
转载:https://www.cnblogs.com/imyalost/p/15889223.html
前言
我自己一直是专注在性能测试和稳定性保障领域的,因此买了很多相关的技术课程学习。
极客时间上赵成老师的《SRE实战手册》是线上稳定性保障领域很好的一门技术课程。
这篇文章是我将学习过程总结的内容还有部分自己的思考做了提炼总结,供大家参考。
课程链接

SRE背景
背景:互联网行业不断发展;
目的:提升用户价值交付效率;
措施:积极采用微服务、容器化及其他分布式技术产品,并且积极引入DevOps之类的先进理念;
优势:交付效率提升巨大;
挑战:复杂系统架构的稳定性很难得到保障;
最佳实践:业内稳定性领域的最佳实践是Google SRE;
1、SRE包含哪些工作事项
稳定性规范制定,监控、压测、服务治理、大促稳定性保障、故障应急和管理、组织架构建设;
2、SRE常见的问题与困惑

3、我们所看到的SRE
理念:SRE 到底是什么?我们应该怎么来理解它?有哪些关键点?
实践:到底应该从哪里入手建设 SRE?组织架构应该怎么匹配?
4、稳定性保障的切入点
切入点:稳定性保障的标准化!
跨团队部门沟通:没有共识、统一的稳定性衡量标准;
衡量稳定性的标准:SLO是稳定性保障的共识;
稳定性保障的核心:合理的组织架构可以有效应对各种稳定性问题!
5、DevOps和SRE的区别
DevOps核心是做全栈交付,SRE核心是稳定性保障,关注业务所有活动,两者共性是:都使用软件工程解决问题。
DevOps的诞生是由于互联网商业市场竞争加剧,企业为减少试错成本,往往仅推出最小可行产品,产品需要不断且高频的迭代来满足市场需求,抢占市场(产品的迭代是关乎一整条交付链的事)。
高频的迭代则会促使研发团队使用敏捷模式,敏捷模式下对运维的全栈交付能力要求更严格,则运维必须开启DevOps来实现全栈交付;
因为不断的迭代交付(也就是俗称的变更)是触发故障,非稳定性根源,而互联网产品/服务稳定性缺失会造成用户流失,甚至流到竞争对手那里, 因此关注业务稳定性也变得十分重要,SRE由此诞生。
如何理解SRE
1、SRE的定义
定义:SRE是一整套稳定性保障的最佳实践体系!
2、SRE认知误区
管理的角度: SRE就是一个具备全栈能力且能解决所有稳定性问题的岗位;
运维的角度:做好监控,快速发现问题、快速定位问题根因;
平台的角度:加强容量规划,学习Google做到完全自动化的弹性伸缩;
其他的角度:SRE传统运维的升级版,把运维自动化做好就行;
3、如何理解SRE
SRE稳定性保障规划图:

SRE是一整套稳定性保障的最佳实践体系,需要高效的跨团队组织协作才能完成。
从体系角度出发,需要将不同的技术结合起来,设置不同的职能岗位,制定让不同角色有效协作的机制,让体系发挥力量。而目前存在的一个痛点是角色和团队之间的协作相对独立,各自为战。
4、SRE根本目的
目的:提升稳定性,保障高效的用户价值交付。
通用衡量指标及计算公式:
MTBF(Mean Time Between Failure):平均故障时间间隔。
MTTR(Mean Time To Repair):故障平均修复时间。
提升稳定性的2个措施:提升故障时间间隔,降低故障修复时间,SRE也是以这两个指标为宗旨。
5、MTTR细分指标

6、不同阶段TODO项
Pre-MTBF阶段(无故障阶段):做好架构设计,提供限流、降级、熔断这些 Design-for-Failure 的服务治理手段,以具备故障快速隔离的条件;
还可以考虑引入混沌工程这样的故障模拟机制,在线上模拟故障,提前发现问题。
Post-MTBF(故障复盘阶段):上一故障结束开启新MTBF阶段,应该要做故障复盘,总结经验,找到不足,落地改进措施等。
MTTI阶段(故障发现响应阶段):依赖监控系统及时发现问题,对于复杂度较高和体量非常大的系统,要依赖 AIOps 的能力,提升告警准确率,做出精准的响应。
同时 AIOps 能力在大规模分布式系统中,在 MTTK 阶段也非常关键,因为我们在这个阶段需要确认根因,至少是根因的范围。
7、DevOps和SRE的协同
7.1:DevOps主要以驱动价值交付为主,搭建企业内部功效平台,SRE主要需要协调多团队合作来提高稳定性。如:
- 与开发和业务团队落实降级;
- 在开发和测试团队内推动混沌工程落地;
- 与开发团队定制可用性衡量标准;
- 与开发、测试、devops、产品团队,共同解决代码质量和需求之间的平衡问题;
7.2:SRE解决运维领域的故障目标,DevOps更偏向于为价值导向的效率目标,这是互相成就的一个过程。
在实践SRE过程中,不可避免要使用一些DevOps的技术,方法论,组织文化等,通过这些,达成一致目标。
7.4:DevOps整体的表现倾向于价值交付,与敏捷的价值观贴合;而SRE的侧重点在于保障系统的稳定运行,通过系统稳定性实现价值最大化!
两者有不同,也有交叉,他们不是非此即彼的选项。至于哪种更好,主要看团队的实际情况,产品本身所处的阶段,是另一个重要的考量依据!
7.5:devops目标是提升开发效率和提升交付效率,sre是保证服务稳定。devops针对的是交付产品和开发者,追求交付在产品的质量上的快。
系统可用性:故障≠稳定
业界常说的系统可用性(Availability)”3个9″、”4个9″,和建设SRE的目标强相关。SRE的稳定性目标就是尽量减少系统故障或异常运行状态的发生,提升系统可用的运行时间占比。
1、衡量可用性2种方式
一个是时间维度,一个是请求维度,计算公式如下:
时间维度:Availability=Uptime/(Uptime+Downtime):从故障角度出发对系统稳定性进行评估;
请求维度:Availability=Successful request/Total request:从成功请求占比角度出发,对系统稳定性进行评估;
2、衡量稳定性的三要素
衡量指标:如系统请求状态码;
衡量目标:如非5XX占比达到95%;
影响时长:如非5XX占比低于95%持续10分钟;
PS:上述案例只是从请求维度出发,加上时间维度,还有统计周期的因素需要考虑。
3、时长维度:可用性对照表
稳定性只与故障挂钩,粒度不够精细。
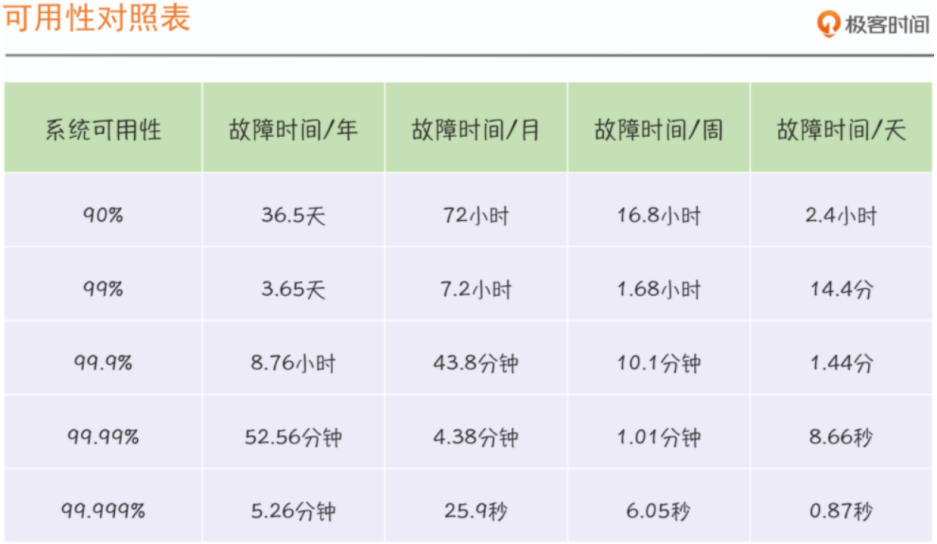
经验:故障一定意味着不稳定,但是不稳定,并不意味着一定有故障发生。
4、设定稳定性目标要考虑3个因素
成本因素:追求的指标越高,要求更多的资源冗余,需要综合考虑ROI来做平衡;
业务容忍度:核心业务——99.9%-99.99%;非核心业务——99%%+;
系统当前稳定性情况:合理的标准比更高的标准更重要!
SRE 关注的稳定性是系统整体运行状态,而不仅仅只关注故障状态下的稳定性,在系统运行过程中的任何异常,都会被纳入稳定性的评估范畴中,需要采用多维度的衡量指标和统计方式来评估。
原文地址:http://www.cnblogs.com/ceshi2016/p/16852889.html