
Linux第十二章——块设备I/O和缓冲区管理
块设备I/O缓冲区
- 读写普通文件的算法依赖于两个关键操作,即:get_block和put_block,这两个操作将磁盘块读写到内存缓冲区中。
- I/O缓冲的基本原理非常简单。文件系统使用一系列I/O缓冲区作为块设备的缓存内存。
- 在讨论缓冲区管理算法之前,我们先来介绍以下术语:定义一个bread(dev,blk)函数,它会返回一个包含有效数据的缓冲区(指针)
从磁盘块中读取
点击查看代码
BUFFER *BREAD(dev,blk)
{
BUFFER *bp = gerblk(dev,blk);
if (bp data valid)
return bp;
bp -> opcode = READ;
start_io(bp);
wait for I/O completion;
return bp;
}
写入磁盘块
1、同步写入——同步写入等待写操作完成,用于顺序块或可移动设备
点击查看代码
bwrite (BUFFER *bp){
bp->opcode = WRITE;
start_io(bp);
wait for I/O completion;
brelse(bp);
}
2、延迟写入——延迟写入无写操作,用于随机访问设备
点击查看代码
dwrite(BUFFER *bp){
mark bp dirty for delay_write;
brelse(bp);
}
3、同步写入操作等待写操作完成。它用于顺序块或可移动块设备,对于随机访问设备,例如硬盘,所有的写操作都是延迟写操作。在延迟写操作中,dwrite(dp)将缓冲区标记为脏,并将其释放到缓冲区缓存中。
脏缓冲区只有在被重新分配到不同的磁盘块时才会被写入磁盘,此时缓冲区将被以下代码写入:
点击查看代码
awrite(BUFFER *bp){
bp -> opcode = ASYNC;
start_io(bp);
}
- 脏缓冲区只用在重新分配到不同的磁盘块时才会被写入磁盘
- awrite()会调用start_io()在缓冲区开始I/O操作,但不会等待操作完成
- 当异步ASYNC完成后,磁盘中断处理程序将释放缓冲区
Unix I/O缓冲区管理算法
缓冲区组成
- I/O缓冲区:内核中的一系列NBUF缓冲区用作缓冲区缓存。每个缓冲区用一个结构体表示。缓冲区结构体由两部分组成:用于缓冲区管理的缓冲头部分和用于数据块的数据部分。
- 设备表:每个块设备用一个设备表结构表示。每个设备表都有一个dev_lise,包含当前分配给该设备的I/O缓冲区,还有一个io_queue,包含设备上等待I/O操作的缓冲区。
- 缓冲区初始化:当系统启动时,所有I/O缓冲区都在空闲列表中,所有设备列表和I/O队列均为空。
- 缓冲区列表:当缓冲区分配给(dev,blk)时,它会被插入设备表的dev_list中。
- Unix getblk/brelse算法
关于Unix算法
- Unix算法具有数据一致性:为了确保数据一致性,getblk一定不能给同一个(dev,blk)分配多个缓冲区。
- Unix算法的缓存效果可通过以下方法实现。释放的缓冲区保留在设备列表中,以便可能重用。标记为延迟写入的缓冲区不会立即产生I/O,并且可以重用。缓冲区会被释放到空闲列表的末尾,但分配是从空闲列表的前面开始的。
- 设备中断处理程序可操作缓冲区列表,例如从设备表的I/O队列中删除bp,更改其状态并调用brelse(bp)。
- Unix算法有以下缺点:
- 效率低下:该算法依赖于重试循环。
- 缓存效果不可预知:在Unix算法中,每个释放的缓冲区都可被获取。
- 可能会出现饥饿:Unix算法基于“自由经济”原则,即每个进程都有尝试的机会,但不能保证成功。
- 该算法使用只适用于单处理器系统的休眠/唤醒操作。
缓冲区结构体
点击查看代码
typdef struct buf{
struct buf *next_free;
struct buf *next_dev;
int dev,blk;
int opcode;
int dirty;
int async;
int valid;
int busy;
int wanted;
struct semaphore lock = 1;
struct semaphore iodone = 0;
char buf[BLKSIZE];
}BUFFER;
BUFFER buf[NBUF], *freelist;
设备表
点击查看代码
struct devtab{
u16 dev;
BUFFER *dev_list;
BUFFER *io_queue;
}devtab[NDEV];
优化缓冲区管理算法
新的I/O缓冲区管理算法
在信号量上使用P/V来实现进程同步,而不是使用休眠/唤醒。
- 信号量有以下优点:计数信号量可用来表示可用资源的数量;当多个进程等待一个资源时,信号量上的V操作只会释放只会释放一个等待进程,该进程不必重试,因为它保证拥有资源
信号量定义
点击查看代码
BUFFER buf[NBUF];
SEMAPHORE free = NBUF;
SEMAPHORE buf[i].sem = 1;
PV算法
使用计数信号量上的P/V来设计满足以下要求的新的缓冲区管理算法:
- 保证数据一致性
- 良好的缓存效果
- 高效率:没有重试循环,没有不必要的进程“唤醒”
- 无死锁和饥饿
PV算法伪代码
点击查看代码
BUFFER *getblk(dev,blk)
{
while(1){
p(free);
if (bp in dev_list){
if (bp not BUSY){
remove from freelist;
P(bp);
return bp;
}
//bp in cache but BUSY
V(free);
P(bp);
return bp;
}
//bp not in cache, try to create a bp=(dev.blk)
bp = first buffer taken out of freelist;
P(bp);
if (bp dirty){
awrite(bp);
continue;
}
reassign bp to (dev,blk);
return bp;
}
}
brelse (BUFFER *bp)
{
if (bp queue has waiter) {
V(bp);
return;
}
if (bp dirty && freee queue has waiter){
awrite(bp);
return;
}
enter bp into (tail of) freelist;
V(bp);
V(free);
}
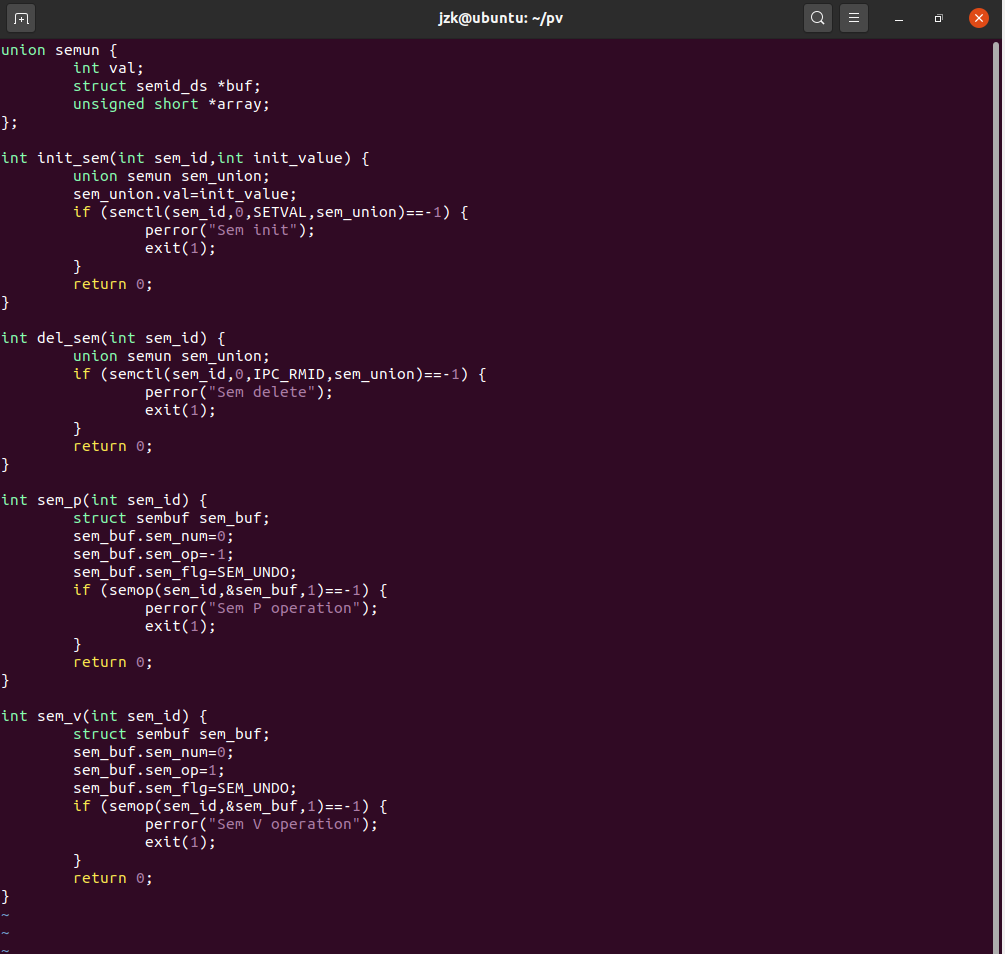
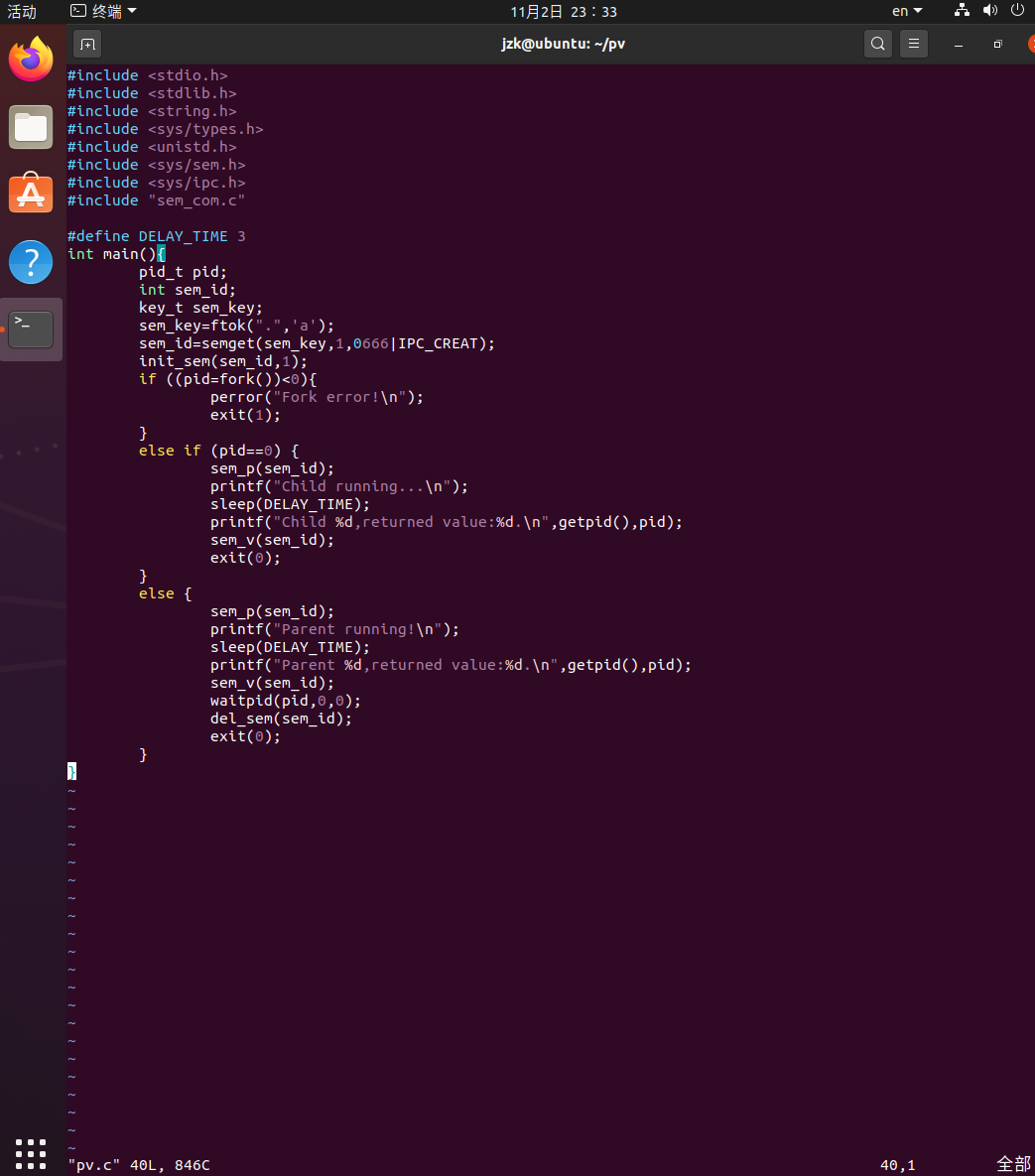
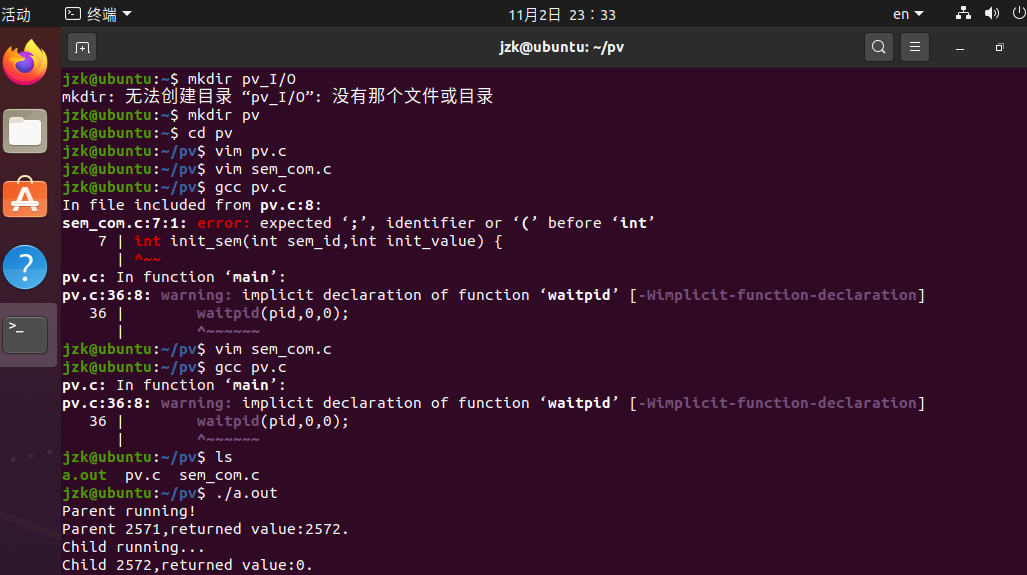
实践
PV信号量缓冲区算法
原文地址:http://www.cnblogs.com/wafmr-123/p/16854398.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性