
1.爬取豆瓣排名前250的电影,打开https://movie.douban.com/top250
豆瓣的数据都在HTML中
2.分析url是如何变化的并提取有用的url
发现是Get请求
第二页可见地址栏第二页的url:https://movie.douban.com/top250?start=25&filter=
以此类推,
第三页:https://movie.douban.com/top250?start=50&filter=
第四页:https://movie.douban.com/top250?start=75&filter=
……
第十页:https://movie.douban.com/top250?start=225&filter=
由此推测,第一页的url是https://movie.douban.com/top250?start=0&filter=
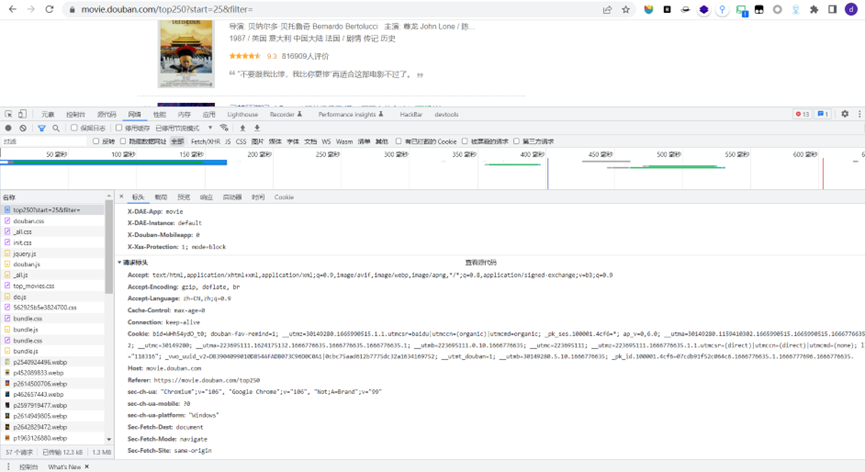
进入第一页,按F12进入开发者模式,network–all–top250?start=0&filter=–headers,获取url,和requests方法。
# 请求url
url = https://movie.douban.com/top250?start=0&filter=
# 请求方式为get,所以用requests.get,请求url获得响应
response = requests.get(url)
提取有用数据,用网页解析器beautifulsoup
# 第一个参数是要解析的内容,第二个参数是解析器
bs = BeautifulSoup(response .text, ‘html.parser’)
寻找有用数据
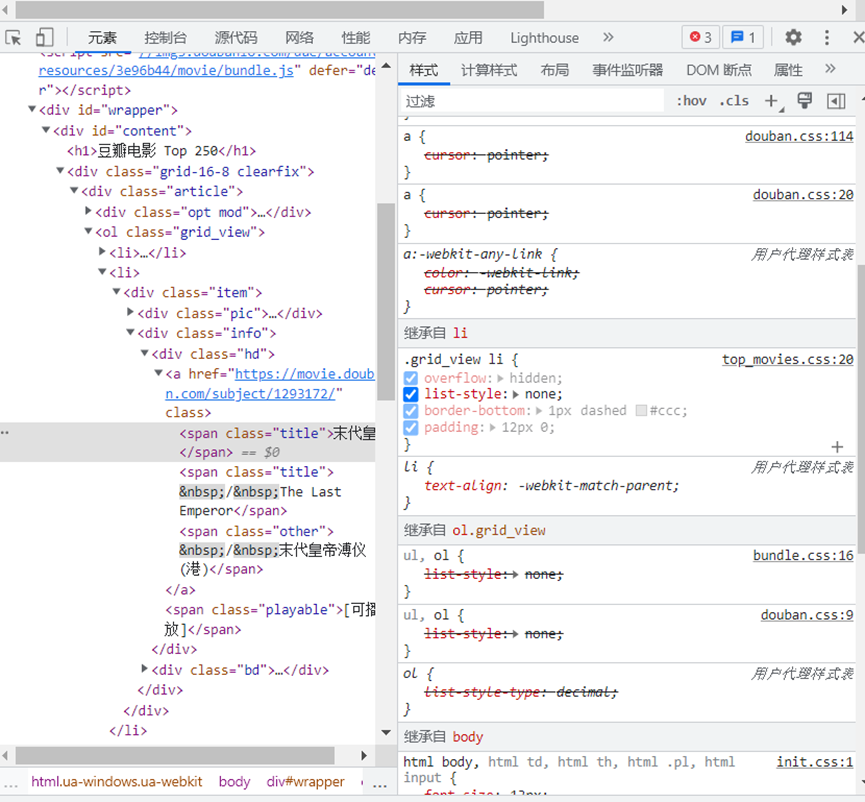
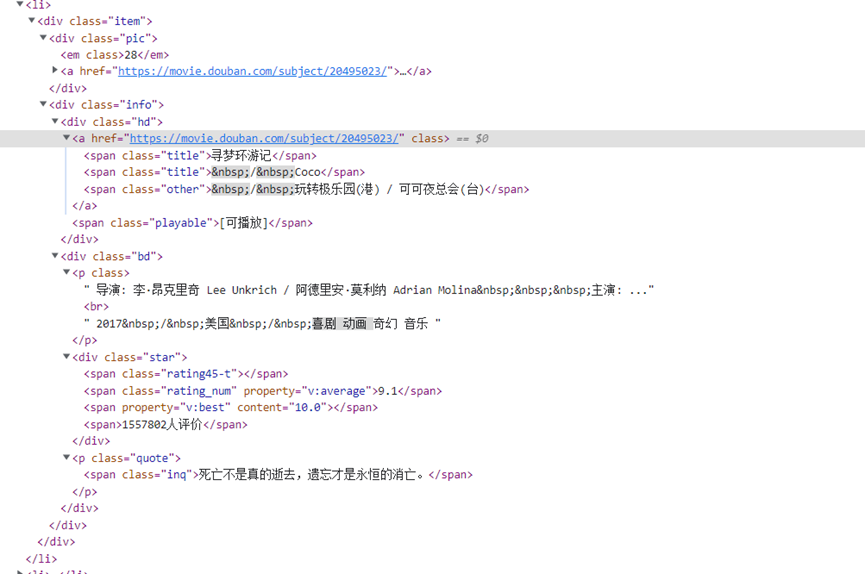
如下图我们可以知道:
每一个电影名字都是在span,class的值title里面,而且每一个电影数据都放在一个li里
li可能有很多,找它的父元素ol,ol可能有很多,找它的class。
因此,先找类样式为grid_view的ol,再找ol中的所有li
beautifulsoup的语法:对象名.find(标签, 属性),对象名.find_all(标签, 属性)
for循环遍历li获取所需数据:序号,标题,评分,推荐语,电影url
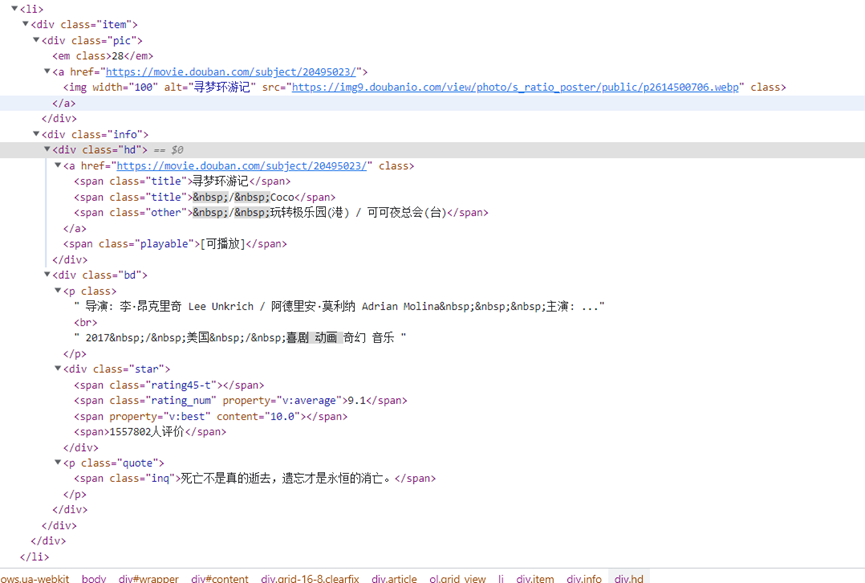
随意打开一个电影的数据li元素,可以找到信息所在标签和属性值(如下图)
比如说:电影序列号在em标签,电影标题标签为span,class=title等
# 获取序号
no = item.find(’em’).text
# 获取标题
title = item.find(‘span’, class_=’title’).text
#获取推荐语
inq = item.find(‘span’, class_=’inq’).text
# 获取评分
rat = item.find(‘span’, class_=’rating_num’).text
# 获取电影url
url_films = item.find(‘a’)[‘href’]
爬取后保存数据将其以excel的方式导出
存储数据先定义一个变量lst用于存储数据,再将数据存储Excel中,要用到openpyxl
具体注释看代码附件。
结果
结果如下

完整代码及注释如下
import requests from bs4 import BeautifulSoup import openpyxl headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36' } #设置请求头 lst=[['编号', '名称', '推荐语', '评分', '链接地址']] #定义变量lst,Excel第一行数据为'编号', '名称', '推荐语', '评分', '链接地址' for i in range(10): #for 遍历十次爬取前250的数据 url = 'https://movie.douban.com/top250?start='+str(i*25)+'&filter=' #根据每页url的变化规律,start=(页数-1)*25 要获取10页数据,编写循环 response = requests.get(url, headers=headers) #requests.get,请求url获得响应,添加请求头伪装成浏览器 bs = BeautifulSoup(response.text, 'html.parser') # 第一个参数是要解析的内容,第二个参数是解析器 grid_view = bs.find('ol', class_='grid_view') # 找类样式为grid_view的ol all_li = grid_view.find_all('li') # 找ol中的所有li for item in all_li: no = item.find('em').text #获取电影序号 title = item.find('span', class_='title').text #获取标题 #删去.text inq = item.find('span', class_='inq') #获取推荐语 rat = item.find('span', class_='rating_num').text #获取评分 url_films = item.find('a')['href'] #获取电影url lst.append([no, title, inq.text if inq!=None else' ', rat, url_films]) # 添加判断电影有没有推荐语,ture 则赋值inq,否则为空 wb = openpyxl.Workbook() # 先创建一个工作簿xlsx sheet = wb.active # 创建工作表sheet sheet.title = '我的电影' for item in lst: # 遍历列表中的数据,将数据添加到工作表中 sheet.append(item) wb.save('Hndreamer_films.xlsx') #保存命名为Hndreamer_films.xlsx
原文地址:http://www.cnblogs.com/hndreamer/p/16857752.html