
GTX480-Compute 2.0 capability
- 有 15 个 core 或者说 SM( Streaming Multiprocessors )
- 每个 SM, 一般有 32 cuda 处理器
- 共 480 个 cuda 处理器
- 带 ECC 的 global memory
- 每个 SM 内的线程按 32 个单位调度执行,称作 warp。每个 SM 内有 2 个 warp 发射单元
- 一个 cuda 核由一个 ALU 和一个 FPU 组成, FPU 是浮点处理单元

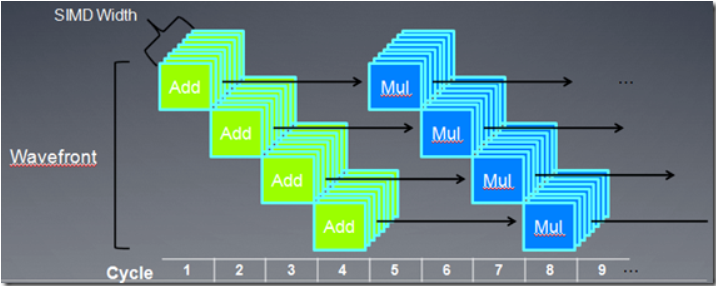
SIMT 和 SIMD
SIMT 是指单指令、多线程
- 硬件决定了多个 ALU 之间要共享指令
- 通过预测来处理多个线程间的 Diverage(是指同一个 warp 中的指令执行路径产生不同)
- NV 把一个 warp 中执行的指令当作一个 SIMT。 SIMT 指令指定了一个线程的执行以及分支行为
- SIMD 指令可以得到向量的宽度,这点和 X86 SSE 向量指令比较类似。 SIMD 的执行和管线相关 : 1) 所有的 ALU 执行相同的指令 2) 根据指令可以管线分为不同的阶段。当第一条指令完成的时候( 4 个周期),下条指令开始执行
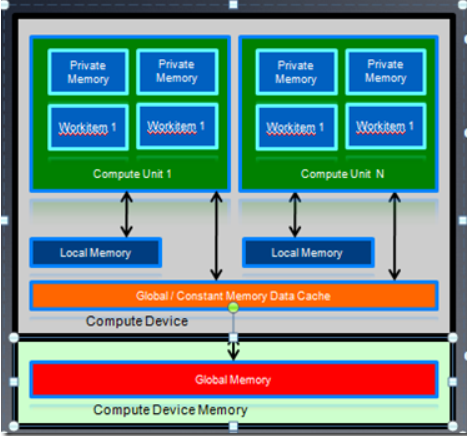
Nvida GPU 内存机制

每个 SM 都有 L1 cache,通过配置,它可以支持 shared memory,也可以支持 global memory。 48 KB Shared / 16 KB
of L1 cache, 16 KB Shared / 48 KB of L1 cache, work item 之间数据共享通过 shared memory。每个 SM 有 32K 的
register bank L2(768K) 支持所有的操作,比如 load,store 等等 Unified path to global for loads and stores.
NV GPU 内存模型和OpenCl 内存模型对应关系:
Nv 的 GPU 内存模型和 OpenCL 内存模型的对应关系是:
shared memory 对应 local memory
寄存器对应 private memory
显卡上的GDDR 是global memory
原文地址:http://www.cnblogs.com/aalan/p/16852823.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性