
XGBoost关键思想:
-
实现精确性与复杂度之间的平衡
树模型的学习能力与过拟合风险之间的平衡,就是预测精度与模型复杂度之间的平衡,也是经验风险与结构风险之间的平衡
在过去,我们总是先建立效果优异的模型,在依赖于手动剪枝来调节树模型的复杂度;在XGBoost中,精确性与复杂度在训练的每一步被考虑到
1). XGBoost为损失函数Loss加入结构风险项,构成目标函数O
在Adaboost和GBDT中,目标函数是找到损失函数的最小值,也就是找到让预测结果与真实结果差异最小,这一流程只关心精确性,不关心复杂度和过拟合情况。而在XGBoost中,损失函数加入了控制过拟合的结构风险项,并将Loss+结构风险项定义为目标函数。
XGBoost与其它Boosting不同在于它是朝着令目标函数最小化的目标进行训练,而不是令损失函数最小;并且XGBoost会先利用结构风险项中的参数控制过拟合,而不是想起他树模型一样依赖于树结构参数(例如:max_depth,min_impurity_decrease)
2). 使用全新不纯度衡量指标,将复杂度纳入分支规则
XGBoost重新定义了分枝指标—结构分数(也称质量分数)以及基于结构分数的结构分数增益,结构分数增益可以逼迫决策树向整体结构更简单的方向生长。
上述变化让XGBoost与传统CART略有区别的建树流程,同时在建树过程中大量使用残差或残差对象作为中间变量,因此其数学过程更为复杂
-
极大程度地降低模型复杂度、提升模型运行效率,将算法武装成更加适合于大数据的算法
XGBoost采用多种优化技巧实现效率提升:
1)使用估计贪婪算法、平行学习、分位数草图等算法构建了适用于大数据的全新建树流程
2)使用感知缓存访问技术与核外计算技术,提升算法在硬件上地运算性能
3)引入Dropout计数,为整体建树流程增加更多随机性,也让算法适应更大数据
XGBoost还保留了部分与梯度提升树类似的属性:
-
弱评估器的输出类型与继承算法输出类型不一致
无论集成算法整体在执行回归/分类/排序任务,弱评估器一定是回归器。
XGBoost和GBDT一样,也通过sigmoid或softmax函数输出具体的分类结果
注:XGBoost在windows与linux系统下支持单GPU运算,但Mac系统不支持GPU运算。只有Linux系统支持多GPU运算
弱评估器分枝:
单参数booster的值被设置为gbdtree时,XGBoost的弱评估器是使用的改进后的CART树,其分支过程与普通CART树高度一致。向着不纯度降低的方向分枝,并且每一层都是二叉树。在CART树的基础上,XGBoost创建了全新的分枝指标:结构分数与结构分数增益,更大程度的保证了CART树向减小目标函数的方向增长。
注:XGBoost不支持其他指标作为分枝指标
假设现在目标函数使用L2正则化,控制叶子数量的参数gamma为0。现在存在一个叶子节点j,对该结点来说,结构分数公式为:
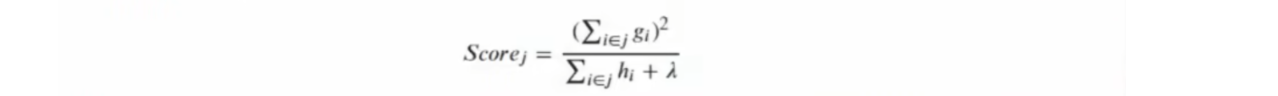
g_i为样本i在损失函数L上对预测标签求的一阶导数,h_i是样本i在损失函数L上对预测标签求得二阶导数,i∈j表示对叶子节点上的所有样本进行计算,λ就是L2正则化的系数。
由此可见,结构分数实际上是:
score = 结点j上所有样本的一阶导数之和的平方/ 结点j上所有样本的二阶导数之和的平方之和+λ
结构分数增益为:

即:Gain = 左节点得分数 + 右节点得分数 – 父节点得分数
CART树的信息增益:
CART树中的信息增益 = 父节点的不纯度 – (左节点的不纯度 + 右节点的不纯度)
有上述公式可知:随着CART树的建立整体不纯度逐渐降低,越小越好;而随着XGBoost树的建立,整体结构分数是逐渐上升的,越大越好。
注:在决策树中一个结点只能由一个输出值,因此同一片叶子上所有样本的预测值都一致。
-
结构分数与信息熵的关键区别
当左侧叶子节点的结构分数比右侧叶子节点结构分数低,是否能说明左侧叶子比右侧叶子好?
答:否。与信息熵、基尼系数等可以评价单一结点的指标不同,结构分数只能够评估结构本身的优劣,不能评估结点的优劣。也就是说,我们利用一棵树上所有叶子结点的结构分数之和来评估整棵树的结构的优劣。
结构分数为什么越大越好?
因为结构分数是计算叶子节点的标签和父节点的预测值的结构分数,二者差别越大,说明该结点的学习能力越好。
控制复杂度 — 弱评估器剪枝
XGBoost有三个剪枝参数和一个侧面影响树生长的参数,其中一个是max_depth,与其他模型用法相同,默认值为6,因此在对抗过拟合方面影响力不大。
min_child_weight:任意节点上所允许的样本量(样本权重),若一个节点上的h_i小于该参数中设置的值,则该点被剪枝。
gamma:目标函数中叶子数量T前的系数,放大gamma可以将目标函数重点转移至结构风险从而控制过拟合。
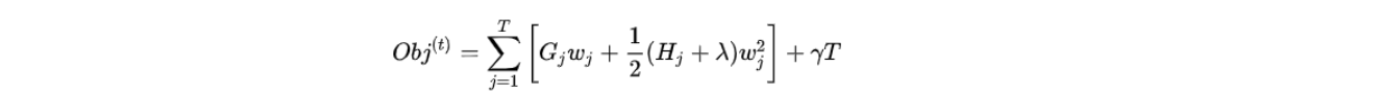
当gamma不为0时,结构分数增益的公式如下:
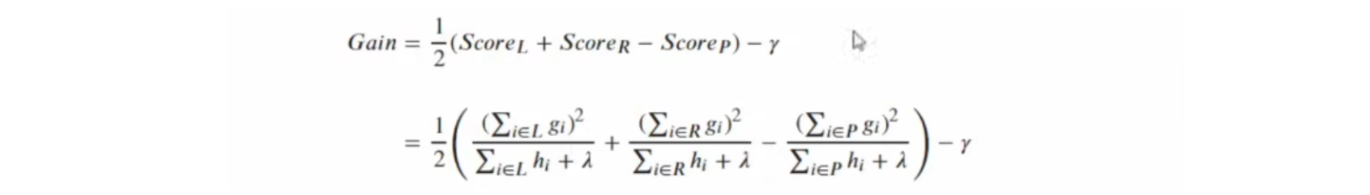
而在XGBoost中,我们追求一棵树整体的结构分数最大,因此XGBoost规定任意结构分数增益不能为负,任意增益为负的节点都会被剪枝。
参数lambda和alpha:正则化系数,同时也位于结构分数中间接影响树的生长和分枝。
当使用L2正则化时,结构分数为:
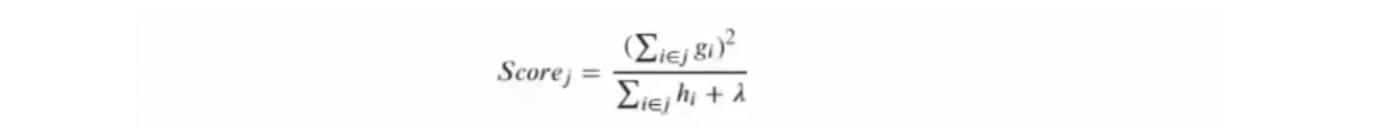
当使用L1正则化时,结构分数为:
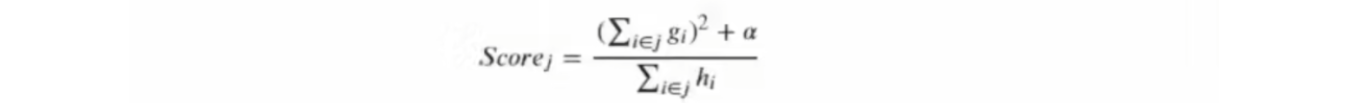
当lambad越大,结构分数越小,参数gamma的力量被放大,模型整体的剪枝会变得更加严格。同时由于lambad还可以通过目标函数将模型学习的重点拉向结构风险,因此lambda具有双重过拟合能力。
当alpha越大,结构分数越大,参数gamma的力量会被缩小,模型整体剪枝会变得更为宽松。但alpha可以通过目标函数将模型学习的重点拉向结构风险,因此alpha会通过放大结构分数抵消一部分抗过拟合能力。
整体来看,alpha是比lambad更宽松的剪枝方式。
控制复杂度 — 弱评估器的训练数据
XGBoost继承了GBDT和随机森林的优良传统:可以通过对样本和特征进行抽样来增加弱评估器多样性,从而控制过拟合。
-
样本抽样
subsamples:对样本进行抽样的比例,默认为1,可以输入(0,1]之间的任何浮点数。
Xgboost中的样本抽样是不放回抽样,因此不像GBDT或随机森林存在袋外数据的问题,同时也无法抽样比原数据更多的样本量。因此,抽样之后只能维持不变或减少,如果样本量较少,建议值设为1.
sampling_method:对样本进行抽样时所使用的抽样方法,默认均匀抽样。输入uniform:表示均匀抽样,每个样本被抽到的概率一致。建议比例在0.5及以上。
-
特征抽样
参数colsample_bytree,colsample_bylevel,colsample_bynode,三个参数都是抽样比例,可以输入(0,1]之间的任何浮点数,默认为1。
colsample_bytree:特征的抽样可以发生在建树之前
colsample_bylevel:特征抽样发生在生长出新的一层树之前
colsample_bynode:特征抽样发生在每个节点分枝之前
三个参数相互影响:全特征及 >= 建树所用的特征子集 >= 建立每一层所用的特征子集 >= 每个节点分枝时所使用的特征子集
按照CART树规则或DART树规则,使用结构分数增益进行分枝的树在XGBoost中被称为贪婪树。
XGBoost有几种不同的建树模式:基于直方图的估计贪婪树、快速直方图贪婪树、基于GPU运行的快速直方图贪婪树等。
参数
通用参数 booster:我们有两种参数选择,gbtree和gblinear。gbtree是采用树的结构来运行数据,而gblinear是基于线性模型。
silent:静默模式,为1时模型运行不输出。
nthread: 使用线程数,一般我们设置成-1,使用所有线程。如果有需要,我们设置成多少就是用多少线程。
Booster参数 n_estimator: 也作num_boosting_rounds
这是生成的最大树的数目,也是最大的迭代次数。
learning_rate: 有时也叫作eta,系统默认值为0.3,。
每一步迭代的步长,很重要。太大了运行准确率不高,太小了运行速度慢。我们一般使用比默认值小一点,0.1左右就很好。
gamma:系统默认为0,我们也常用0。
在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。因为gamma值越大的时候,损失函数下降更多才可以分裂节点。所以树生成的时候更不容易分裂节点。范围: [0,∞]
subsample:系统默认为1。
这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。 典型值:0.5-1,0.5代表平均采样,防止过拟合. 范围: (0,1],注意不可取0
colsample_bytree:系统默认值为1。我们一般设置成0.8左右。
用来控制每棵随机采样的列数的占比(每一列是一个特征)。 典型值:0.5-1范围: (0,1]
colsample_bylevel:默认为1,我们也设置为1.
这个就相比于前一个更加细致了,它指的是每棵树每次节点分裂的时候列采样的比例
max_depth: 系统默认值为6
我们常用3-10之间的数字。这个值为树的最大深度。这个值是用来控制过拟合的。max_depth越大,模型学习的更加具体。设置为0代表没有限制,范围: [0,∞]
max_delta_step:默认0,我们常用0.
这个参数限制了每棵树权重改变的最大步长,如果这个参数的值为0,则意味着没有约束。如果他被赋予了某一个正值,则是这个算法更加保守。通常,这个参数我们不需要设置,但是当个类别的样本极不平衡的时候,这个参数对逻辑回归优化器是很有帮助的。
lambda:也称reg_lambda,默认值为0。
权重的L2正则化项。(和Ridge regression类似)。这个参数是用来控制XGBoost的正则化部分的。这个参数在减少过拟合上很有帮助。
alpha:也称reg_alpha默认为0,
权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快。
scale_pos_weight:默认为1
在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。通常可以将其设置为负样本的数目与正样本数目的比值。
学习目标参数 objective [缺省值=reg:linear] reg:linear– 线性回归
reg:logistic – 逻辑回归
binary:logistic – 二分类逻辑回归,输出为概率
binary:logitraw – 二分类逻辑回归,输出的结果为wTx
count:poisson – 计数问题的poisson回归,输出结果为poisson分布。在poisson回归中,max_delta_step的缺省值为0.7 (used to safeguard optimization)
multi:softmax – 设置 XGBoost 使用softmax目标函数做多分类,需要设置参数num_class(类别个数)
multi:softprob – 如同softmax,但是输出结果为ndata*nclass的向量,其中的值是每个数据分为每个类的概率。
eval_metric [缺省值=通过目标函数选择] rmse: 均方根误差
mae: 平均绝对值误差
logloss: negative log-likelihood
error: 二分类错误率。其值通过错误分类数目与全部分类数目比值得到。对于预测,预测值大于0.5被认为是正类,其它归为负类。 error@t: 不同的划分阈值可以通过 ‘t’进行设置
merror: 多分类错误率,计算公式为(wrong cases)/(all cases)
mlogloss: 多分类log损失
auc: 曲线下的面积
ndcg: Normalized Discounted Cumulative Gain
原文地址:http://www.cnblogs.com/5466a/p/16849915.html