
1.openresty+redis+lua缓存
- 使用openresty+lua脚本实现多级缓存:
用户访问openresty中的Nginx,若null则访问redis,若null则访问数据库,数据库返回信息并存储在redis,redis在存储到nginx中。
2.反射机制
1.加载类,返回Class类型的对象(Class是java对象)
Class cls = Class.forName(ClassNamePath);
2.1.什么是反射?
反射机制能让程序在运行期间取得任何类的内部信息,如属性,方法等,并能对他们进行相关的操作。
类加载完之后,会在堆中产生一个Class对象,通过这个对象,我们可以获取原有类的所有信息,如属性,方法,构造器等。
这个对象就像一面镜子,通过这面镜子我们可以获取所有包含类的完整结构信息,所以形象地称为反射。
(这个Class对象的类型是Class类,而不是字节码文件)
(无论对一个类创建了多少了对象,堆中都只有一个Class对象)
2.2.反射的原理:
三大阶段:
(1)源代码/编译阶段:
Java源代码----javac编译---->字节码文件(.class)
(2)类加载阶段:
.class文件----ClassLoader类加载器---->加载为Class对象(堆中)
Class对象包含
成员变量:Filed[] fileds;
构造器:Constructor[] cons;
成员方法:Methods[] mes;
(3)RunTime运行阶段:
main方法---->反射机制----->获取Class对象信息,获取操作属性、调用方法。
2.3.用法
package com.reflection;
public class Cat {
private String name = "cat";
public void hi(){
System.out.println("我是猫!");
}
public void cry(){
System.out.println("嘤嘤嘤!");
}
}
2.3.1 获取Class对象
// 1. 加载类,返回Class对象(堆内存中会产生一个Class对象)
Class cls = Class.forName(classfullpath);
// 2. 获取对象实例 (获取堆中的Class实例)
Object o = cls.newInstance();
System.out.println("\n对象实例:"+o);
2.3.2 Method用法
Method method = cls.getMethod("cry");
method.invoke(o);
传统:对象.成员方法
反射:成员方法对象.invoke(对象) // .invoke()
//输出:嘤嘤嘤
2.3.3 Filed用法
//成员变量
Field field = cls.getField("name");
System.out.println(field.get(o));
传统:对象.成员变量
反射:成员变量对象field.get(对象) // .get()
2.3.4 Constructor用法
1.无参构造
Constructor constructor = cls.getConstructor();
System.out.println("无参构造:"+constructor);
2.有参构造
Constructor constructor1 = cls.getConstructor(String.class); //传String的Class对象
System.out.println("有参构造:"+constructor1);
2.3.5 优化
关闭安全检查
hi.seAccecible(false)
3.应用
3.1 jdbc数据库
3.2 Spring加载xml文件
4.优缺点
4.1 优点
可以动态创建对象和使用对象,使用灵活。
4.2 缺点
使用反射基本是解释执行,影响执行速度。
3.泛型
3.1 什么是泛型?
泛型就是将类型参数化,让程序在编译时才知道参数的具体类型。
泛型在没有使用边界的时候通常被编译器擦除为Object类型。
若使用了extends,如<T extends String> 则表示只能接收String以及String的子类。
若使用了super,如<T super String> 则表示只能接收String及String的父类。
3.2 泛型的好处?
1.类型安全:
在编译时就可以检查类型是否正确。
2.强制转化安全:
每次使用时不需要强制转化为指定的类型,
3.3 通配符
3.3.1 限定通配符
1. <T extends String> 则表示只能接收String以及String的子类。
2. <T super String> 则表示只能接收String及String的父类。
3.3.2 非限定通配符
? 可以用任意类型来代替,如List<?>
4.异常
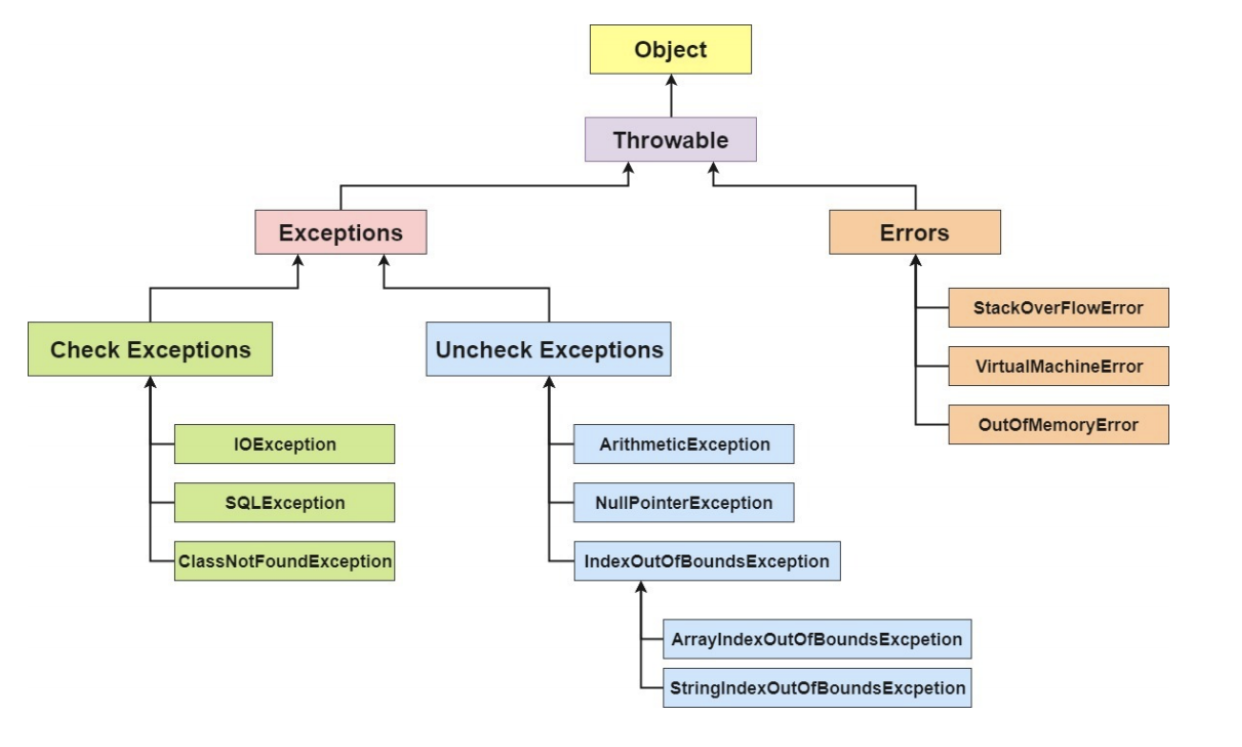
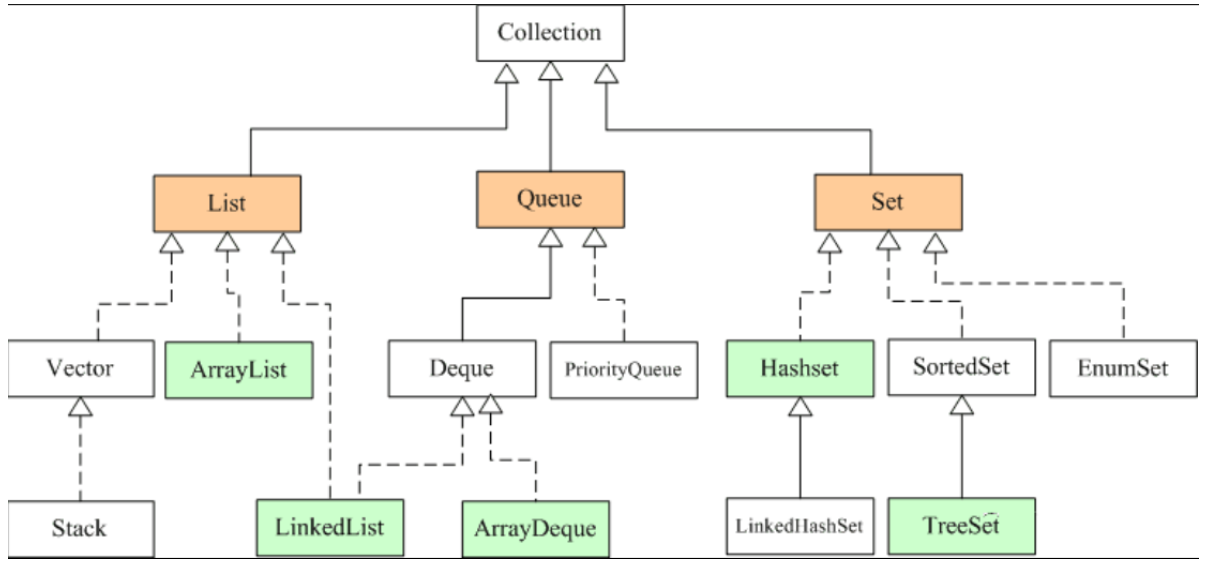
5.JAVA集合
Collection:List、Queue、Set
List:ArrayList、Vector、LinkList
Queue:Deque、ArrayDeque
Set:HashSet、SortedSet、EnumSet
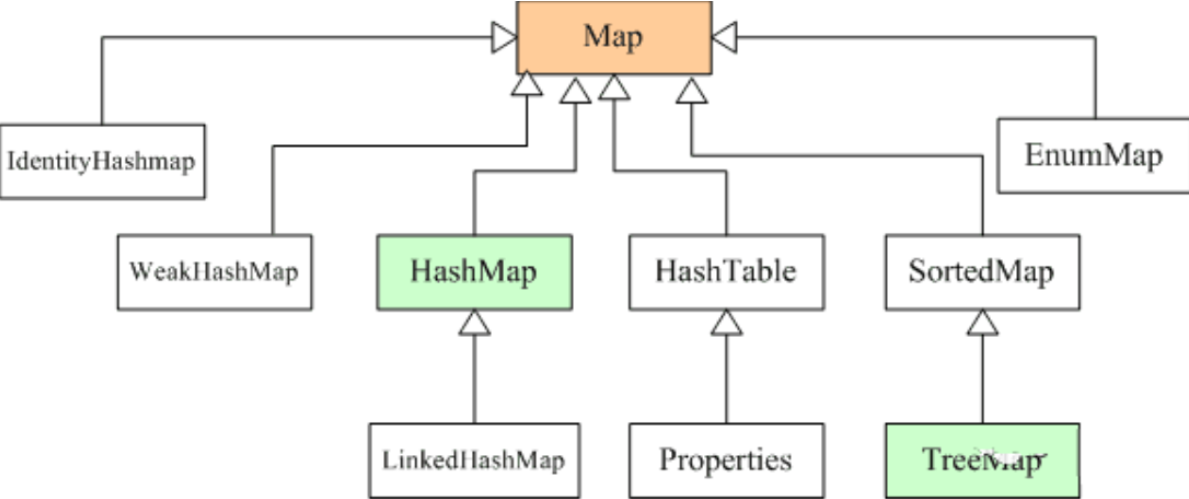
Map:HashMap、HashTable、SortedMap、
5.1 ArrayList和LinkList的异同?
-
同
(1)线程不安全。(都没有使用同步机制) (2)内存空间占用浪费。 -
异
(1)底层数据结构:数组/链表 (2)存取速度,效率: (3)快速随机访问
5.2 ArrayList和Vector的区别?
-
同
都继承自List接口 -
区别
(1)线程是否安全: (2)底层数组扩容:不够用时A扩展0.5倍,V扩展1倍
5.3 Array和ArrayList的区别?
-
存储内容
Array:存储基本数据和对象类型。 ArrayList:对象类型。 -
空间大小
Array的大小是固定的,arrayList是动态变化的。 -
方法上
ArrayList:addAll()、removeAll()等
5.4 HashMap底层原理
5.4.1初始长度
// 0000 0001 << 4 = 0001 0000 = 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
HashMap的初始长度为16,当不够用时,再扩展,但始终是2的幂次。
5.4.2 put操作原理
/**
** put(K,V) -----> putVal(hash,k,v)
**/
-
计算key对应的hash值;
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }备注:
hash()为什么要有^(h >>> 16)? 答:为了将hashCode的高位和低位一起运算,这样算出来的结果分散率较高,避免hash碰撞问题。 h:是int类型的,四个字节,32bit,是通过key(Object类型,Object有一个hashcode()方法计算hash值)的值计算出来的hashCode值。 假如 h = 00011010 11000110 11010001 01010111 h>>>16 = 00000000 00000000 00011010 11000110 (按位右移补零操作符) h ^ (h>>>16) = 00011010 11000110 11001011 10010001 (如果相对应位值相同,则结果为0,否则为1)& 如果相对应位都是1,则结果为1,否则为0 (A&B),得到12,即0000 1100 | 如果相对应位都是 0,则结果为 0,否则为 1 (A | B)得到61,即 0011 1101 ^ 如果相对应位值相同,则结果为0,否则为1 (A ^ B)得到49,即 0011 0001 〜 按位取反运算符翻转操作数的每一位,即0变成1,1变成0。 (〜A)得到-61,即1100 0011 << 按位左移运算符。左操作数按位左移右操作数指定的位数。 A << 2得到240,即 1111 0000 >> 按位右移运算符。左操作数按位右移右操作数指定的位数。 A >> 2得到15即 1111 >>> 按位右移补零操作符。左操作数的值按右操作数指定的位数右移,移动得到的空位以零填充。 A>>>2得到15即0000 1111 -
初始化一个长度为16的Node<K,V> []数组;
if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; -
根据hash值计算数组下标,判断当前数组是否存有值
(1)当前位置没有值:则new一个node<k,v>存入。
if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);备注:
//*********************注*************************// // 数组下标i可以直接取余n(数组长度),如n==16,i = hash%16 = 0~15 但是为什么要有(n-1) & hash ? 如 n-1 = 15 : 0000 1111 hash: 0101 0101 (随着key的不同而不同) & 0000 0101 (1)无论hash值如何变,最终算的i都是低位,即0~(n-1)之间。 (2)由于hash值随着key的不同而不同,所以这样算出来的i分布比较规律。(若使用hash%n算,可能算出的结果是某个i存了很多数据,其他i又没有存任何数据)(3)规定数组的大小为2的幂次,如32,64....,为了方便计算i的值,使其规律分布。 如 n-1 = 31: 0001 1111 hash: 0110 1010 & 0000 1010 (4)当初始化一个HashMap的长度n时,会返回一个大于等于n的2的幂次。 // 如 Map<String,String> map = new HashMap<>(10); // 实际上内部数组的大小为16 = 2^4(2)当前位置有值:判断key是否相同
else { Node<K,V> e; K k; //判断当前位置与要put进去得hash值、key值是否相同 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p;//相同直接等于e }当前位置hash值和key都相同,但是value不同:覆盖新的值,返回旧的值
if (e != null) { // existing mapping for key V oldValue = e.value; //如果onlyIfAbsent为true,或者旧的值为null,则覆盖新的值 if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; }
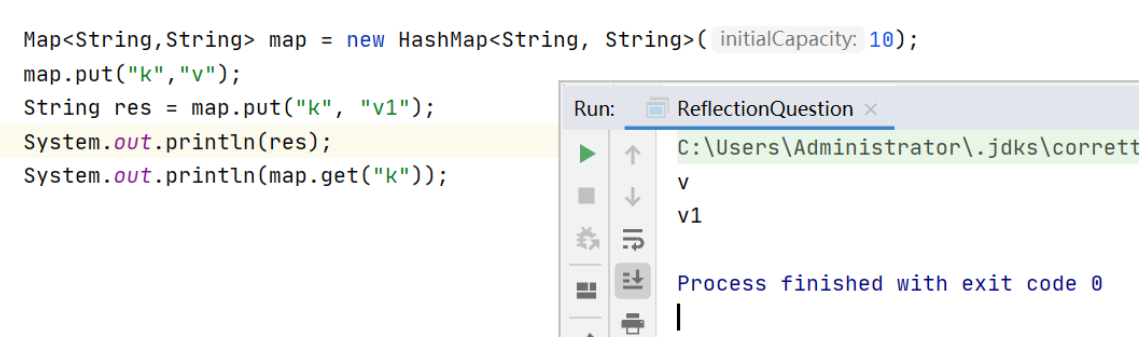
//key不同
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//(1)
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// (3)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash); //转为红黑树
break;
}
// (2)if() 判断key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
备注:
(1)for循环?
遍历table数组某个位置上的链表,进行尾插法,遍历个数,当链表个数大于8,则需要将链表改为红黑树。
(2)又有 if() 判断key值是否相等?
第一次是判断链表第一个节点的key值是否与put进来的相等,而for循环里面的if是判断链表里面的key值是否与put进来的相等。
(3)TREEIFY_THRESHOLD = 8,当binCount>7时,表示当前链表上已经有8个节点了,此时需要将链表转为红黑树,而新put进来的node节点是先加到链表上,再去转为红黑树(此时已有9个节点)。(jdk1.8)
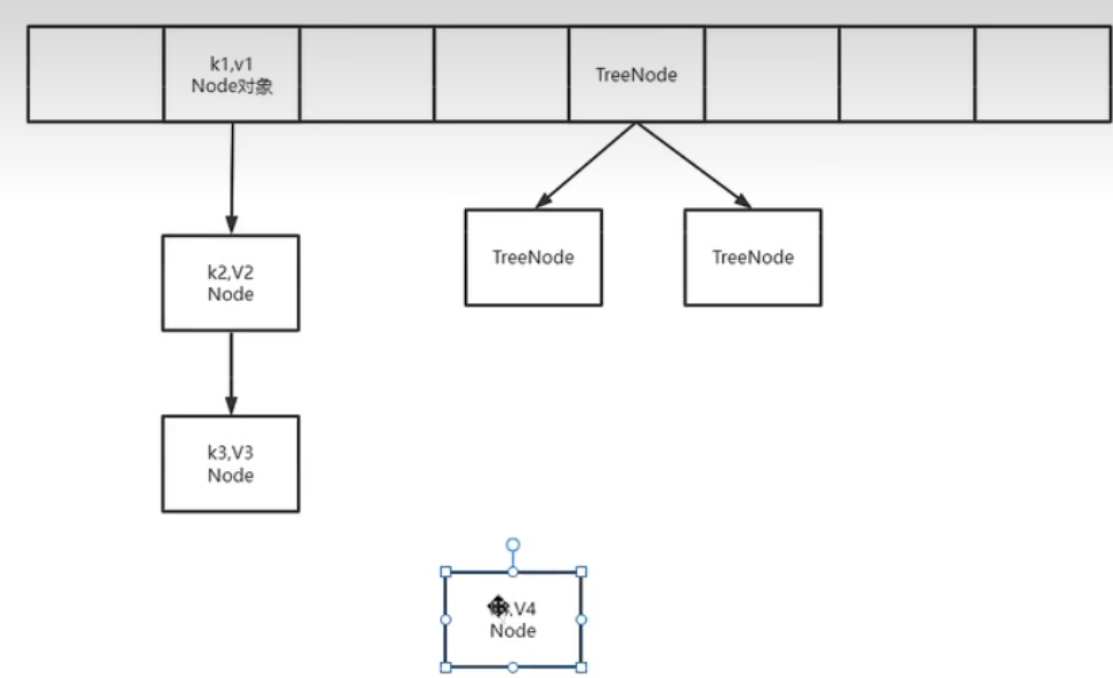
-
扩容
//每进行修改(put、modify)一次,都会去判断当前容量是否充足,threshhold为阈值。 ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict);resize()扩容
1.jdk1.7 直接新建一个数组,将老数组中的每一个节点直接转移到新数组。2.jdk1.8 final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { //太大了,大到超过最大值时,不允许扩容。 if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } //原数组的容量翻一倍(<<1)小于最大容量,且原数组容量已超过默认值 //新数组容量翻倍,新阈值也翻倍 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } //自己指定HashMap大小的时候 else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { //遍历整个数组(tab) for (int j = 0; j < oldCap; ++j) { Node<K,V> e; //发现数组某个位置存储有值 if ((e = oldTab[j]) != null) { oldTab[j] = null; //这个位置只存了一个节点(既不是链表也不是红黑树) if (e.next == null) newTab[e.hash & (newCap - 1)] = e; //这个位置上存储的是红黑树 看注3 else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); //这个位置上存储的是链表 else { //高位与低位看注1 Node<K,V> loHead = null, loTail = null;//低位头尾节点 Node<K,V> hiHead = null, hiTail = null;//高位头尾节点 Node<K,V> next; //遍历这个位置上的链表 do { next = e.next; //此处看注2 //如果这个节点是低位的,则给低位链表(尾插法) if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } //如果这个节点是高位的,则给高位链表(尾插法) else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); //将低位链表存到新的数组 if (loTail != null) { loTail.next = null; newTab[j] = loHead; } //将高位链表存到新的数组 if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }注1:
高位和低位的出现: 由于存储的数组索引是根据(n-1)& hash计算出来的,n是数组的容量大小,由于扩容之后数组的大小改变,所以某数据存储在原数组的索引与扩容之后存储的不同。 前面分析知道扩容后大小变大一倍。假如原数组大小为n=16,则扩容后变为32. 例1:hash=0110 1010 15: 0000 1111 31: 0001 1111 hash: 0110 1010 hash: 0110 1010 & 索引: 0000 1010 0000 1010 可以看出扩容之后所得到索引与原数组的相同。 例2:hash=0111 1010 (改变了第四个数为1,称“特殊位”) 15:0000 1111 31: 0001 1111 hash: 0111 1010 hash: 0111 1010 & 索引: 0000 1010 0001 1010 可以看出扩容之后所得到的索引与原数组存储的索引相差16,即相差原数组大小的距离。 结论:扩容之后,原来某个数据所存储的位置索引i可能与原来的位置相同(称为低位),也可能与原位置相差n大小(称为高位)。 即:相等 / 原+原数组大小 即:看扩容后节点存储在高位还是低位,关键在hash值的特殊位是0还是1,若是0,则低位,否则,为高位。注2:
看扩容后节点存储在高位还是低位,关键在hash值的”特殊位“是0还是1,若是0,则低位,否则,为高位。 (1)判断此节点存储在低位 (e.hash & oldCap) == 0 //oldCap:是原数组的大小 例1: 假设oldCap = 16 16: 0001 0000 hash: 0110 1010 & 值: 0000 0000 = 0 存低位 (2)判断此节点存储高位 例2: 假设oldCap = 16 16: 0001 0000 hash: 0111 1010 & 值: 0001 0000 != 0 存高位总结:链表
如果当前位置存储的是链表,在扩容时,我们首先得遍历链表得每一个节点,然后判断当前节点是存储在低位还是高位,低位的生成一个新的链表,然后存储到新数组的低位,高位的生成一个新的链表,然后存储到高位。 低位是指当前节点的hash值与原数组大小进行&运算,若为0则为低位,否则为高位。注3:红黑树
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);(1)将node对象,转化为TreeNode对象。
/*替换给定哈希索引处中的所有链接节点为TreeNode *当表太小时,在这种情况下会调整大小。 */ final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; //遍历节点 do { TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); } }TreeNode:
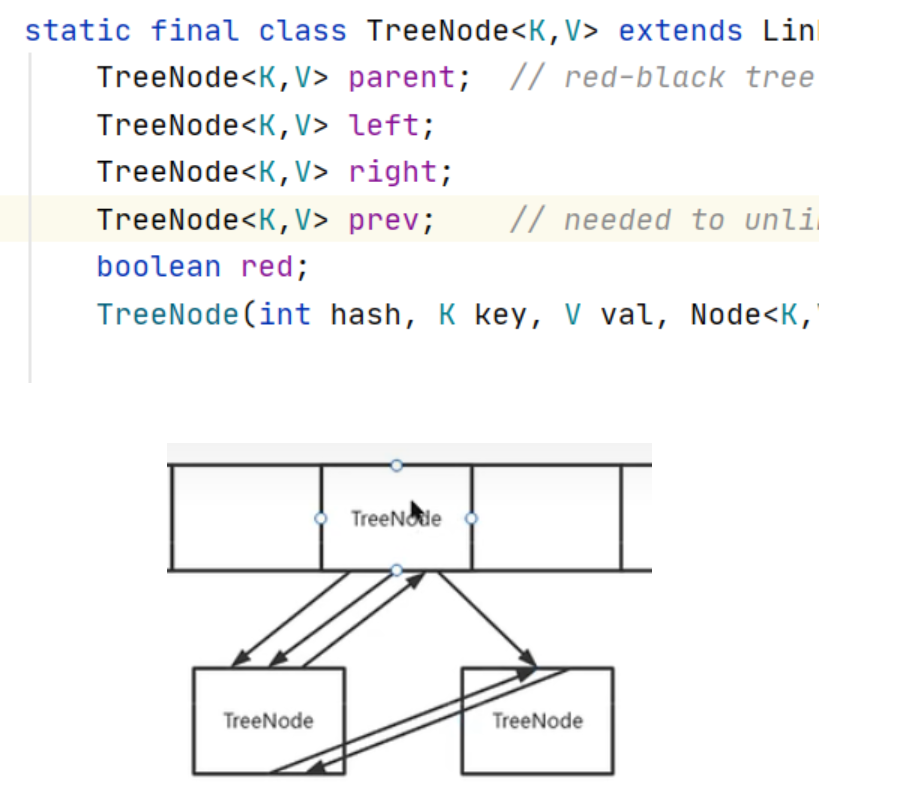
变化后如上图,一个几点有:next、pre、left、right//思路和此位置存的是链表的代码相同(看链表)
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) { TreeNode<K,V> b = this; // Relink into lo and hi lists, preserving order TreeNode<K,V> loHead = null, loTail = null; TreeNode<K,V> hiHead = null, hiTail = null; int lc = 0, hc = 0; //遍历红黑树(循环链表) for (TreeNode<K,V> e = b, next; e != null; e = next) { next = (TreeNode<K,V>)e.next; e.next = null; if ((e.hash & bit) == 0) { //低位 if ((e.prev = loTail) == null) //第一个 loHead = e; else loTail.next = e; loTail = e; ++lc; } else { //高位 if ((e.prev = hiTail) == null) hiHead = e; else hiTail.next = e; hiTail = e; ++hc; } } if (loHead != null) { ////UNTREEIFY_THRESHOLD=6 if (lc <= UNTREEIFY_THRESHOLD) //低位个数小于6时,转化为链表(退化) tab[index] = loHead.untreeify(map); else { //不满足条件时,先把头节点存在新数组位置,在判断是否要重新转化为一个新的红黑树 //当hiHead!=null时,表示有节点存在高位,而存在低位的节点需要重新生成一个红黑树 //当hiHead==null时,表示原数组这个位置的所有节点都存在新数组的低位,这样就不用重新生成一个新的红黑树,直接让头节点等于就行了,它自己本来就是一个红黑树了。 tab[index] = loHead; if (hiHead != null) // (else is already treeified) loHead.treeify(tab); } } if (hiHead != null) { if (hc <= UNTREEIFY_THRESHOLD) tab[index + bit] = hiHead.untreeify(map); else { tab[index + bit] = hiHead; if (loHead != null) hiHead.treeify(tab); } } }总结:红黑树
如果当前位置存储的是红黑树,那么扩容时,我需要去遍历当前位置的红黑树的每个TreeNode,并统计存储在低位和高位的个数。如果存在低位的个数 <= 6,就需要将存在低位的TreeNode转化为Node,存在新数组低位的链表中。 如果存在低位的个数 > 6,我们先要判断高位是否有数据,如果没有的话,直接将红黑树存在新数组低位就可以了。 如果有的话,我们就得将存在低位的节点重新生成一个新的红黑树。 -
红黑树(TreeNode)
(1)红黑树的特点:
1.每个节点是红色或黑色的。 2.根节点必须是黑色的。 3.叶子节点是黑色的并且是空节点。 4.节点是红色的,那么他的两个儿子都是黑色。(不能连续出现两个红色节点) 5.对于每个节点,从该节点到其子孙节点的路径上包含的黑节点数目相同。(2)新增一个节点:
1.新节点是黑色的,不需要调整。 2.新节点是红色的:需要变换(变色+旋转)(3)变换规则:
1.变色:新增节点的父亲节点和叔叔节点是红色。 (1)把父亲节点、叔叔节点变为黑色; (2)把祖父(父亲的父亲)节点变为红色; 2.旋转:当前节点的父亲节点是红色,而叔叔节点是黑色。 (1)左旋:当前节点是右子树 以父节点进行左旋 (2)右旋:当前节点是左子树 以祖父节点进行右旋 将父节点变为黑色,祖父节点变为红色。例子:
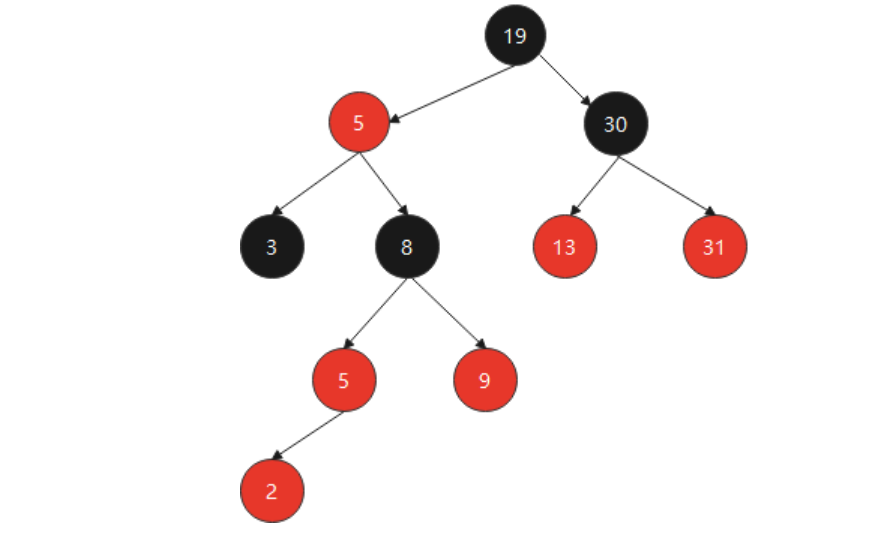
①第一步,是否符合红黑树特点:新增节点2,为红色的,树5和2节点不符合红黑树特点4,需要变换。
②第二步,是否需要变色:父节点5和叔叔节点9都是红色,需要变色。
把父节点和叔叔节点变为黑色,祖父节点变为黑色。

③第三步,是否符合红黑树特点:8不符合。变色的条件也不满足,此时就要旋转了。
④第四步,左旋:以父节点左旋。(父节点以及其左子树整个往下,右节点往上充当父节点,把右节点多余的左子树给原父节点,过程自己琢磨)
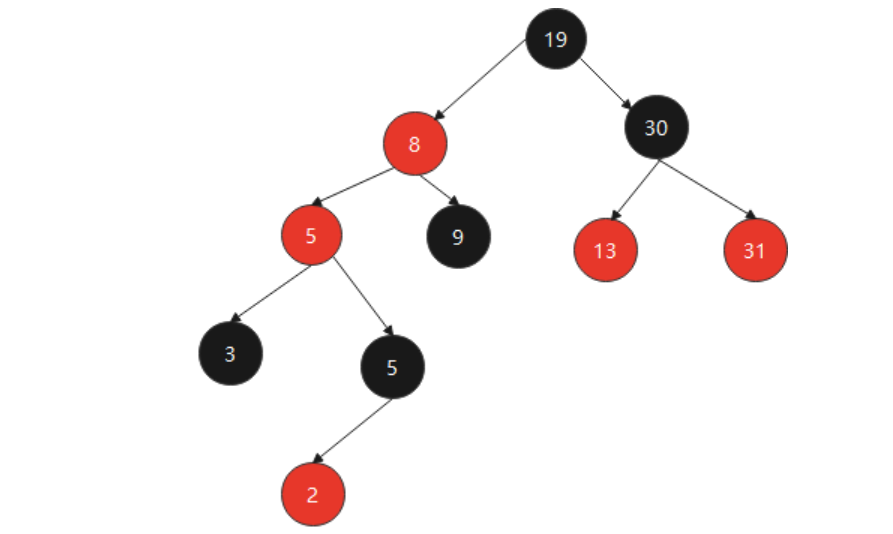
⑤第五步,是否符合红黑树特点:5和8不符合,且红节点5位于左子树,要进行右旋。
⑥第六步,右旋:以祖父节点右旋。(祖父节点以及其右子树整个往下,祖父节点的左节点此时往上充当新的祖父节点,并将多余的分支给原祖父节点)

5.5 为什么不用HashTable,反而用HashMap?
HashMap是线程不安全的,若有多个线程同时put,会造成数据丢失的情况,或者多个线程进行put和get操作,会造成get到的数据为null,而HashTable是线程安全的,为什么不用它?
答:HashTable 因为使用了sycronized锁机制,会造成同一时间只允许一个线程进行操作,其他线程只能等待锁,性能会很低。
5.6 ConcurrentHashMap底层原理
5.6.1 jdk1.7
5.6.1.1 数组结构
数据结构是数组+segment对象,采用segment分段锁和CAS保证并发。
5.6.1.2 put操作流程
/**
* ConcurrentHashMap
*/
ConcurrentHashMap<String,String> conMap = new ConcurrentHashMap<String, String>();
conMap.put("k","v");
System.out.println(conMap.get("k"));
-
构造方法
private static final int DEFAULT_CAPACITY = 16;//segment数组的长度 private static final float DEFAULT_LOAD_FACTOR = 0.75f; //负载因子(与扩容有关) DEFAULT_CONCURRENCY_LEVEL; //总entry的数目 假设new ConcurrentHashMap(16,0.75f,16) 说明segment数组大小为16,而每个segment对象内部的数组大小为1(16/16),表示只存一个entry。(默认最低2个) 假设new ConcurrentHashMap(8,0.75f,16) 说明segment数组大小为16,而每个segment对象内部的数组大小为2(16/16),表示存2个entry。传入的concurrencyLevel 8---->8 9---->16 17---->32 保证是大于等于concurrencyLevel的2的幂次 -
获取segment对象
1.第一个if是判断当前位置是否有segment对象,没有则往下执行。 2.获取segment数组的第一个位置的segment对象的信息。 3.假设此时有多个线程执行到,这里的if就是判断是否有别的线程执行到了。 4.各线程生成自己的segment对象。 5.if之后进入while循环,如果当前位置没有segment对象,则执行cas指令,将自己生成的segment对象s赋给ss大数组的第u个位置。(cas:当第u个位置为null时,处理器会将null更新为seg,处理过程不会呗别的线程中断) 补充: CAS指令需要有三个操作数,分别是内存位置V,旧的预期值A,准备设置的新值B。CAS指令执行时,当且仅当V符合A时,处理器才会用B更新V的值,否者它就不执行更新。但是,不管是否更新了V的值,都会返回V的旧值,上诉的处理过程是一个原子操作,执行期间不会被其他线程中断。 -
向segment对象里的小数组加入entry对象
1.第一个框: trylock():非阻塞加锁 lock():阻塞加锁 如果调用trylock()加锁失败,则继续调用scanAndLockForPut()加锁,直到加到锁。scanAndLockForPut()核心代码是while(!trylock()){},主要工作就是一直加锁,直到加到锁。 2.第二个框:遍历segment里面的数组的某个位置的链表 first:获取链表第一个节点 如果遇到相同的key,则覆盖value,否则生成一个entry对象,加入。
5.6.2 jdk1.8
jdk1.8 的ConcurrentHashMap舍弃了1.7的segment分段锁,采用了CAS+sycronized来并发。
数据结构和1.8的HashMap一样,是数组+链表+红黑树。
5.6.2.1 计算hash值
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS; //HASH_BITS=0x7fffffff
}
除了高16位和低16位或操作之外,最后还和HASH_BITS相与,其值为0x7fffffff,表示int的最大值01111111...。它的作用主要是使hash值为正数。在ConcurrentHashMap中,Hash值为负数有特别的意义,如-1表示ForwardingNode结点,-2表示TreeBin结点。
static final int MOVED = -1; // 表示正在扩容
static final int TREEBIN = -2; // 树的根节点
static final int RESERVED = -3; // 临时保留的
5.6.2.2 volatile修饰
使用volatile修饰来保证某个变量内存的改变对其他线程即时可见。可以配合CAS实现不加锁对并发操作的支持。
ConcurrentHashMap的get操作可以无锁,正式由于Node的元素val和指针
next是使用volatile修饰的,在多线程环境下,A线程修改节点val或者新增节点对B线程都是即时可见的,保证了数据的一致性。
5.6.2.3 put操作
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
//ConcurrentHashMap 不允许插入null键,HashMap允许插入一个null键
if (key == null || value == null) throw new NullPointerException();
//计算key的hash值
int hash = spread(key.hashCode());//看5.6.1
int binCount = 0;
//for循环的作用:因为更新元素是使用CAS机制更新,需要不断的失败重试,直到成功为止。
for (Node<K,V>[] tab = table;;) {
// f:链表或红黑二叉树头结点,向链表中添加元素时,需要synchronized获取f的锁。
Node<K,V> f; int n, i, fh;
//判断Node[]数组是否初始化,没有则进行初始化操作
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//通过hash定位Node[]数组的索引坐标,是否有Node节点,如果没有则使用CAS进行添加(链表的头结点),添加失败则进入下次循环。
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//看注1
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null))) //看注2
break; // no lock when adding to empty bin
}
//检查到内部正在移动元素(Node[] 数组扩容)
else if ((fh = f.hash) == MOVED)
//帮助它扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//锁住链表或红黑二叉树的头结点,保证并发
synchronized (f) {
//判断f是否是链表的头结点
if (tabAt(tab, i) == f) {
//如果fh>=0 是链表节点
if (fh >= 0) {
binCount = 1;//包括头节点,初始化为1
//遍历链表所有节点
for (Node<K,V> e = f;; ++binCount) {
K ek;
//如果节点存在,则更新value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
//不存在则在链表尾部添加新节点。
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//TreeBin是红黑二叉树节点
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
//添加树节点
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//如果链表长度已经达到临界值8 就需要把链表转换为树结构
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//将当前ConcurrentHashMap的size数量+1
addCount(1L, binCount);
return null;
}
注1:
//返回tab数组的第i个元素
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
注2:
/**
使用CAS指令,当tab数组的第i个位置是c(null)时,则更新c为v
**/
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
总结:
1.判断Node数组是否初始化,没有则进行初始化。
2.通过hash & (length-1) 定位索引,判断此位置是否有节点,没有则使用CAS加入,用for进行失败重试机制。有则往下执行。
3.判断数组是否在扩容,是则帮助扩容,否则往下执行。
4.锁住头节点,保证并发,判断此位置是链表还是红黑树,如果是链表,则遍历链表,判断是否有相同key的entry对象,有则覆盖value值,否则插入(尾插法)。若是红黑树,则添加一个TreeBin节点。
5.上述操作完成后,加入是在链表中插入的,则还要判断当前链表节点是否大于8,是则要转化为红黑树。
5.6.3 JDK1.7与JDK1.8的区别
1.数据结构:
1.7:segment分段锁
1.8:数组+链表+红黑树
2.线程安全机制:
1.7:采用Segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。
1.8:采用CAS+Synchronized保证线程安全.
3.锁的粒度:
1.7:对需要进行数据操作的Segment加锁.
1.8:对每个数组的头节点进行加锁(Node).
4.查询时间复杂度:
1.7:遍历链表O(n).
1.8:遍历红黑树O(logn)。
6.JVM
熟悉Gc常用算法,熟悉常见垃圾收集器,具有实际JVM调优实战经验

6.1JVM内存结构
6.1.1 总体结构
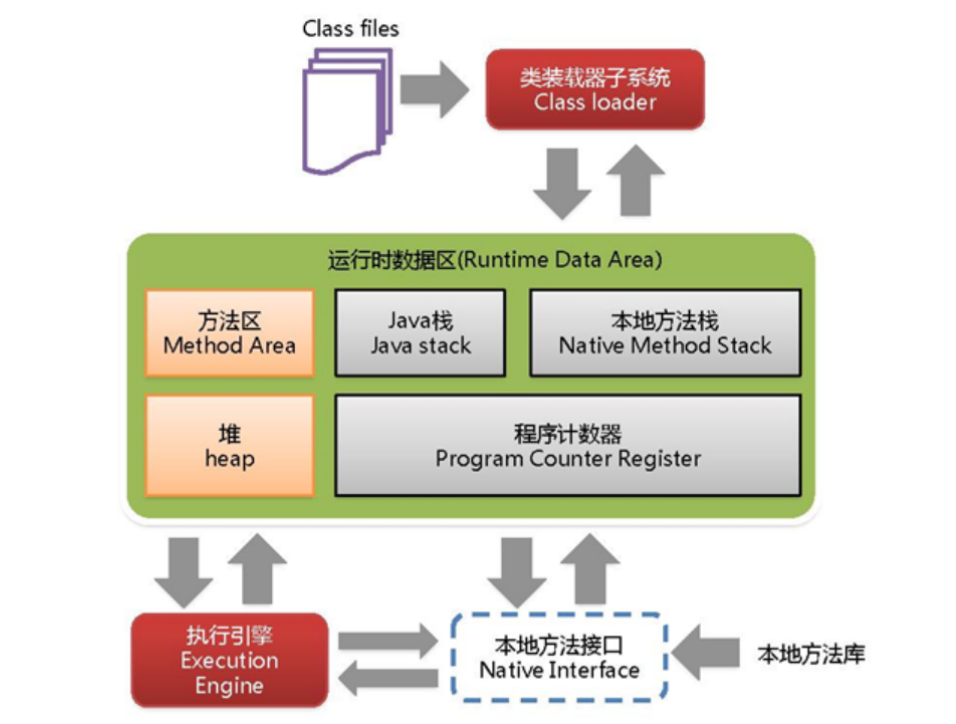
五大区域
1.程序计数器:记录当前执行的线程指令地址。
2.虚拟机栈:每个方法执行的时候都会创建一个栈帧,用于存储局部变量、操作数、方法返回信息等。
3.本地方法栈:存放native方法,使用时不会创建栈帧,直接动态链接调用方法。
4.堆:所有的实例与对象、数组
5.方法区:存放已加载的类、常量、静态变量等。(常量池)
6.1.0 各语言发展
1.c/c++:
手工管理: mallic free / new delete
忘记释放: 内存泄漏----过多---->内存溢出
释放多次: 释放第一次完成,第二次数据填写了又释放,导致数据消失
开发效率低
2.Java/Python/go:
-方便内存管理:你只管分配,不管回收
-GC(Garbage Collector)应用线程只管分配内存,垃圾回收器回收垃圾
-空指针问题无法解决
垃圾:没有被引用的对象,就是指没有指针指向的对象就是垃圾。
3.Rust:
-运行效率超高
-不用手工管理内存(无GC)
所有权:rust使用“一夫一妻制”,一个对象(栈)只会指向一个对象(堆),当栈空间对象使用结束,堆空间对象也跟着回收。
6.1.2 堆和栈
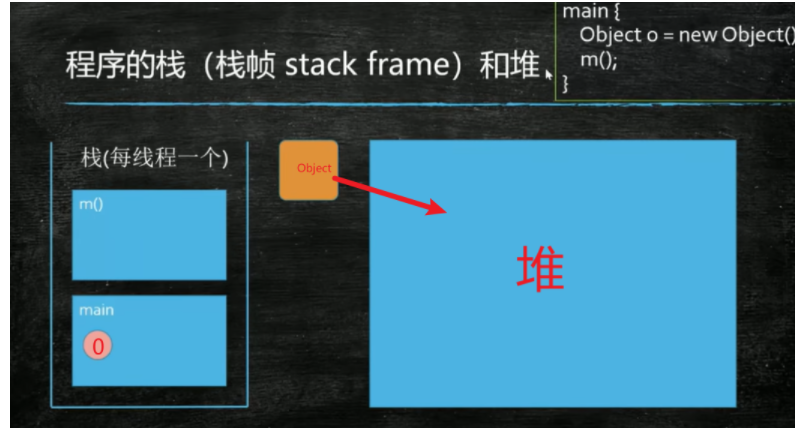
1.栈:java中每一个线程对应一个栈,每个栈中的元素叫栈帧,每执行一个方法时就是产生一个栈帧,执行方法结束后栈帧弹出栈(栈顶指针往下移动)。每个栈帧中也会包含相应的对象。
2.堆:堆是动态分配内存的,存储相应的对象或实例,如Object.
栈帧一结束就释放相应的内存空间,栈是自动释放内存的。
堆是需要自己管理的内存的,里面存的是new出来的对象,是不会自动释放内存的。
那堆空间满了怎么办?
需要自己手动释放,标记某个对象已经使用不到,这个空间可以使用。
程序最难调试的bug:
-野指针:某个指针指向了不该指向的位置。(NullPoitorException)
-并发问题:多线程访问一个共享资源
6.1.3 垃圾回收
-
什么是垃圾?
没有被引用的对象,就是指没有指针指向的对象就是垃圾。 跟着main方法,深度搜索,被搜索到的对象就不是垃圾,否则就是垃圾。 -
垃圾回收算法
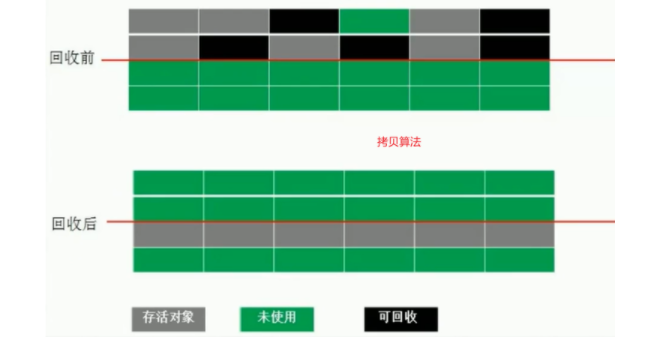
1.标记清除(mark-sweep) 标记某个位置,表示这个位置已经回收,但是碎片化很严重。 2.拷贝(copying) 将某一块未排序的存活对象拷贝到另一块,并排列好。但是浪费内存。 3.标记压缩(mark-compact) 消除前两者的缺点,在回收的时候直接整理排序好。效果等于标记清除算法完成之后在进行一次内存碎片整理 但是移动对象的同时,如果对象被其他对象引用,则还需要调整引用的地址。
-
垃圾回收器
由于各个算法都有各自的缺点,从而产生各种各样的垃圾回收器。
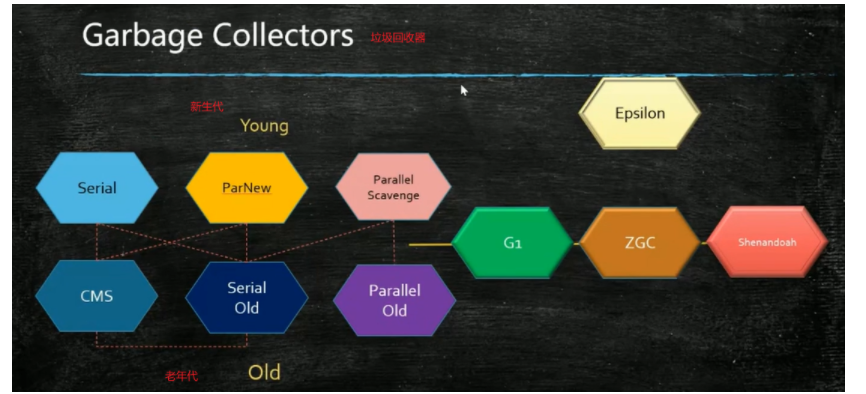
参考:https://blog.csdn.net/qq_41931364/article/details/107040928
GC的演化:
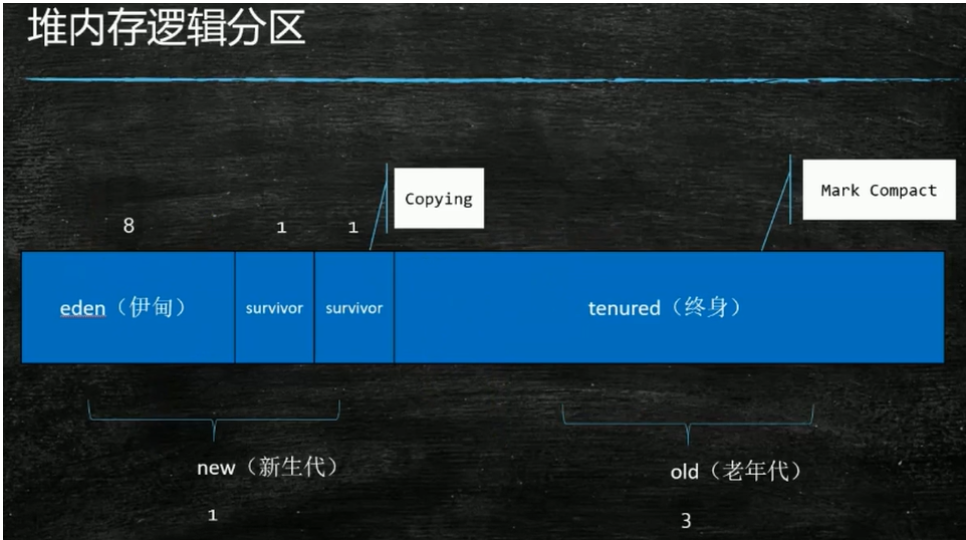
1.堆内存逻辑分区:
堆内存分为新生代和老年代,二者比例为1:3。
新生代:刚建立的对象叫做新生代,新生代区域分为Eden、Survivor、Survivor区,比例为8:1:1
老年代:新生代经过垃圾回收器扫描(每次都没被回收)的次数达到一定的阈值,就会变为老年代。
新生代会被垃圾回收器频繁扫描,而老年代对象适当老年代内存不够时,会对里面的老年代进行扫描,若发现有垃圾,则回收。
2.使用的算法:
新生代使用Copy算法,老年代使用Mark sweep/mark compact/mark sweep(前期使用,产生碎片) + mark compact(后期使用,整理碎片)
7.JAVA并发
7.1 sleep()和wait()的异同
异:
1.方法:sleep()是Thread类的方法,wait()是Object的方法。
2.解除:sleep()睡眠结束后,会解除阻塞状态,进入就绪状态;wait()只有当notify和notifyAll被调用时才会解除阻塞状态。
3.锁:sleep()不会释放锁;wait()会释放锁,并于sycronized一起使用。
4.应用:sleep()常用于暂停线程的执行;wait()常用于线程间的通信。
同:都可以暂停线程的执行。
8.Mysql
8.1 索引

8.1.1 索引是什么
索引是帮助mysql快速查询数据的数据结构,提高查询效率,就像字典的索引。
索引存储在文件系统中。
索引的数据结构有:hash、二叉树、B树、B+树
mysql使用B+树。
注:mysql为什么使用B+树?
1.使用hash存储键值对,是通过key获取数据的,但是日常工作中经常是模糊查询(范围查询)。
2.使用二叉树(包括红黑树),都会因为树的深度过深而造成IO次数增加,影响读取效率。
3.在B树(M-1个)的基础上每个节点存储的关键字数更多(M个),树的层级更少所以查询数据更快,所有关键字指针都存在叶子节点,所以每次查找的次数都相同所以查询速度更稳定。
B+树能显著减少IO次数,提高效率
B+树的查询效率更加稳定,因为数据放在叶子节点
B+树每个节点最多存放M个元素,能提高范围查询的效率,叶子节点指向下一个叶子节点(连接叶子节点)
注:B树、B+树看(13条消息) 数据结构—B树和B+树_没什么..的博客-CSDN博客_数据结构b-树和b+树
8.1.2 查看索引
explain select * from emp;//加explain
type:表示查询的类型
效率由高到低:system const ref range index all
all 的效率最低,全表扫描,尽量保持在range以上
8.1.3 mysql执行过程
实际数据和索引存储在磁盘中,在读取数据时会优先把索引加载到内存。
-
结构:
-
存储引擎:
-
MylSAM
-
InnoDB(5.1版本之后默认)
-
8.1.4 索引思想
索引是以K-V格式存储在磁盘的,mysql使用的数据结构是B+树,当读取索引时,若索引的大小很大,不能一次性读完,就考虑分块读取,使用“分而治之”的思想。(Fork/Join)
注:存在的问题
IO问题:处理器读取磁盘的速度非常慢
如何解决:减少IO量、减少IO次数。
局部性原理:
时间:之前被访问过的数据在短时间内又被访问。
空间:数据和程序都有聚集的倾向。
磁盘预读:
内存跟破盘在进行交互的时候有一个最小的逻辑单位,这个单位称之为页,或者datapage,-般是4k或者8k,由操作系统决定,我们在进行数据读取的时候,一般会读取页的整数倍,也就是4k,8k,16k,innodb存储引擎在进行数据加载的时候读取的是16kb的数据。(分块读取)
8.1.5 数据结构
-
hash表(Memeory存储引擎,InnoDB自适应)
缺点:
1.数据存储不散列,可能会导致hash碰撞。 2.hash存储键值对,是通过key获取数据的,但是日常工作中经常是模糊查询(范围查询),需要挨个遍历,效率较低。 3.当数组下的链表过长,会导致查询效率为O(n),IO次数高。 -
二叉树:
缺点:
只有两个节点,当树的深度变深,IO次数又变多了。 -
B树
假设是InnoDB,每一个磁盘块是16kb,每个元素包含key值、指针p、data数据。 假设一条记录(data)占1kb,那么一个磁盘块可以存16条记录,(实际上存不到16条,因为指针和key值还要占内存空间,这里方便计算,让他为16。),那么一个三层B树可以存16*16*16=4096条。 实际工作中数据可以有百万级以上的记录,若用B树,只能继续增加深度,这样又造成了IO读取次数变多。 -
B+树
B+树只在叶子节点存data记录,其他节点作为路径索引。 现在假设一个磁盘块还是16kb,一组数据(p,key)占10bit,一个磁盘块大约可以存1600组数据。 第三层的data还是占1kb,那么B+树三层可以存1600*1600*16=4096000组数据。 一般三到四层的B+树可以存千万级别的数据,这时候要考虑分库分表了。设计索引时,key和指针还要占内存空间,而指针p是固定不变的,若要想存储更多的数据,可以让key尽量占用最小的空间。但是实际工作中有些字段我们使用的是varchar类型,有些字段长,有些又短,那我们要怎么设计索引呢?
8.1.6 前缀索引
使用前缀统计个数。
有些字段很长,有些字段很短,可以考虑找出各个字段的公共部分作为前缀
当找字段的前7个时,他们之间的差距已经很小了,若继续往后找8,9个,cnt也不变了,说明极限是7.可以考虑使用前7个。
这时可以创建索引:
create index index_pref on citydemo
8.1.7 聚簇索引&非聚簇索引
-
聚簇索引
数据跟索引存储在一起的叫聚簇索引。 (叶子节点存储整行数据)注:
innodb存储引擎在进行数据插入的时候,数据必须要跟某一个索引列存储在一起,这个索引列可以是主键,如果没有主键,选择唯一键,如果没有唯一键,选择6字节的rowid来进行存储. 因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。聚簇索引:数据必定是跟某一个索引绑定在一起的,绑定数据的索引叫做聚簇索引。 其他索引:叶子节点中存储的数据不再是整行的记录,而是聚簇索引的id值假设一个表有id,name,age,gender id主键,name普通索引 id是聚簇索引. name对应的索引的B+树上的叶子节点存储的就是id值举例:InnoDB
(1)如索引的key是表的主键,叶子节点data保存了完整的数据记录。
(2)如索引是name时,叶子节点的data域存储表的主键。
(3)总结
1.聚集索引这种实现方式使得按主键的搜索十分高效, 但是辅助索引搜索需要检索两遍索引:首先检索辅助索 引获得主键,然后用主键到主索引中检索获得记录。 2.InnoDB既有聚簇索引也有非聚簇索引。 MylSAM只有非聚簇索引。 -
非聚簇索引
数据不跟索引存储在一起的叫非聚簇索引。 (叶子节点存储主键的值)
8.1.8 专有名词
-
回表
假设一个表有id,name,age,gender id主键,name普通索引 select * from table where name='zhangsan'; 聚簇索引---->非聚簇索引 先根据nameB+树匹配到对应的叶子节点,查询到对应行记录的id值,再根据id去id的B+树中检索整行记录,这个过程就称力为回表。 -
组合索引(联合索引)
组合索引(Compound Index)是指由多个列所组合而成的 B+树索引,这和B+ 树索引的原理完全一样,只是单列索引是对一个列排序,现在是对多个列排序。(1)创建组合索引
create table test ( id int auto_increment primary key, name varchar(50) null, workcode varchar(50) null, age int null ); create index union_index on test (name, workcode);(2)使用组合索引
select * from test where name = 'zhang' ; select * from test where name = 'zhang' and workcode='20190169'; //这两条语句都会使用组合索引 -
索引覆盖
假设一个表有id,name,age,gender id主键,name普通索引 select id,name from table where name='zhangsan'; 不需要回表 根据name的值去nameB+树检索对应的记录,能获取到id的属性值,索引的叶子节点中包含了查询的所有列,此时不需要回表,这个过程叫做索引覆盖。 推荐使用,加快查询速度。 -
最左匹配
创建索引的时候可以选择多个列来共同组成索引,此时叫做组合索引或者联合索引,要遵循最左匹配原则 id,name,age,gender id主键,name,age组合索引 select * from table where name='zhangsan' and age =12; select * from table where name='zhangsan' ; select * from table where age =12; select * from table where age =12 and name='zhangsan'; mysql 会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配 -
索引下推
select * from table where name='zhangsan' and age=12; 没有索引下推之前: 先根据name从存储引擎中拉取数据到server层,然后在server层中对age进行数据过滤 有了索引下推之后: 根据name和age两个条件来做数据筛选,将筛选之后的结果从存储引擎返回给server层 MySQL 5.6 及以上版本上推出的,用于对查询进行优化。 1.索引下推是将数据过滤下推到存储引擎,这样能有效减少回表。(推荐使用) 2.在InnoDB中只针对二级索引有效。
举例:
select * from t_user where name like 'L%' and age = 17;
这条语句从最左匹配原则上来说是不符合的,原因在于只有name用的索引,但是age并没有用到。
不用索引下推的执行过程:
第一步:利用索引找出name带'L'的数据行:LiLei、Lili、Lisa、Lucy 这四条索引数据
第二步:再根据这四条索引数据中的 id 值,逐一进行回表扫描,从聚簇索引中找到相应的行数据,将找到的行数据返回给 server 层。
第三步:在server层判断age = 17,进行筛选,最终只留下 Lucy 用户的数据信息。
使用索引下推的执行过程:
第一步:利用索引找出name带'L'的数据行:LiLei、Lili、Lisa、Lucy 这四条索引数据
第二步:根据 age = 17 这个条件,对四条索引数据进行判断筛选,最终只留下 Lucy 用户的数据信息。
(注意:这一步不是直接进行回表操作,而是根据 age = 17 这个条件,对四条索引数据进行判断筛选)
第三步:将符合条件的索引对应的 id 进行回表扫描,最终将找到的行数据返回给 server 层。
8.1.9 mysql优化
8.2 事务
8.2.1 事务
8.2.1.1 概念
事务是并发控制的单位,是用户定义的一个操作序列.
A转账100元给B
update Amoney = Amoney-100 from xxx where name = A;
update Bmoney = Bmoney+100 from xxx where name = B;
假设第一条执行成功,第二条执行失败,那么这里就会出现大问题。所以要么都成功,要么都失败,事务就可以解决这个事情
执行两条sql语句之前开启事务
执行两条sql成功,则提交事务
执行失败,则回滚事务
8.2.1.2 四个特性(ACID)
-
原子性(Atomicity)
事务是数据库的逻辑工作单位,事务中包括的诸操作要么全做,要么全不做。 -
一致性(Consistency)
事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。 -
隔离性(Isolation)
一个事务的执行不能被其他事务干扰。 -
持续性/永久性(Durability)
一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。
8.2.1.3 隔离性
-
脏读、不可重复读、幻读
-
脏读:()
A事务读取B事务尚未提交的数据,此时如果B事务发生错误并执行回滚操作,那么A事务读取到的数据就是脏数据。就好像原本的数据比较干净、纯粹,此时由于B事务更改了它,这个数据变得不再纯粹。这个时候A事务立即读取了这个脏数据,但事务B良心发现,又用回滚把数据恢复成原来干净、纯粹的样子,而事务A却什么都不知道,最终结果就是事务A读取了此次的脏数据,称为脏读。 -
不重复读(数据突然不一样了)
事务A在执行读取操作,由整个事务A比较大,前后读取同一条数据需要经历很长的时间 。而在A读取过程中,事务B对数据进行了更改。 比如此时读取了小明的年龄为20岁,事务B执行更改操作,将小明的年龄更改为30岁,此时事务A第二次读取到小明的年龄时,发现其年龄是30岁,和之前的数据不一样了,也就是数据不重复了,系统不可以读取到重复的数据,成为不可重复读。 注:不重复读是读取了其他事务更改的数据,针对update操作 解决:使用行级锁,锁定该行,事务A多次读取操作完成后才释放该锁,这个时候才允许其他事务更改刚才的数据。 -
幻读(数据凭空冒出或消失)
事务A在执行读取操作,需要两次统计数据的总量,前一次查询数据总量后,此时事务B执行了新增数据的操作并提交后,这个时候事务A读取的数据总量和之前统计的不一样,就像产生了幻觉一样,平白无故的多了几条数据,成为幻读。 注:幻读是读取了其他事务新增的数据,针对insert和delete操作 解决:使用表级锁,锁定整张表,事务A多次读取数据总量之后才释放该锁,这个时候才允许其他事务新增数据。
-
-
隔离级别
-
Default
默认值,表示使用底层数据库的默认隔离级别。大部分数据库为READ_COMMITTED(MySql默认REPEATABLE_READ) -
读未提交
该隔离级别表示一个事务可以读取另一个事务修改但还没有提交的数据。该级别不能防止脏读和不可重复读,因此很少使用该隔离级别。 -
读提交
该隔离级别表示一个事务只能读取另一个事务已经提交的数据。该级别可以防止脏读,这也是大多数情况下的推荐值。 -
重复读
该隔离级别表示一个事务在整个过程中可以多次重复执行某个查询,并且每次返回的记录都相同。即使在多次查询之间有新增的数据满足该查询,这些新增的记录也会被忽略。该级别可以防止脏读和不可重复读。 -
串行化
所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不重复读以及幻读。 缺点:但是这将严重影响程序的性能。通常情况下也不会用到该级别。 在该隔离级别下事务都是串行顺序执行的,MySQL 数据库的 InnoDB 引擎会给读操作隐式加一把读共享锁,从而避免了脏读、不可重复读和幻读问题。
mysql中,默认的事务隔离级别是重复读(repeatable-read),为了解决不可重复读,innodb采用了MVCC(多版本并发控制)来解决这一问题,但是MVCC并不能解决幻读问题。
MVCC是利用在每条数据后面加了隐藏的两列(创建版本号和删除版本号),每个事务在开始的时候都会有一个递增的版本号,用来和查询到的每行记录的版本号进行比较。 -
8.2.2 锁
8.2.3 MVCC
就是多版本并发控制。MVCC 是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问。
为什么需要MVCC呢?数据库通常使用锁来实现隔离性。最原生的锁,锁住一个资源后会禁止其他任何线程访问同一个资源。但是很多应用的一个特点都是读多写少的场景,很多数据的读取次数远大于修改的次数,而读取数据间互相排斥显得不是很必要。所以就使用了一种读写锁的方法,读锁和读锁之间不互斥,而写锁和写锁、读锁都互斥。这样就很大提升了系统的并发能力。之后人们发现并发读还是不够,又提出了能不能让读写之间也不冲突的方法,就是读取数据时通过一种类似快照的方式将数据保存下来,这样读锁就和写锁不冲突了,不同的事务session会看到自己特定版本的数据。当然快照是一种概念模型,不同的数据库可能用不同的方式来实现这种功能。
MVCC----->实现隔离性
-
当前读:
读取的是数据的最新版本,总是读取到最新的数据 -
快照读:
读取的是历史版本的记录
8.2.3.1 隐藏字段
数据表的每一行记录都会包含几个用户不可见的隐藏字段,如:
DB_TRX_ID 事务id,控制这条记录修改的版本
DB_ROW_ID 隐藏主键,可以使用记录的主键,若没有,则会自己生成一个默认的。
DB_ROLL_PTR 回滚指针,修改前上一次的记录的指针
8.2.3.2 undolog
当事务A要去修改一行记录时(假设将zhangsan改为lisi),因为事务的执行可能会回滚,所以在修改前需要把记录写入undolog日志里面,再去修改他的值,修改完之后,回滚指针的值会指向undolog的那条记录的地址。
事务执行后:表中是最新的记录
undolog:存历史记录
当不同事务堆同一条记录做修改时,该记录的undolog会形成一个线性表(链表),链首是最新记录,链尾是最早的记录。
8.2.3.3 ReadView
属性:
1.trx_ids: 当前系统中那些活跃(未提交)的读写事务ID, 它数据结构为一个List。(重点注意:这里的trx_ids中的活跃事务,不包括当前事务自己和已提交的事务,这点非常重要)
2.low_limit_id: 目前出现过的最大的事务ID+1,即下一个将被分配的事务ID。
3.up_limit_id: 活跃事务列表trx_ids中最小的事务ID,如果trx_ids为空,则up_limit_id 为 low_limit_id。
4.creator_trx_id: 表示生成该 ReadView 的事务的 事务id
访问某条记录的时候如何判断该记录是否可见,具体规则如下:
1.如果被访问版本的 事务ID = creator_trx_id,那么表示当前事务访问的是自己修改过的记录,那么该版本对当前事务可见;
2.如果被访问版本的 事务ID < up_limit_id,那么表示生成该版本的事务在当前事务生成 ReadView 前已经提交,所以该版本可以被当前事务访问。
3.如果被访问版本的 事务ID > low_limit_id 值,那么表示生成该版本的事务在当前事务生成 ReadView 后才开启,所以该版本不可以被当前事务访问。
4.如果被访问版本的 事务ID是, up_limit_id < 事务ID < m_low_limit_id 之间,那就需要判断一下版本的事务ID是不是在 trx_ids 列表中,如果在,说明创建 ReadView 时生成该版本的事务还是活跃的,该版本不可以被访问;
如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
8.2.3.4 MVCC实现原理
-
查询一条记录:
InnoDB 实现MVCC,使用ReadView + UndoLog。 ReadView判断当前版本数据是否堆事务可见,Undolog保存历史快照。 (1)事务开启(begin),获得自己得事务ID。 (2)获取Readview (3)查询数据库表,若有记录,就到ReadView中进行事务版本比较。 (4)如果符合可见性规则,就可获取记录。否则,需要到undolog快照中返回符合规则的数据。 -
MVCC是如何实现读已提交和可重复读的呢?
8.2.3.5 实现持久性
- 更新数据流程:
修改数据时,需要先在磁盘中查找对应的数据,找到之后将数据加载到内存,更新完之后,再将整个数据写入磁盘。
- 数据通过日志保证持久化:
因为随机读写的效率要低于顺序读写,为了保证数据的一致性,可以先将数据通过顺序读写的方式写到日志文件中,然后再讲数据写入到对应的磁盘文件中,这个过程顺序的效率要远远高于随机的效率,换句话说,如果实际的数据没有写入到磁盘,只要日志文件保存成功了,那么数据就不会丢失,可以根据日志来进行数据的恢复。
日志:
binlog:是在mysql的Server层,不管使用什么存储引擎,都有binlog。
redolog:InnoDB中(undolog也在)
redolog:叫做重做日志,是保证事务持久性的重要机制。当mysql服务器意外崩溃或者宕机后,保证已经提交的事务,确定持久化到磁盘中的一种措施。
因为两种日志属于不同的组件,所以为了保证数据的一致性,要保证binlog和redolog一致,所以有了二阶段提交的概念
-
为什么需要两个日志,而不是一个?
Mysql一开始并么有InnoDB存储引擎,自带的引擎是MylSAM,但是MylSAM没有crash-save(宕机保存)能力,而mysql的Server层的binlog只能用于归档,并不能crash-save。 所以最后引入了插件InnoDB,InnoDB的redo log可以实现crash-save,即使宕机也可以找到更新日志。 -
二阶段:
总结: 数据库要实现更新操作 1.首先取到相应的记录行,判断数据页是否在内存中,如果不在,则从磁盘中读取到内存。如果在,则返回这个数据。 2.接着就对数据进行更新操作,更新完之后,调用引擎接口写入新数据行。 3.引擎将新数据行更新到内存。 4.接着便将此次的更新操作信息写入redo log中,将redolog状态更新为prepare状态。 5.然后再将更新操作写入binlog中,并把binlog写入磁盘,并将redolog的状态改为commit。- 为什么要保证二阶段的提交顺序?
9. Redis
9.1 数据结构
9.2 面试题
9.1 redis使用场景
1.token令牌生成
2.短信验证码
3.使用Reids减轻数据压力
4.网页计数器(单线程)
5.分布式锁、使用框架resdison
6.订单30分钟内有效 (redis key 失效监听)
7.实现注册中心、分布式配置中心
9.2 Redis线程是否安全?
安全。redis是单线程
9.3 Redis单线程效率为何非常高?
核心就是io多路复用原则Redis官方是不支持windows.Redis.中如何存放对象?。
9.4 Redis中是否有事务机制?事务支持回滚吗?
支持事务机制。不支持事务回滚
两种形式:Multi 提交事务、Commit提交事务
redis事务默认不支持行锁,如果A线程修改了某一行数据,B线程也可以对他修改,可能产生数据不一致。
9.5 Redis存放的对象
json、二进制
9.3 redis 集群
-
创建集群
./redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1 -a Lanxiangping1224@ -
工作原理
-
项目运用
9.4 redis 持久化
方法:
1.RDB:快照方法,在指定德时间间隔内将数据集快照写入磁盘。
优:适合大规模数据恢复
缺:如果宕机,最后一次快照数据集没有保存,数据完整性不高
2.AOF:只追加文件方法,以日志的形式将redis执行的每个写操作记录下来,只允许追加文件,不能修改aof文件。
优:有三个同步配置方法,数据完整性高。
缺:文件要大于RDB,恢复速度慢,运行效率低。
3.应用:
RDB:数据不是很重要
AOF:数据很重要(如秒杀)
9.5 redis 哨兵策略
操作:对7001的主机设置哨兵策略
编辑文件sentinel.conf
9.6 redis 分布式锁
9.6.1 使用场景
1.解决缓存穿透:当redis缓存没有key时,大量请求并发访问数据库,使用分布式锁,可以让这些请求串行执行,降低压力。
2.防止秒杀超卖
3.双写一致:redis缓存中的数据被修改,导致其与数据库中的不一致。
4.接口幂等性:由于网路波动或快速点击,导致发送大量请求。如修改操作,使用分布式锁可以保证结果相等。
9.6.2 单体锁
- syscronized锁
- reentranLock锁
保证操作数据的原子性,各线程串行执行。
参考:(13条消息) 2:什么是单体应用锁?什么是分布式锁?_performer丶的博客-CSDN博客_单体应用如何枷锁
10.SpringBoot
10.2 启动流程
SpringBootApplication.run(MyApplication.class);
1.创建一个spring容器
2.启动Tomcat;
创建一个spring容器的方法:
-
xml方式 (“spring.xml”)
-
JavaConfig
refresh()会去解析clazz类,查看对应的注解,ComponentScan注解回去扫描传入run方法里面的类的包路径。所以一般如Application会写在和controller包的同级下。 -
创建DispatcherServlet,将所有请求交给Dis…
applicationContext 是Spring容器,Disp要去容器寻找Controller这个bean对象
如果不想要tomcat,想使用jetty
getWebServer的返回类型可以是Tomcat、Jetty
11. 计算机网络
11.1 OSI
使用tcp的应用协议:http、ftp、smtp、pop3等
11.2 TCP三次握手
1.第一次握手:客户端向服务端发送连接请求,服务端由closed状态被打开,成为监听状态。
2.第二次握手:服务端要告诉客户端我已经收到你的请求了,向客户端发送ACk=1确认自己已收到,并且发送自己的seq序号等信息。
3.第三次握手:客户端告诉服务端我也收到你的连接请求了,又向服务端发送ACK=1确认已经收到。
三次握手的目的就是为了保证客户端和服务端个自己的收发能力都没有问题,且互相都能接收到。
11.3 TCP四次挥手
1.第一次:客户端向服务端发送FIN=1,表示自己要和服务端断开,不在发送数据。
2.第二次:虽然客户端表示要断开了,但是还是允许服务端向客户端发送未完成的数据。
3.第三次:等服务端发送完数据之后,服务端向客户端发送FIN=1,表示自己要和客户端断开连接。
4.第四次:客户端收到信息,向服务端发送确认报文ACK=1表示自己收到请求,并同意断开连接。
11.IO
11.1 IO多路复用
什么是IO多路复用?
IO多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。
我们只要把所有流从头到尾查询一遍,就可以处理多个流了,但这样做很不好,因为如果所有的流都没有I/O事件,白白浪费CPU时间片。
正如有一位科学家所说,计算机所有的问题都可以增加一个中间层来解决,同样,为了避免这里cpu的空转,我们不让这个线程亲自去检查流中是否有事件,而是引进了一个代理(一开始是select,后来是poll),
这个代理很牛,它可以同时观察许多流的I/O事件,如果没有事件,代理就阻塞,线程就不会挨个挨个去轮询了,伪代码如下:
while true
{
select(streams[]) //这一步死在这里,知道有一个流有I/O事件时,才往下执行
for i in streams[]
{
if i has data
read until unavailable
}
}
但是依然有个问题,我们从select那里仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。
所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。
所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))伪代码如下:
while true
{
active_stream[] = epoll_wait(epollfd)
for i in active_stream[]
{
read or write till
}
}
select和epoll的区别:
1.select只是告诉你一定数目的流有事件了,至于哪个流有事件,还得你一个一个地去轮询。
2.而epoll会把发生的事件告诉你,通过发生的事件,就自然而然定位到哪个流了。
不能不说epoll跟select相比,是质的飞跃,我觉得这也是一种牺牲空间,换取时间的思想,毕竟现在硬件越来越便宜了。
12. Spring
12.1什么是spring
1.spring是一个开源的、轻量级的框架,同时是一个容器,如spring容器,管理着所有的bean对象。
2.同时也是一个生态,没有spring作为基础,spring全家桶就无法进行开发和使用。
3.spring的两大核心和IOC、AOP
IOC:控制反转,将对象的控制权由我们自己转换为spring容器,让容器去配置和管理对象的生命周期 ,不需要我们自己进行
spring让开发变得更加简单。
12.2 spring底层原理
12.2.1 使用spring容器(创建spring容器)
使用spring容器时,需要将配置类传过去。
public class Test {
public static void main(String[] args) throws ClassNotFoundException {
ApplicationContext applicationContext = new ApplicationContext(AppConfig.class);
}
}
//也可以传xml配置文件
//ApplicationContext applicationContext = new ApplicationContext(“spring.xml”);
12.2.2 常见术语
-
单例类:
spring IOC容器只会创建一个bean对象,对于每一个请求都使用那个唯一的实例对象。 在没有线程安全问题的前提下,没必要每个请求都创建一个对象,这样子既浪费CPU又浪费内存; -
多例类:
Spring IOC容器会在每一次获取当前Bean时,都会产生一个新的Bean实例. 为了防止并发问题;即一个请求改变了对象的状态(例如,可改变的成员变量),此时对象又处理另一个请求,而之前请求对对象状态的改变导致了对象对另一个请求做了错误的处理;
12.2.2 Spring容器代码
12.2.2.1 创建bean
ApplicationContext.java
-
构造函数
1.扫描所有的bean对象,通过ComponentScan注解中的路径信息扫描相应的包下的所有.class文件。 2.遍历所有.class文件,使用反射获取所有类名。 3.创建beanDefinition,并设置相应的class类型和scope类型,默认情况下是单例类(singleton)。 4.将所有beanDefinition存入ConcurrentHashMap中。 5.遍历ConcurrentHashMap,判断若是单例类则需要创建bean对象,并将bean存入单例池中。public ApplicationContext(Class configClass) throws ClassNotFoundException { /** 一、扫描所有的bean对象 **/ this.aClass = configClass; /** * 1.判断这个配置文件是否有componentScan注解 * 若有则获取注解 */ if(aClass.isAnnotationPresent(ComponentScan.class)){ ComponentScan componentScan = (ComponentScan) aClass.getAnnotation(ComponentScan.class); String path = componentScan.value(); //com.example.service //实际上扫描.class文件 path = path.replace('.','/'); ClassLoader classLoader = ApplicationContext.class.getClassLoader();//类加载器 URL resource = classLoader.getResource(path); System.out.println("resource:"+resource); File file = new File(resource.getFile()); System.out.println("File:"+file); //E:\project\spring\out\production\spring\com\example\service /** * 2.拿到路径后,判断这路径下是否是目录 * 如果是目录,则拿到目录下的所有bean对象 */ if(file.isDirectory()){ File[] files = file.listFiles(); for (File f : files) { //把.class文件筛选出来 String fileName = f.getAbsolutePath(); System.out.println(fileName); //file+XXX.class或其他 if(fileName.endsWith(".class")){ String className = fileName.substring(fileName.indexOf("com"), fileName.indexOf(".class")); className = className.replace("\\","."); //com.example.service.XXX Class<?> clazz = classLoader.loadClass(className); if(clazz.isAnnotationPresent(Component.class)){ //说明是bean对象,生成一个beanDefinition对象 BeanDefinition beanDefinition = new BeanDefinition(); beanDefinition.setType(clazz); /** * 3.根据scop判断判断bean是单例还是多例 * 单例:singleton * 多例:prototype */ if (clazz.isAnnotationPresent(Scope.class)) { //prototype 多例 Scope scopeAnnotation = clazz.getAnnotation(Scope.class); beanDefinition.setScope(scopeAnnotation.value()); }else{ //singleton beanDefinition.setScope("singleton"); } /** * 4.将beanDefinition对象存入concurrentHashMap中 */ Component component = clazz.getAnnotation(Component.class); String beanName = component.value(); concurrentHashMap.put(beanName,beanDefinition); } } } } } /** 二、判断有哪些bean **/ for (String beanName : concurrentHashMap.keySet()) { BeanDefinition beanDefinition = concurrentHashMap.get(beanName); if(beanDefinition.getScope().equals("singleton")){ Object singletonBean = createBean(beanName,beanDefinition);//创建单例bean对象 singletonObjects.put(beanName,singletonBean); } } } -
获取bean对象 getBean()
1.根据传入的名称,从concurrentHashMap中获取相应的beanDefinition。 2.判断是单例bean还是多例bean,是单例bean的话直接从单例池中获取。 3.是多例bean的话直接创建一个新的bean对象。public Object getBean(String beanName){ BeanDefinition beanDefinition = concurrentHashMap.get(beanName); if(beanDefinition == null){ throw new NullPointerException(); }else{ String scope = beanDefinition.getScope(); if(scope.equals("singleton")){ Object bean = singletonObjects.get(beanName); if(bean == null){ Object bean1 = createBean(beanName,beanDefinition); singletonObjects.put(beanName,bean1); } return bean; }else{ return createBean(beanName,beanDefinition); } } } -
创建bean对象 createBean()
private Object createBean(String beanName, BeanDefinition beanDefinition) throws NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException { //使用反射获取构造方法的实例 Class aClass = beanDefinition.getType(); Object instance = aClass.getConstructor().newInstance(); return instance; } -
测试
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, InstantiationException, IllegalAccessException, InvocationTargetException { ApplicationContext applicationContext = new ApplicationContext(AppConfig.class); Object bean = applicationContext.getBean("userService"); System.out.println(bean); }- 实现依赖注入
上面的代码只实现了获取bean对象,但是对象里面没有任何属性,所以得进行依赖注入。(填充属性) 例如:假设要在UserService中使用OrderService,要如何实现依赖注入。在main函数中:
UserService bean = (UserService) applicationContext.getBean("userService"); System.out.println(bean); bean.test(); //输出 :nullUserService.java @Scope("singleton") @Component("userService") public class UserService { @Autowired private OrderService orderService; public void test(){ System.out.println(orderService); } }//在createBean()方法中 /** 依赖注入的简单代码 **/ //遍历bean对象中的属性,查看是否有需要依赖注入的(写了@Autowired注解) for (Field f : aClass.getDeclaredFields()) { if(f.isAnnotationPresent(Autowired.class)){ f.setAccessible(true);//反射机制中需要设置访问权限 f.set(instance,getBean(f.getName()));//获取bean,并设置 } }再次运行main函数 UserService bean = (UserService) applicationContext.getBean("userService"); System.out.println(bean); bean.test(); //输出 :com.example.service.OrderService@66d3c617
12.2.3 Spring的生命周期
bean创建的生命周期:
userService.class ---> 调用无参构造方法 ---> 对象 ---> 依赖注入(初始化前(调用含有@PostConstruct方法)、初始化、初始化后) ---> bean对象
-
依赖注入:
给前面获得的对象的加了@Autowired注解的属性赋值 (1)查看哪些属性带有@Autowired注解 (2)赋值 /** * 依赖注入 */ //遍历bean对象中的属性,查看是否有需要依赖注入的(写了@Autowired注解) for (Field f : aClass.getDeclaredFields()) { if(f.isAnnotationPresent(Autowired.class)){ f.setAccessible(true);//反射机制中需要设置访问权限 f.set(instance,getBean(f.getName()));//获取bean,并设置 } }若想自定义对象的属性,去查数据库,对象的属性该怎么赋值? 1.初始化前:可以自己定义一个方法,在初始化前去调用这个方法,那spring怎么知道要去调用哪个方法? 可以在方法前加@PostConstruct注解,spring会去找含有此注解的方法,然后调用。 for (Method m : aClass.getDeclaredMethods()) { if(m.isAnnotationPresent(PostConstruct.class)){ m.invoke(userService,null); } } 2.初始化:可以让bean对象(userService)去实现InitializingBean接口,然后实现afterPropertiesSet方法,spring会在初始化的时候去判断bean有没有实现这个方法,若实现,则去调用。
原文地址:http://www.cnblogs.com/lxpblogs/p/16852420.html