storm:实时计算框架,Spark内存计算框架。
Hadoop 2.0有HDFS、MapReduce和YARN三个分支组成.
HDFS:NN Federation 、HA; MaoReduce:运行在YARN上的MR;YARN:资源管理系统
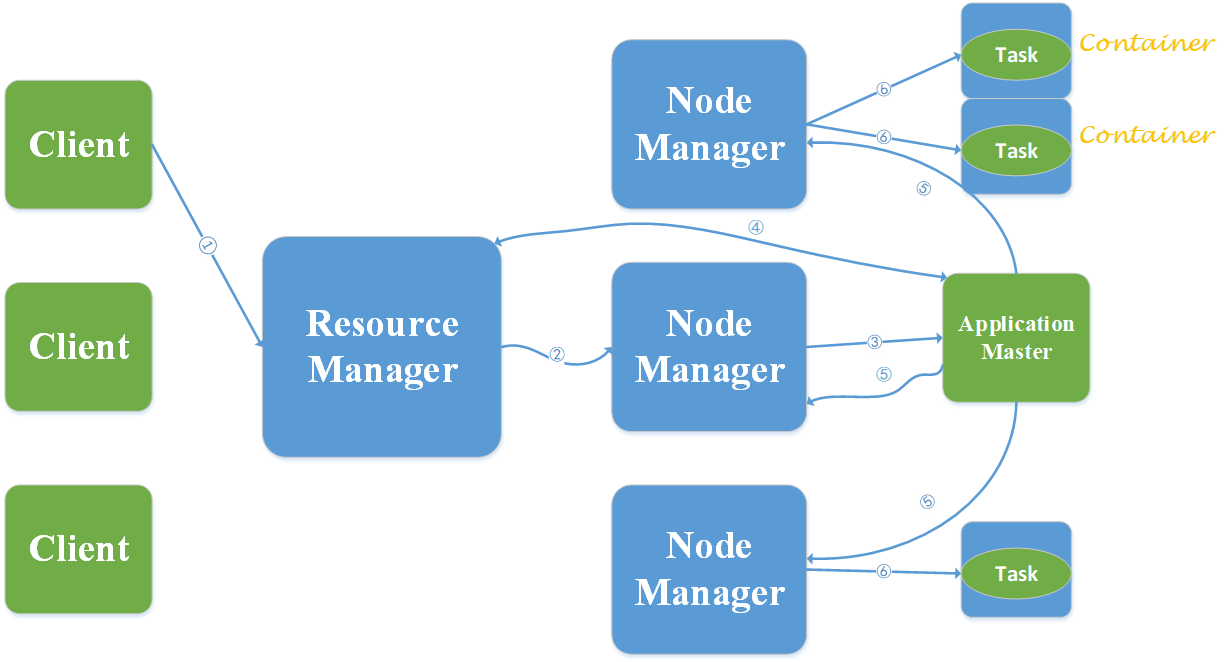
YARN的组成:
ResourceManager
处理客户端请求,启动和监控ApplicationMaster,监控NodeManager,资源分配与调度。
NodeManager
但各节点上的资源管理,处理来自ResourceManager的命令,处理来自ApplicationMaster的命令
ApplicationMaster
数据切分,为应用程序申请资源、并分配给内部任务。任务监控与容错。
Hadoop的其他组件,Zookeeper(分布式协作服务),解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。Sqoop(数据同步工具),SQL-to-Hadoop的缩写,主要用于传统数据库与Hadoop之间传输数据。数据的导入导出本质上MapReduce程序,充分利用了MR的并行化和容错性。Pig(基于Hadoop的数据流系统)提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具,定义一种数据流语言Pig Latin,将脚本转换为MapReduce任务在Hadoop上执行。通常用于进行离线分析。Mahout(数据挖掘算法库)创建一些可扩展领域的机器学习领域经典算法的实现,Mahout现在已经包含了聚类分类推荐引擎频繁集挖掘等广泛使用的数据挖掘方法。Flume(日志收集工具)他将数据从产生、传输、处理并最终写入目标路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据的发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志数据写往数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。
原文地址:http://www.cnblogs.com/20203923rensaihang/p/16848484.html