
目前阶段
临近考试周,近期将在复习大四专业课的基础上,计划学习以下内容:
- 项目内容:自动化的清洗算子框架学习(了解SampleClean和进阶版本的ActiveClean)从中理解质量评估函数设计、阅读DataCleaning第六章
- 数理基础:吴恩达机器学习视频(重点学习)、知识图谱、随机算法与近似算法
- 编程基础:python、pySpark(重点学习)、Leetcode
- 其他:Latex、英语单词
【SampleClean】A Sample-and-Clean Framework for Fast and Accurate Query Processing on Dirty Data
摘要
由于处理和清理大型肮脏数据集的挑战,获得及时、高质量的汇总查询答案是很困难的。为了提高查询处理的速度,人们对基于抽样的近似查询处理(SAQP)重新产生了兴趣。然而,在其通常的表述中,SAQP根本没有解决数据清理问题,事实上,SAQP通过引入抽样误差,加剧了答案质量问题。SampleClean利用抽样来提高实际答案的质量,它将数据清洗应用于相对较小的数据子集,并使用清洗过程的结果来减少脏数据对总查询答案的影响。
方式
在本文中,探讨了抽样所带来的一个有趣的机会,即当与数据清理相结合时,抽样有可能提高答案的质量。我们提出了SampleClean,这是一个新颖的框架,只对数据的样本进行清理,以处理汇总查询(如avg、count、sum等)。从清理过的样本中估算出一个查询:(1)NormalizedSC:使用清理过的样本来纠正脏数据上查询结果的错误;(2)RawSC:直接根据清理过的样本来估算真实的查询结果。这两种方法都会返回无偏的查询结果和关于样本量的置信区间函数。比较这两种方法,NormalizedSC在误差较小的数据集上给出了更准确的结果,而RawSC对误差较大的数据集则更为稳健。
贡献
- 提出了SampleClean,它只需要用户清理一个数据样本,并利用清理后的样本来处理汇总查询。
- 提出了NormalizedSC,它可以使用清理过的样本 ple来纠正查询结果对未清理过的数据的偏差。
- 开发了RawSC,它可以使用清洗过的样本直接估计清洗过的数据的查询结果。
- 在真实和合成数据集上进行了广泛的实验。结果表明,估计值可以迅速向真实值靠拢,而清理的样本却少得惊人,与清理所有的数据相比,成本有了明显的提高,与不清理任何数据相比,准确性也有了明显的提高。
【SampleClean】SampleClean: Fast and Reliable Analytics on Dirty Data
摘要
在传统的AQP中,近似法必然会牺牲准确性来换取更快的时间。然而,SampleClean的目标与AQP不同,因为SampleClean以数据清洗成本换取查询精度的逐步提高。虽然SampleClean引入了近似误差,但数据清洗减轻了由于脏数据造成的偏差。这使得有一个平衡点:当有足够数量的数据被清理,以促进对清理后的数据进行准确的近似查询,在这个意义上,抽样实际上提高了查询结果的准确性。
方式
有两种截然不同的估计技术来解决每一个预算的数据清洗问题:直接估计(RawSC)和校正(NormalizedSC),具体看A Sample-and-Clean Framework for Fast and Accurate Query Processing on Dirty Data 上面那篇论文的总结。在这些方法之间有一个有趣的理论权衡:RawSC是稳健的,因为它的准确性与数据误差的大小无关,而NormalizedSC是有效的,因为它的准确性比直接估计的方法对样本大小的依赖更小。
数据清洗和AQP结合的相关工作
SampleClean :SampleClean使用干净数据的样本来估计集合(sum、count、avg)查询。SampleClean对数据进行重新加权,以补偿抽样统计的变化,从而使查询结果的估计保持无偏,并在置信区间内有一定的约束。
ViewClean:概括了数据清理的概念,包括对过时的视图进行昂贵的增量维护。物化视图(materialized views ,MV)的迟滞性表现为数据错误,即有缺失的、多余的和不正确的行。就像数据清理一样,急切的MV维护也很昂贵。从陈旧的MV中使用一小部分最新的数据样本来近似地进行汇总查询,结果是有限度的估计。
ActiveClean:ActiveClean将SampleClean扩展到一类称为凸数据分析的分析问题;包括SampleClean中研究的集合体,并包括机器学习,如支持向量机和线性回归。ActiveClean利用问题的凸形结构,优先清理可能影响模型的数据。
【Data Cleaning】Rule-Based Data Cleaning
在本章中,我们将讨论基于规则的技术去清洗有模式R的脏数据库I。我们假设已经为R规定了一套数据质量规则Σ。这可以通过要求领域专家手动策划一套规则,或采用自动发现算法来实现。由于I被认为是脏的,发现算法的目的是发现在数据的大多数部分都成立的 “近似 “数据质量规则。由于发现的数据质量规则会在I上过拟合,因此一般来说对R来说不是正确的质量规则,在使用它们进行数据清理之前,需要由领域专家验证任何发现的质量规则的正确性。
给定一个模式R的脏数据库实例I和一组质量规则Σ,基于规则的技术在两个主要步骤中清理I:违规检测,通过识别数据集中与规定的数据质量规则有关的违规行为来检测I中的错误,以及错误修复,更新输入数据以解决违规问题。本章将讨论执行这两个步骤的各种挑战和设计选择。
违规检测
检测错误是任何数据清理活动中必不可少的第一步。通过使用数据质量规则发现的错误通常被称为违规。对于没有存在量词的数据质量规则,一个常用的违规定义如下。”违规是一个不能共存的最小单元集”。我们可以从这个定义中推断出以下事实:
- 首先,并非所有违规的单元都是错误的。然而,其中至少有一个是错误的。
- 其次,构成违规的单元集合必须是最小的——从该集合中删除任何单元都会使更小的单元集合可以共存于一起而不违规。
- 最后,形成违规的单元集合中至少有一个单元必须被改变以解决违规问题。
违规检测存在多种挑战:
- 整体性:违规只说明一组单元不能同时存在,这组单元中的一些可能是正确的,一些可能是错误的。拆分单元格单独处理每个违规行为,将无法准确指出哪些单元是错误的;
- 追溯问题:数据通常需要经过多个阶段的处理,以达到最终的需求。虽然数据错误起源于源数据,但违规行为通常是在数据处理管道的后期发现的,在那里会有更多的业务逻辑。因此,在后期检测到的违规行为需要追溯到数据源中的错误;
- 成本问题:检测涉及k个图元的数据质量规则的违规行为需要从n个输入图元中列举出所有k个图元组合,当n很大时,这种多项式成本会变得非常高。
错误修复
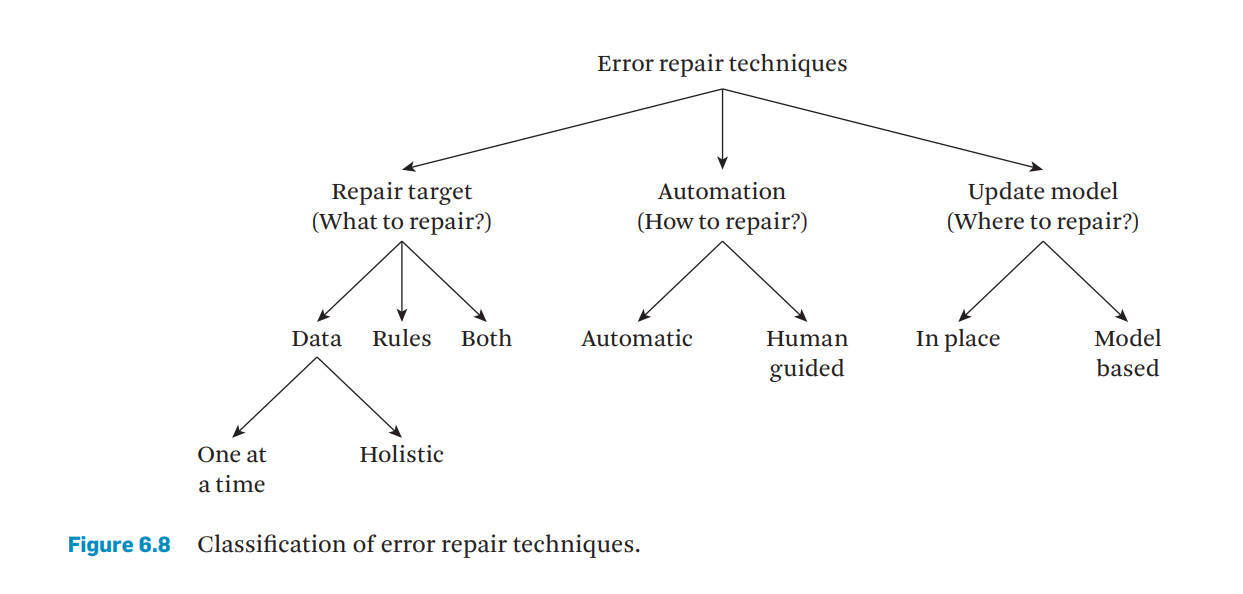
给出一个模式R的关系数据库实例I,它违反了某个数据质量规则;错误修复是指找到另一个符合该套数据质量规则的数据库实例I的过程。下图说明了数据修复技术的分类。
原文地址:http://www.cnblogs.com/zekaiblogs/p/16853090.html