
Motivation
虽然半监督学习减少了大量数据标注的成本,但是对计算资源的要求依然很高(无论是在训练中还是超参搜索过程中),因此提出想法:由于计算量主要集中在大量未标注的数据上,能否从未标注的数据中检索出重要的数据(Coreset)呢?
Analysis
当前用来半监督学习的方案:
- 自洽正则化(Consistency Regularization):自洽正则化的思路是,对未标记数据进行数据增广(加入噪声等),产生的新数据输入分类器,预测结果应保持自洽。即同一个数据增广产生的样本,模型预测结果应保持一致。
- 最小化熵(Entropy Minimization):许多半监督学习方法都基于一个共识,即分类器的分类边界不应该穿过边际分布的高密度区域。具体做法就是强迫分类器对未标记数据作出低熵预测。
半监督学习能够成功实施的必要条件:有标签的数据和无标签的数据来自相同的分布。否则会导致模型性能的大幅度下降。因此 DS3L 将其转化为了一个双层的优化问题:

下面的式子和普通的半监督学习一直,不过在无标签正则化项(自洽正则化或最小化熵)前加上了权重参数,权重参数由什么决定:越不影响模型在有标签数据上的表现的数据权重越大;
换句话说:你用一个无标签的数据 A 更新了参数,结果发现更新玩参数的模型在有标签的数据集上表现变差了,那么 A 就是 OOD 或者有巨大噪声的数据,他的权重越小越好,权重为 0 表示不要 A 这个数据了。
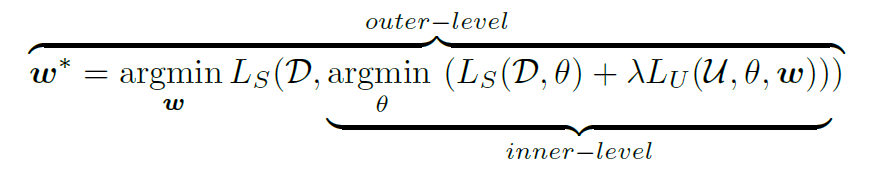
上图:双层优化。
我们选取 Coreset 的出发点也是一样:选择一个无标签数据的子集 $S_t$,使得在这个子集上半监督训练出的参数,在有标签数据上的误差最小,同样是个双层优化。
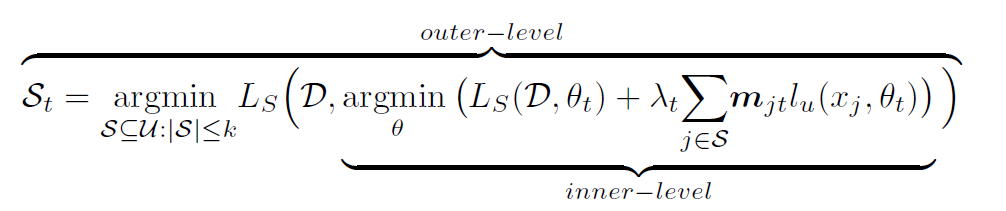
但是这个式子明显是不可解的,首先我们需要遍历出所有的 $S_t$ 组合,对每一种组合应用半监督训练使其收敛,用收敛后的模型权重应用到有标签数据计算准确率,再用这个准确率评估我们选的子集怎么样,复杂度不可想象。
因此用近似的方法进行转化,转化为一层的优化问题:
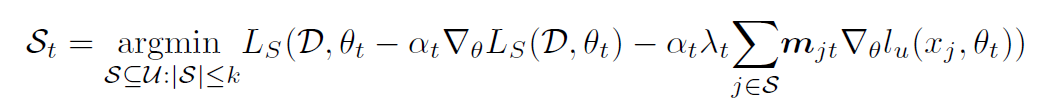
上图的核心思想是适应性的数据挑选,也就是说不是选一种 Coreset 就一次训练到收敛,而是根据训练进度逐渐调整 Coreset,直到得到最好的 Coreset:首先仍然遍历出所有的 $S_t$ 组合,对每一种组合计算半监督训练的损失函数,用这个损失函数优化一遍参数,只进行一次迭代,然后用更新后的模型对有标签的数据求准确度,再用这个准确率评估我们选的子集怎么样,因为这只是一步迭代,因此子集会不断更新。
相当理想了,但是计算复杂度依然是不可接受的,原因就在于最开始的遍历出所有的 $S_t$ 组合,因此作者又提出:当式子中的 $L_s$ 项(即有标签数据的损失项)是交叉熵形式的时候,整个式子就拥有了次模性,因此可以用贪心算法快速解决,同时保证收敛性和收敛速度,也就是原本开始时我们需要遍历所有的可能的 $S_t$ 组合,现在只需要遍历所有的可能加入 $S_t$ 的单个数据就可以了。加上符号,变成具有单调(增)性的次模函数:
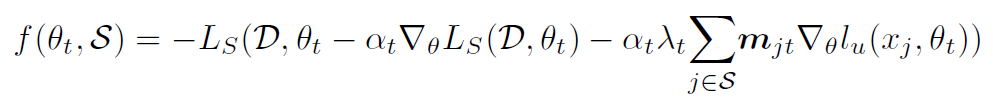
次模性的定义:

因此每次我们只需要挑选让这个次模函数增长最大的单个(无标签)数据,把他加到 Coreset 里面就行了。
作者说现在很好,但是我懒得一个一个计算![]() (也就是加上把单个无标签数据 e 加到 Coreset 里面后一次优化后,模型在有标签数据上的损失的负值)怎么办,别慌,可以用泰勒展开近似估计:
(也就是加上把单个无标签数据 e 加到 Coreset 里面后一次优化后,模型在有标签数据上的损失的负值)怎么办,别慌,可以用泰勒展开近似估计:
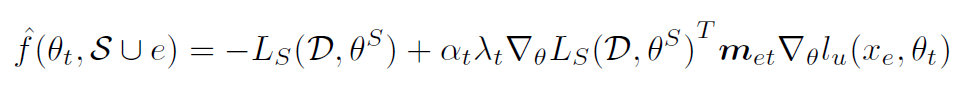
Algorithm

原文地址:http://www.cnblogs.com/metaz/p/16852711.html