
AMD 5870 显卡 (cypress) 架构
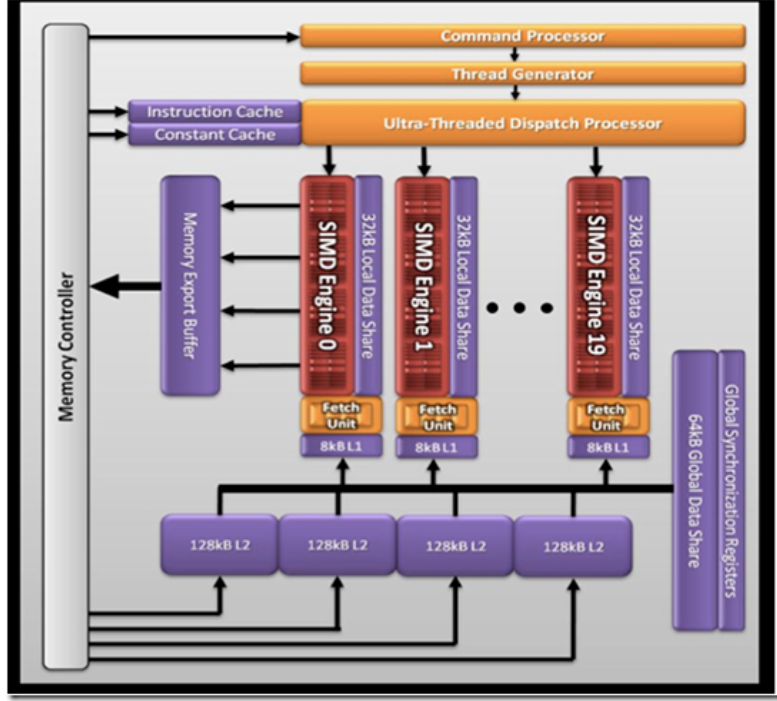
- 20 个 simd 引擎,每个 simd 引擎包含 16 个 simd
- 每个 simd 包含 16 个 stream core
- 每个 stream core 都是 5 路的乘法 –加法运算单元( VLIW processing)
- 每个 stream core 是一个 5 路的 VLIW 处理器,在一个 VLIW 指令中,可以最多发射 5 个标量操作。标量操作在每个 pe 上执行
- CU( 8xx 系列 cu 对应硬件的 simd)内的 stream core 执行相同的 VLIW 指令
- 在 CU(或者说 simd)内同时执行的 work item 放在一起称作一个 wave,它是 cu 中同时执行的线程数目。在 5870中 wave 大小是 64,也就是说一个 cu 内,最多有 64 个 work item 在同时执行
- 单精度运算可以达到 Teraflops
- 双精度运算可以达到 544Gb/s
我们现在看下 AMD GPU 硬件在 OpenCL 中的对应关系:
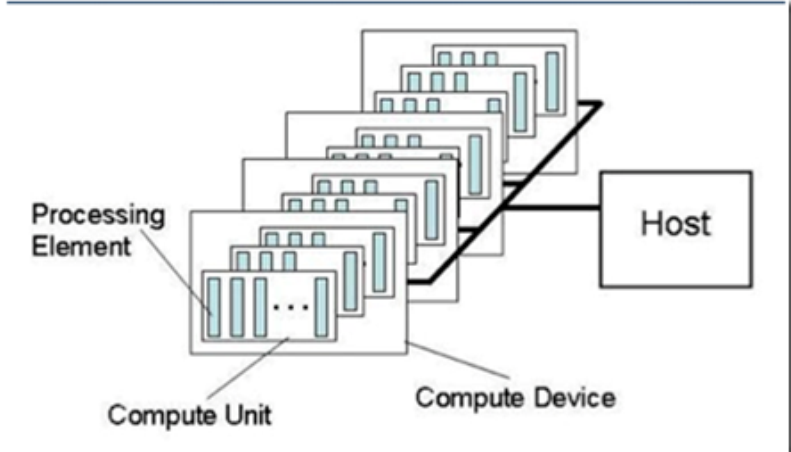
- 一个 workitme 对应一个 pe, pe 就是单个的 VLIW core ,也就是每个simd core 中的某个具体的VLIW 线程
- 一个 cu 对应多个 pe, cu 就是 simd 引擎
- 一个 simd 引擎的示意图,每个 simd 引擎由一系列的 stream core 组成

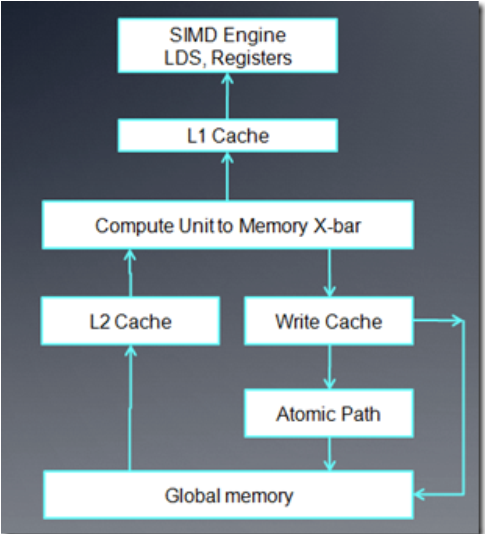
- 对每个 cu 来说,它使用的内存包括 onchip 的 LDS 以及相关寄存器。在 5870 中,每个 LDS 是 32K,共 32 个bank,每个 bank 1k,读写单位 4 byte
- 对每个 cu 来说,有 8K 的 L1 cache。( for 5870)
- 各个 cu 之间共享的 L2 cache,在 5870 中是 512K
- fast Path 只能执行 32 位或 32 位倍数的内存操作
- complete path 能够执行原子操作以及小于 32 位的内存操作
AMD GPU 的内存架构和 OpenCL 内存模型之间的对应关系:
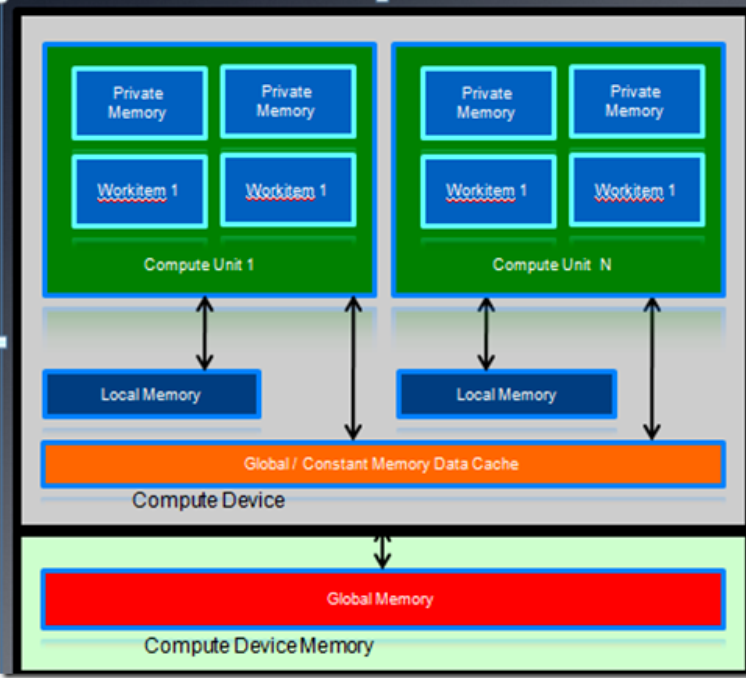
- LDS 对应 local memeory,主要用来在一个 work group 内的 work times 之间共享数据。 steam core 访问 LDS 的速度要比 Global memory 快一个数量级
- private memory 对应每个 pe 的寄存器
- constant memory 主要是利用了 L1 cache
- 注意:对 AMD CPU, constant memory 的访问包括三种方式: Direct-Addressing Patterns ,这种模式要求不包括行
列式,它的值都是在 kernel 函数初始化的时候就决定了,比如传入一个固定的参数。 Same Index Patterns ,所有的 work
item 都访问相同的索引地址。 Globally scoped constant arrays ,行列式会被初始化,如果小于 16K,会使用 L1 cache,
从而加快访问速度。当所有的 work item 访问不同的索引地址时候,不能被 cache,这时要在 global memory 中读取。
原文地址:http://www.cnblogs.com/aalan/p/16852729.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性