
这周看了一篇论文,该篇论文发自2022的coling,论文的题目为:ArgLegalSumm: Improving Abstractive Summarization of Legal Documents with Argument Mining ,即利用论点挖掘改进法律文件的抽象摘要。
法律案例包含在长文本中传播的隐式论证结构,但是目前的抽象摘要模型没有考虑到文本的论证结构,所以这篇论文为解决在生成法律文件的摘要时的争论问题,本论文通过将论点角色标记集成到总结过程中,来捕获法律文档的论证结构。
具体过程如下:
将摘要过程分解为两个任务。首先,文档中的每一个句子都使用一个独立的模型来分配一个论点角色。然后,将预测的角色与原始文档的句子混合,并输入一个基于序列的抽象摘要器。
过程如下图所示:
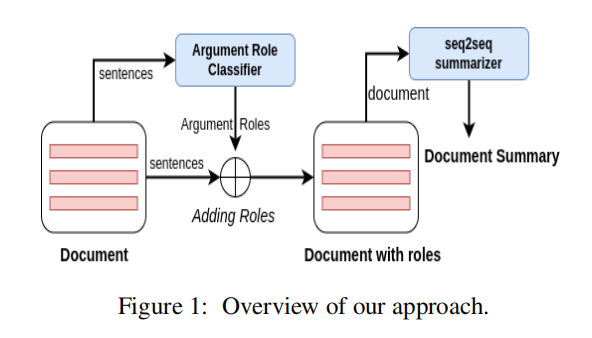
论点挖掘:
在该篇论文的任务中,论点挖掘的目的是在包含论点角色及其相互关系的图形结构中表示文本的争论结构。构造图通常包括几个步骤:提取论点单元,对单元的论点角色进行分类,以及检测不同论点角色之间的关系。这篇论文将法律文件中的论点角色分类为符合法律文本结构的问题、原因和结论。
数据集:
1262个法律案例以及与加拿大法律信息研究所达成的协议获得的摘要对。
方法:
方法一:手动标注
进行标注,首先,引入<IRC>,</IRC>来区分争论和非辩论句。其次,为区分问题、原因和结论这三个参数角色,为每个参数角色分配了两个唯一的标记(开始和结束标记)来突出显示它在文本中的边界。
方法二:句子级的论点角色挖掘
使用三种模型,分别为BERT,RoBERTa和legalBERT来预测句子的论证角色(问题、原因、结论或非论证角色)。其中,legalBERT的效果最好。
结论:
包含论点角色信息可以提高能够处理长文档的总结模型的ROUGE分数。具体来说,使用Longfrome实现了改进的结果,这一发现在两个特殊标注方案中是稳健的。还表明,使用预测的论点角色与使用手动标记的论点角色相比有一致的改进。
原文地址:http://www.cnblogs.com/qiqi-yi/p/16855731.html