
1 安装JDK(jdk-8u281-linux-x64.tar.gz) ,上传并解压到/usr/lib/jdk1.8/jdk1.8.0_281
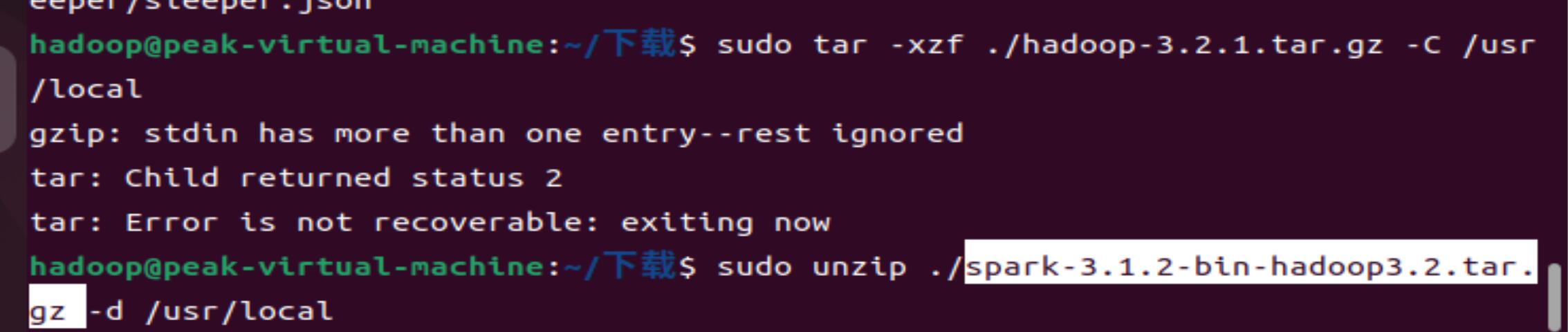
2 安装Hadoop(hadoop-3.2.1.tar.gz),上传并解压到/usr/local/hadoop-3.2.1
3安装Spark(spark-3.1.2-bin-hadoop3.2.tar.gz),上传并解压到/usr/local/spark
此步进行解压须得先在/usr/local里创建文件夹spark以致可以将解压好的关于spark文件集中存放在文件夹spark中。(因为spark解压后不止一个文件夹,如若不提前创建文件夹spark的话会在下一步进行环境配置变量时无法将spark的路径进行明确标定。)
关于解压缩的规范写作:
cd /mnt/hgfs/share #注意区分大小写字母,JDK安装包所在位置
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jdk1.8 #把JDK文件解压到/usr/lib/jdk1.8目录下
sudo tar -zxf ~/下载/apache-flume-1.9.0-bin.tar.gz -C /usr/local
4配置环境变量
vim /etc/profile
在配置文件(/etc/profile)末尾添加:
export JAVA_HOME=/usr/local/jdk1.8/jdk1.8.0_281 (根据自己文件的路径进行修改)
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop-3.2.1 (同上)
export PATH=$PATH:$HADOOP_HOME/bin
export SPARK_HOME=/usr/local/spark (同上)
export PATH=$PATH:$SPARK_HOME/bin
保存关闭刷新
source /etc/profile
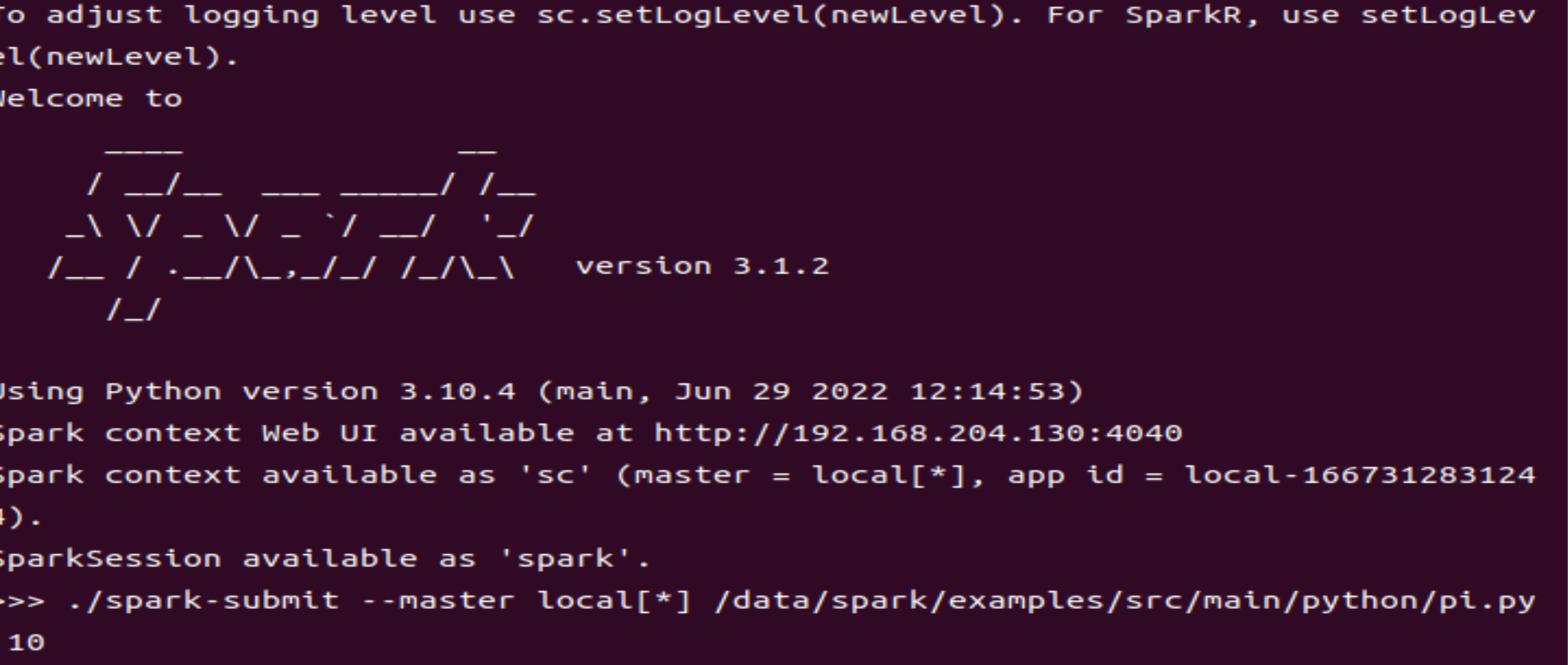
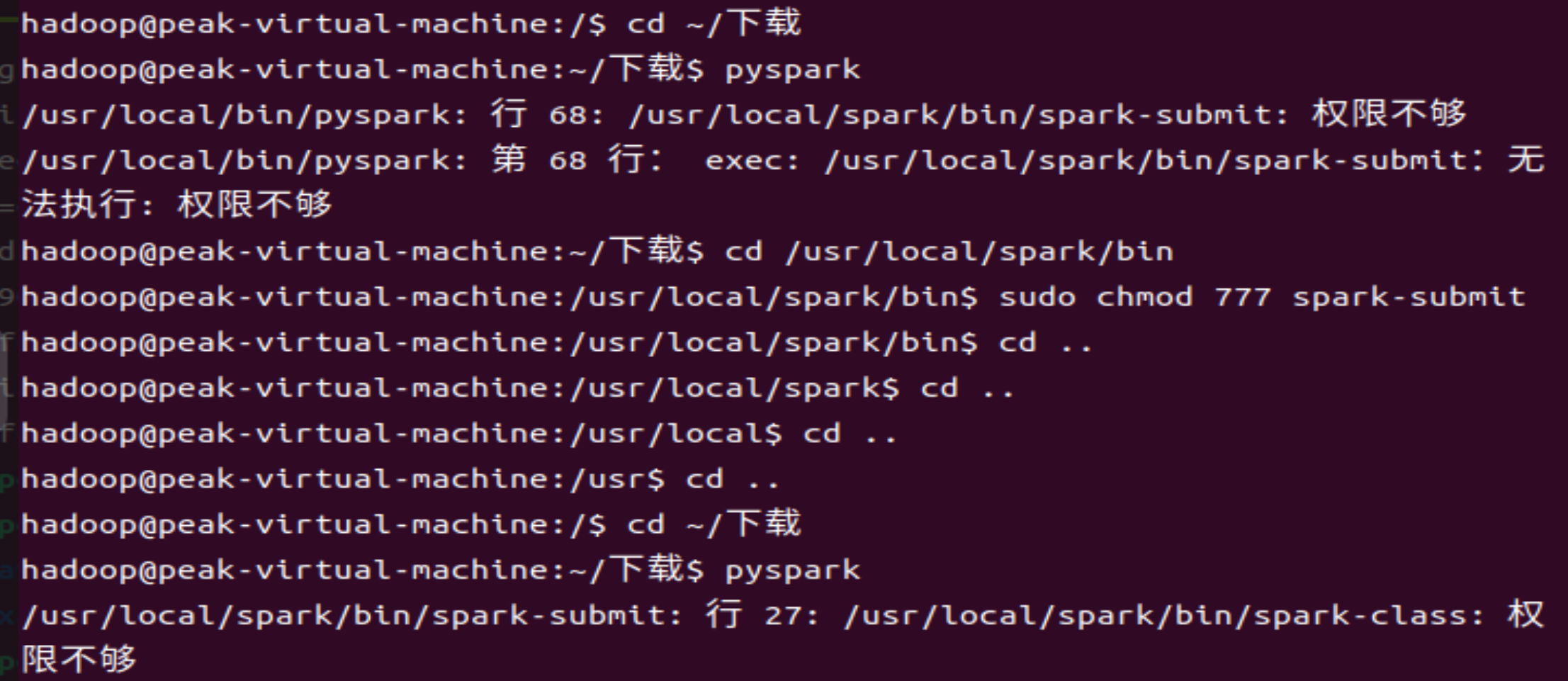
5启动pyspark交互式环境
pyspark
显示状况如下:
会出现的问题如下:
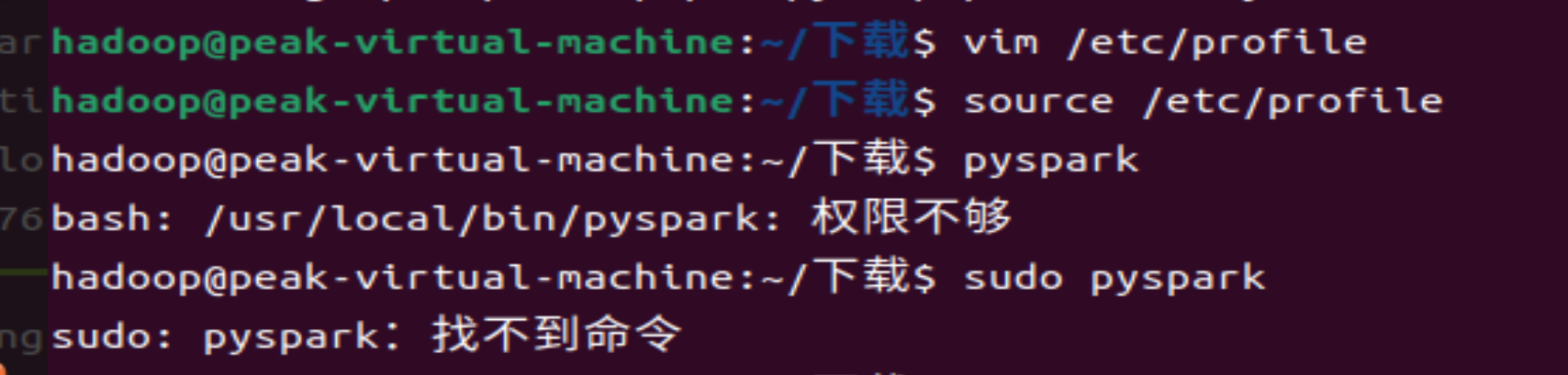
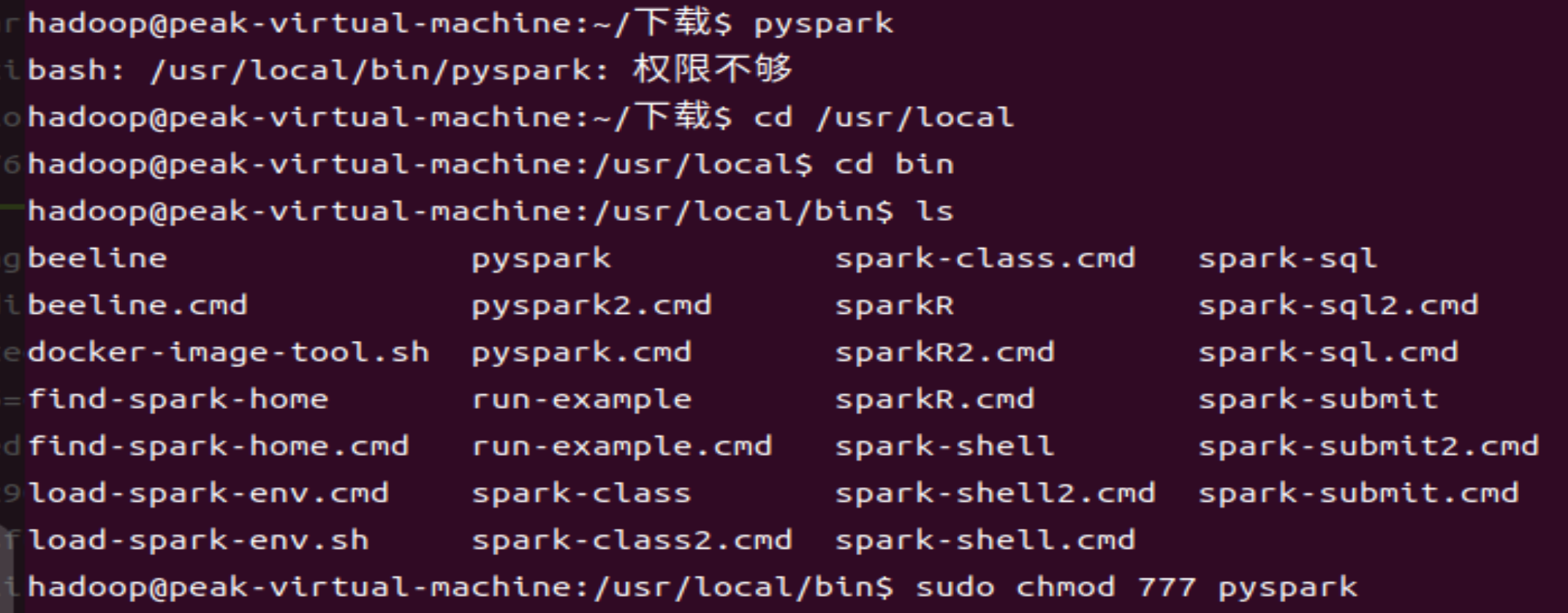
解决方法:哪儿权限不够修改哪儿(sudo chmod 777 文件夹名)
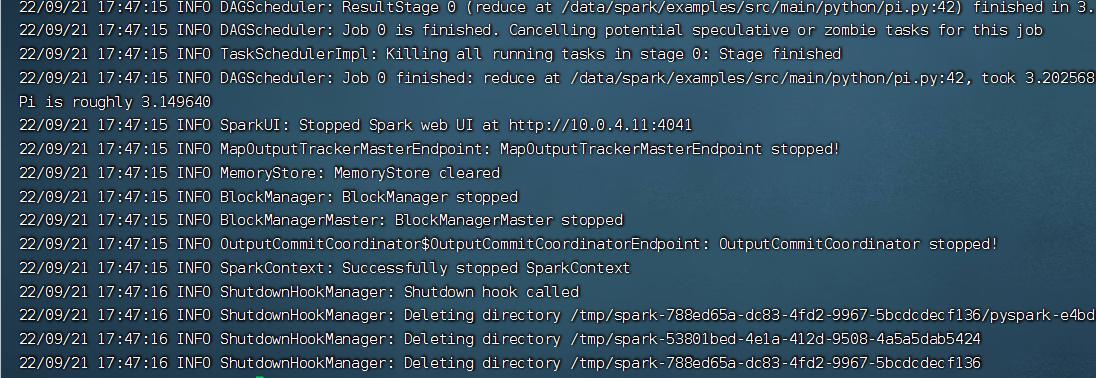
6运行Demo
./spark-submit –master local[*] /usr/local/spark/examples/src/main/python/pi.py 10 (此命令不是写在spark标志出来所形成的三个箭头后面的,和普通命令一样写在目录之下)

结果显示如下:
配置本地pyspark
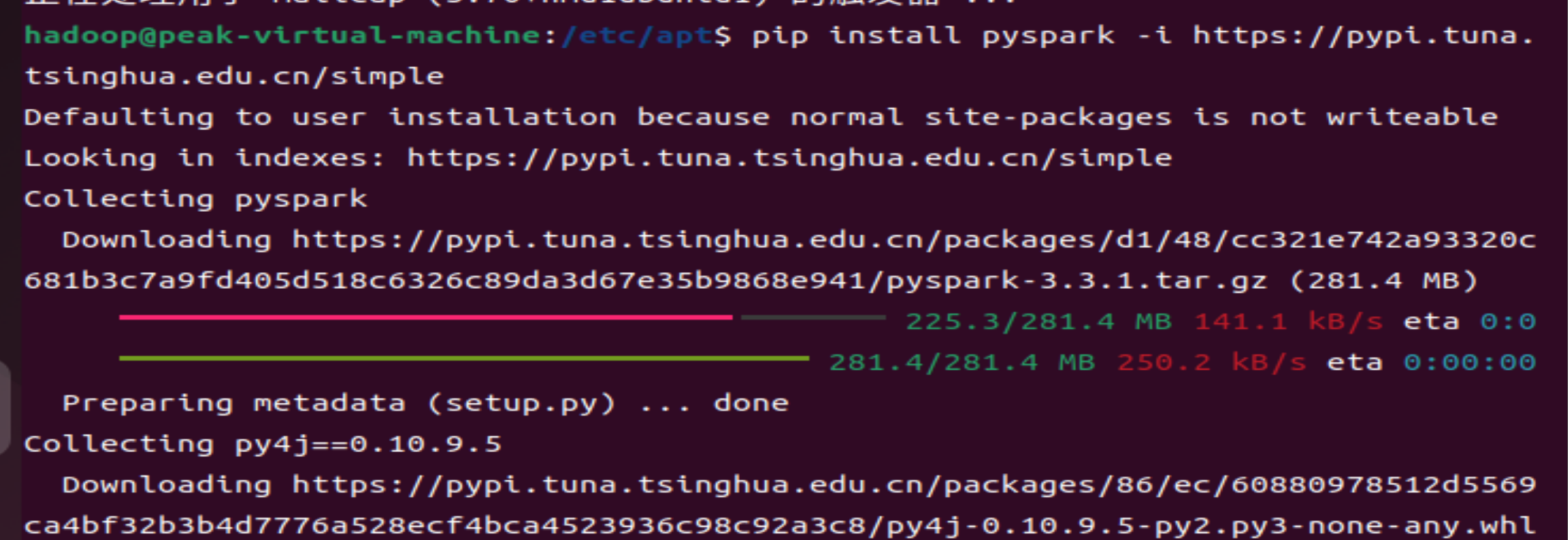
pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple
可能会出现一些问题,以下是我出现问题的部分解决实验步骤,都是在网上进行copy的,大家可以根据自己实验所出现的问题进行修改。


运行pyspark代码步骤如下:
代码如下:
from pyspark import SparkConf, SparkContext
if __name__ == ‘__main__’:
conf = SparkConf() \
.setMaster(‘local[*]’) \
.setAppName(“wordcount”)
sc = SparkContext(conf=conf)
rdd = sc.textFile(“/usr/local/spark/test/1.txt”) \
.flatMap(lambda x: x.split(” “)) \
.map(lambda x:(x,1)) \
.reduceByKey(lambda a,b:a+b)
print(rdd.collect())
sc.stop()
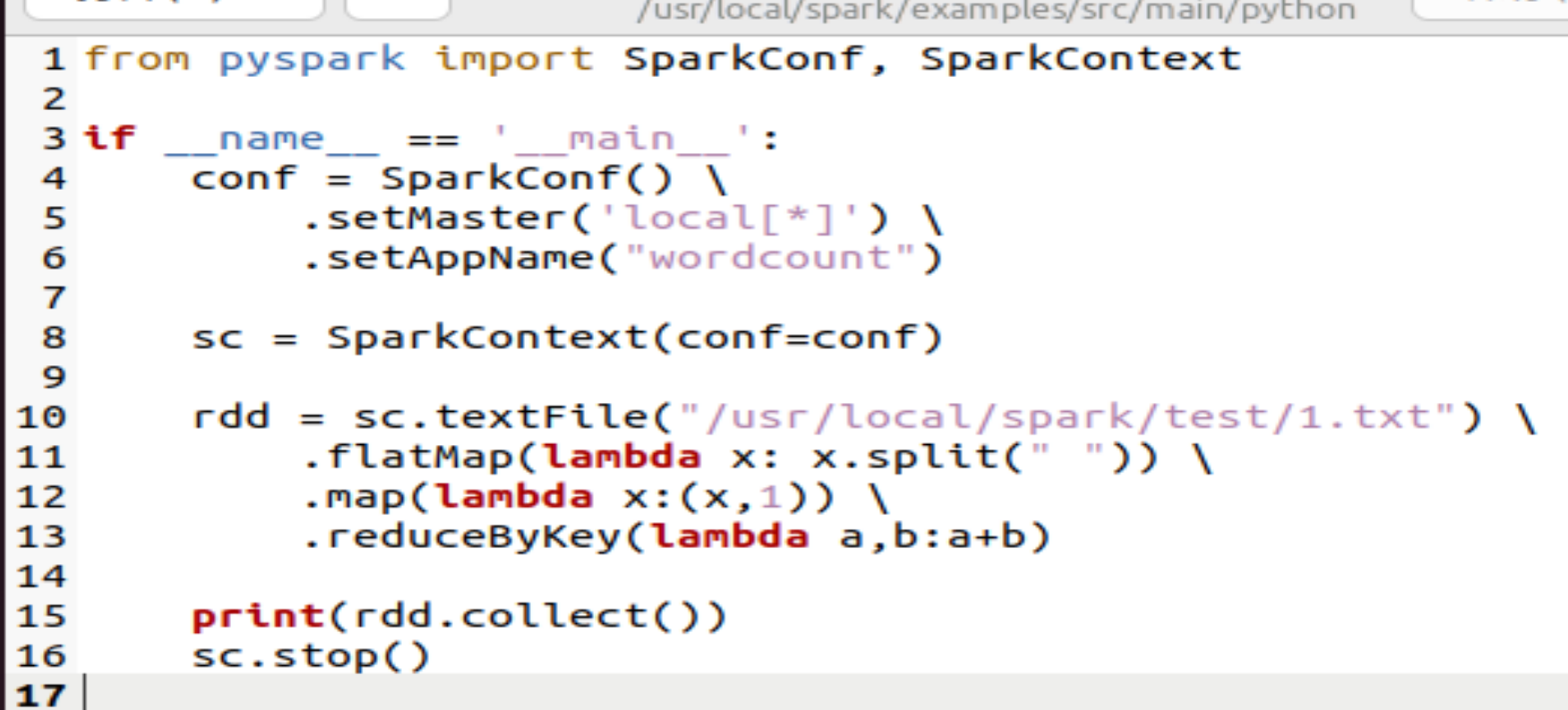
首先我在我的电脑/usr/local/spark中创建了文件夹test,并在文件夹test中创建了文件1.txt,其中文件的内容是hello world !!!!! (文件名必须以.txt为后缀结尾,因为此代码设置的文件类型是textFile)。
然后在文件夹python中创建以.py为后缀的文件方便代码的存放及运行。

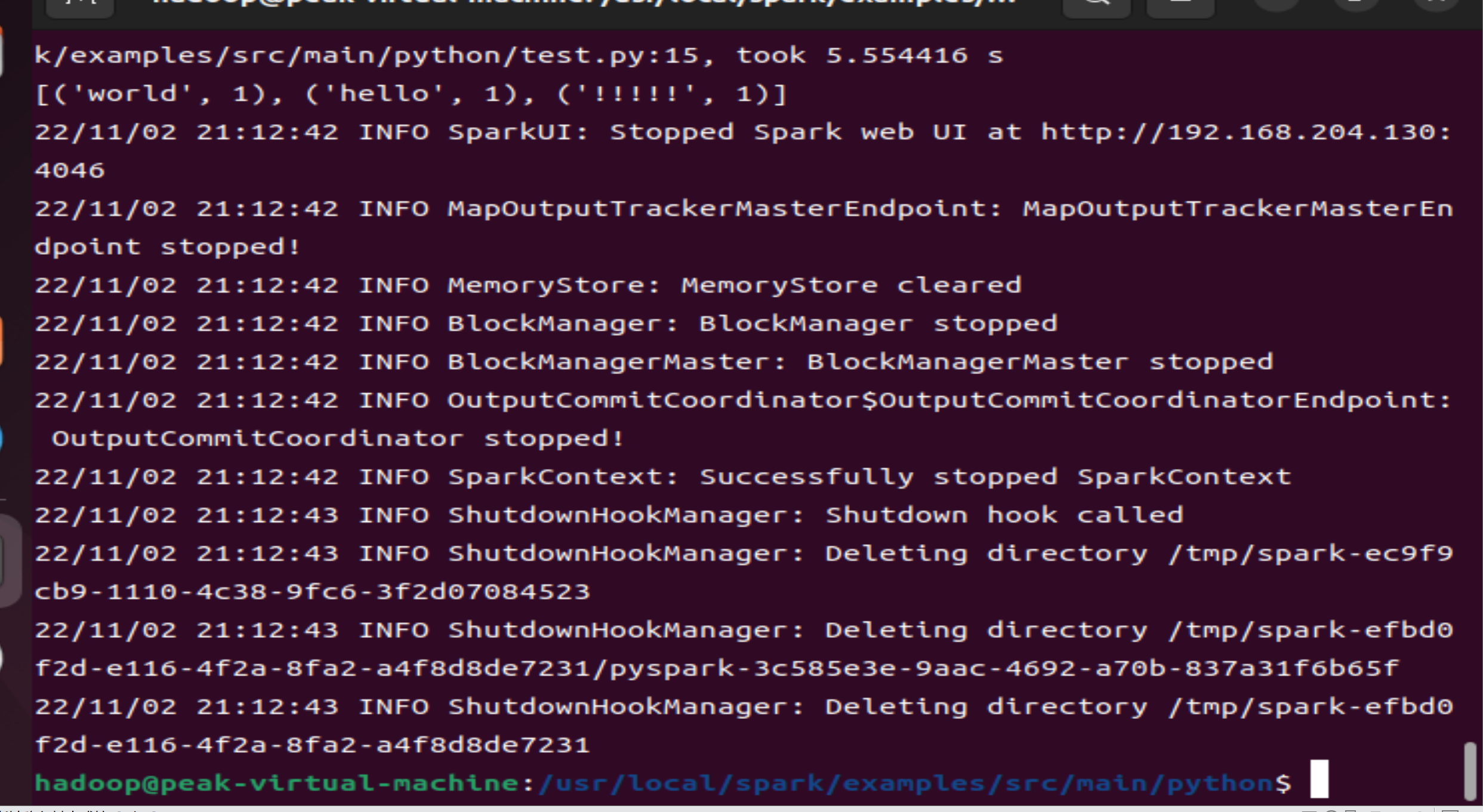
最终运行结果如下:

原文地址:http://www.cnblogs.com/peak213/p/16849460.html