
热度已经过了,但还是觉得有必要从架构设计的角度来讨论一下此事。并用以往我的经验来设计一套负载能力更好一些的系统。
先说一下基本的架构思路:
- 最大限度的避免计算,静态化
- 不用数据库,更新类操作使用APPEND模式的文本文件
- 流程最短,最好是客户端访问的第一台服务器就能完成全部工作
- 善用CDN
- 客户端负载均衡
需求分析
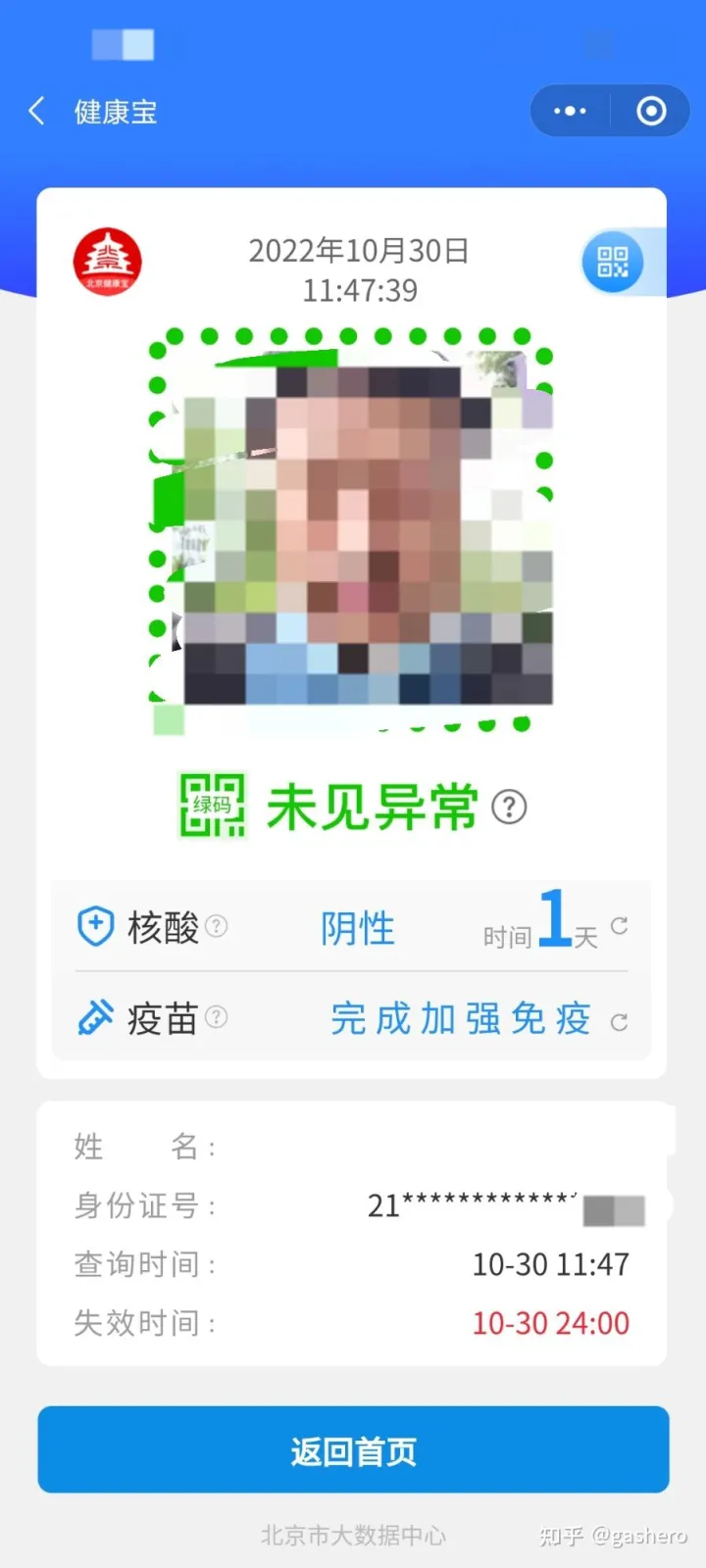
首先看一下北京>核酸的最高频使用场景。进入一个场所时,扫码登记,显示健康码状态。下图是我前些天的健康宝页面结果。
这个基本的操作分解为几个子操作:
- 扫码:通过调用URL将人访问过该地址的信息记录,以便有出现阳性时追访
- 获取当前人的健康码状态,显示到页面
页面中显示的字段信息包括:
- 健康码状态:绿码/黄码/红码等
- 最近一次核酸至今的时间:1天
- 疫苗接种情况
- 基本身份信息:姓名、身份证号
- 时间:查询时间,失效时间
常规设计思路与失效
一个只设计过常规MIS系统的工程师,满足如上需求的常规做法如下:
- 建立数据库,分别用几个表格来记录用户信息、核酸记录、疫苗记录、到访记录
- 用户扫码提交到访信息,就在到访记录表中INSERT一条新的记录
- 健康码页面的显示,依次去查询如上四个表来获取结果,其中后三个表需要排序后显示创建日期最新的记录
- 祭天,上线
然后遇到流量冲击,系统崩溃。崩溃的原因分为几个:
- 提交到访信息时,数据库只能承受几十到几千QPS的INSERT请求,对其他扫码请求无法处理,导致用户提交的请求失败
- 四个表的查询,对数据库造成了巨大的查询压力,数据库服务器LOAD爆了
资深架构师的改造思路
5-10年经验的工程师/架构师的典型改造思路:
- 数据库横向拆表到多个数据库服务器,每个数据库按照一定的负载均衡逻辑,只保留一部分数据,比如用户ID整除10后的余数,分布到10台数据库。于是工程师熬夜加班,确保查询时会根据负载均衡逻辑去正确的服务器查询,提交到访记录时也会INSERT到正确的服务器
- 入口加负载均衡,DNS解析到多个机房的入口Load Balance,然后Load Balance再随机分派给多台后端服务器,多堆服务器提高处理能力
- 数据冗余降压力:把最新一条的核酸记录、疫苗记录,作为冗余字段写入到用户表里,这样显示健康宝页面时就少查询了两个表
- 查询时间、失效时间,两个字段在客户端生成,不问数据库要
- 搞个消息队列,先返回给用户查询中,等个未知的时间都算完了再返回
通过这样一套操作下来,整个系统的负载能力能获得几十倍到几百倍的提高。
但很不幸,有些时候就是会有数千倍甚至数万倍的流量涌过来。
首问负责制
想要更强的负载能力,就需要若干改造思路。
所谓首问负责制,是让用户的请求尽量在第一个服务器就得到全部的满足。如果不行,也要尽最大能力降低完成一个请求经历的服务器数量。网络通常是整个系统里最慢的部分,服务器之间的互相调用也会严重的影响系统负载能力。
所以目标就是,让用户访问的第一台服务器就完成提交到访记录、获取用户健康宝全部信息。
到访记录,扔掉数据库,用文件
用户到访记录,是个写入操作,是严重的系统瓶颈。解决办法就是不用数据库,用文件来存储到访记录。
例如我们在首问服务器上建立一个文本文件,用文件系统级的锁来保护防止并发写入。每当有用户请求时,就用APPEND模式,在该文件的末尾添加一行到访记录,比如{“UserID”:userID,”PlaceID”:PlaceID}。这样的性能相比数据库会有数十倍的提高。如果数据库为了查询方便而引入了索引,则会快更多。
每天生成的数据文件则收纳起来备份存储。
必然有读者问,写入文件了,还怎么查询。
首先查询到访记录是个低频需求。每个人都需要写入,但没有发现阳性要进行排查时是不需要进行查询的。另外当需要查询时,可以在收纳起来的存储里,用grep来进行查询。这样可以分别指定UserID或PlaceID来获得结果。以及用另一套方式来在各个首问服务器上用grep查询实时的到访记录。
把数据库查询变成了文本文件的字符串查询,虽然查询复杂度变成了线性的,但因为单个记录变得极小,只有小几十个字节,按64字节计算。查询速度还是回比数据库快很多倍。
用户信息KV库
用户信息的库也可以扔掉数据库。用上一节类似的方式,把核酸记录和疫苗记录表,全都变成数据文件。而且核酸记录和疫苗记录的文件也不会被频繁查询,因为可以将其最新一条同样冗余记录到用户信息表里。
而用户信息表则是用文件的方式记录。每个用户一个JSON文件,文件名对应UserID,文件内容里包含该用户的姓名、身份证号、最新一次核酸日期/结果、最新一次疫苗日期。然后该服务器把全部的用户信息文件组织起来放在文件系统里。简单的办法是用btrfs等文件系统,把全部用户的JSON文件都放在一个目录里。或者用古典的办法,把UserID分成每2或3个字符一段,建立多层目录来存储,避免单个目录里文件过多。
总之,客户端知道自己的UserID,而通过UserID可以轻易的定位到服务器上的用户信息JSON文件。一个用户的信息内容是很少的,按256字节算。1亿用户需要存储空间约为25GB,这点容量显然每台服务器上都存一份是可行的。而且每个服务器(虚拟机)给分的内存大一点,还能让这些数据库都处在文件系统缓存中,获得与内存相同的速度,比SSD更快。
用户的核酸和疫苗信息更新是低频需求,一个3000万人的城市,每天3000万次请求顶天了。这点请求量可以轻易用一台服务器来管理全部人的用户信息JSON文件。然后同步到各个首问服务器提供查询。因为每个首问服务器都包含了全部用户的信息,所以连资深架构师的后端负载均衡都免了。
全部用户的信息,可以考虑用rsync之类的,来从中心服务器同步到各个首问服务器,也可以考虑打包成zip文件、BerkeleyDB之类的,来提供整体更新。用分开的文件方式的妙用更大。
到这一步,事实上客户端访问自己的健康宝信息,就已经变成了一次请求的两步操作。第一步在到访记录文件里加一行记录,第二步是返回用户信息JSON文件。已经可以实现首问服务器的直接响应了。而做到这一步,就能实现了比最初设计数百倍到上千倍的性能提升。
使用大杀器CDN
如上的改造已经可以把所有现存服务器的性能发挥到机制,大概率此时的瓶颈在于服务器带宽。CPU、内存、SSD IO大概率全都用不满,但服务器的带宽用满了。以现代这些服务器的性能,每台服务器跑满10Gbps的带宽来满足这些需求都没啥问题。
假定每个请求的网络通信为16KB。那么10Gbps可以到625,000 qps,或者说每秒完成62.5万人的扫码和获取健康宝信息。3000万人的查询,也就是48秒的事情。原则上单台服务器就足以满足一个3000万人城市的健康宝查询需求了。这625,000qps的请求,实际的SSD写入按之前的64Byte,读取按256Byte计算。对应了写入速度40MB/s,读取速度160MB/s,SSD表示加上读取索引和文件系统缓存,还是很轻松的。
但更变态一点,如果我们需要更大的系统容量,可以轻易满足全世界70亿人的健康宝系统呢?
首问服务器的业务在设计时就拥有良好的横向扩展能力。但带宽就成了问题,简单的解决办法是引入CDN。我们的业务已经变成了URL里给出UserID就能获取JSON的样子了。这对CDN来说简直是太完美的需求了。源站可以在HTTP里开启etag,这样没更新的用户JSON数据就可以返回304给CDN的溯源请求,有更新的则可以轻易的同步给CDN。CDN的缓存时长可以设置为1分钟之类的。
客户端也可以设置负载均衡策略,确保访问服务器时优先问自己轮巡的CDN。比如自己的UserID尾号是1,那么就总是访问域名尾号里带有1的CDN域名,这样可以使得CDN服务器的缓存命中率获得极大的提高,减小了缓存溅出和溯源的压力。
阿里云CDN的总带宽是150Tbps。结合我们单台服务器按10Gbps处理,可以容纳15000台服务器的服务能力。或者说请求处理能力9,375,000,000 qps,或者说每秒可以完成93.75亿人的健康宝查询请求。这差不多就够了。
小结
2011年,我就是使用了如上方法的一部份,在果壳网的一次推广活动中轻易顶住了压力。彼时的果壳网已经有了近10台服务器,但因为压力没那么大,所以平时主要就两台服务器在处理请求。日常每天20万PV,30M的BGP带宽。而那次推广活动当天涌来了470万PV,请求量比平时增加了23.5倍,高峰带宽跑到1G多。但最终这些请求在这些架构和CDN带宽的支持下,非常轻松的顶了过去。
缩短计算流程,用数据文件替代数据库,使用CDN,把这些技巧用好,用来应付大流量系统是很好用的。仔细分析如上的架构设计可知,负责响应用户请求的部份甚至不需要编程,而是用良好配置的nginx就够了。而数据同步,各类搜索则是可以用python脚本方便的实现,瓶颈在IO上,也根本凸显不出各种语言的性能差异。良好的架构设计来极大的降低编码实现的工作量,并几十上百倍的提高系统性能,是享受架构设计乐趣的好方式。

作者:gashero
原文地址:http://www.cnblogs.com/88223100/p/How-hard-it-is-to-make-a-nucleic-acid-system-that-doesnt-collapse.html