
Redundant Arrays of Inexpensive Disks (RAIDs)
带着问题学习:如何制作容量大、速度快、可靠的磁盘?
解决上述问题使用了一种技术叫做Redundant Array of Inexpensive Disks(RAID):协同使用多个磁盘。
RAIDs相对于单个磁盘有如下几点优势:
- 性能(performance)
- 容量(capacity)
- 可靠性(reliability)
RAIDs对使用它们的系统透明地(transparently)提供了这些优势,对于宿主系统而言一个RAID看起来就像一个磁盘。透明性提高了RAID的可部署性,使使用者和管理员使用RAID不需要担心软件兼容问题。
1. Interface And RAID Internals
当文件系统向RAID发出一个逻辑I/O请求,RAID内部必须计算获取哪个(些)磁盘响应这个请求,然后发出一个或多个物理I/O请求完成这个请求。举一个简单的例子,考虑一个RAID,该RAID保留每个块的两个副本(每个副本在单独的磁盘上);在写入此类镜像RAID系统时,RAID必须为发出的每个逻辑I/O执行两个物理I/O。
一个RAID系统通常情况下被设计成一个单独的硬件盒,通过标准(SCSI或SATA)与主机连接。但是在RAID内部却相当复杂,有运行固件以指导RAID操作的微控制器;用于在读写数据块时对其进行缓冲的诸如DRAM之类的易失性存储器;在某些情况下,非易失性存储器可以安全地缓冲写入操作,甚至可以使用专门的逻辑来执行奇偶校验计算。
从较高层次上讲,RAID是一个非常特殊的计算机系统,它有处理器、存储器和磁盘。但是,它不是运行应用程序,而是运行专门用于操作RAID的软件。
2. Fault Model
要了解RAID并比较不同方法的优劣,我们必须知道故障模型。RAID旨在检测特定类型的的磁盘故障并从中恢复。因此,准确知道预期的故障对于实现可行的设计至关重要。
第一个故障模型相当简单,叫做fail-stop故障模型。在这个模型中,一个磁盘能有确定的两个状态中的一个:能工作(working)或者已失效(failed)。
这个故障模型一个至关重要的点就是它关于故障侦测的假设:当一个磁盘失效后,它非常容易检测到。因此,在这个模型中,我们不需要关心更复杂的故障问题。
3. How To Evaluate A RAID
构建RAID有多种不同的方法,这些方法中的每一种有不同的特征,为了了解每一种方法的优缺点,我们需要了解每一种方法的特征。
上述我们也提到过,评估RAID设计优劣有三个指标:
- capacity。N个磁盘,每个磁盘有B块,不使用冗余阵列,可用容量为N * B;如果我们使用RAID保留每个块的两个副本,那么可用容量就为(N * B)/ 2。
- reliability。给定的设计可以容忍多少磁盘故障?
- performance。性能评估在某种程序上具有挑战性,因为它很大程序上取决于提供给磁盘阵列的工作负载。
我们将重点考虑三个RAID设计:
- RAID Level 0 (striping)
- RAID Level 1 (mirroring)
- RAID Levels 4/5 (parity-based redundancy)
4. RAID Level 0: Striping
RAID Level 0根本不是RAID级别,因为没有冗余。但是它的条带化(striping)是性能和容量的极佳上限,因此值得我们了解。
如果对条带化不清楚,可以看看这篇文章理解磁盘条带化
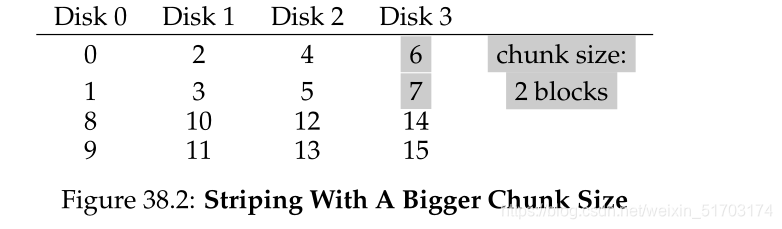
最简单的条带化技术看如下的例子,假设有4个磁盘阵列:

上图的中心思想:以循环方式在磁盘上分布阵列的块。
我们称在同一行的块为条带(stripe),故块0、1、2和3都在同一条带中。
上图我们假设同一条带中每个磁盘只有一个块。我们也可以假设多个块,如下所示:
在研究评估RAID三个指标之前,我们需要知道给一个逻辑块读写请求,RAID如何知道获取哪个物理磁盘和块偏移量去完成这个请求?
假设有个逻辑块A,那么物理磁盘和块偏移量可以如下计算:

4.1 Chunk Sizes
块大小(chunk size)主要影响阵列的性能。例如,一个小的块大小意味着许多文件将跨多个磁盘进行跳转,从而增加了对单个文件的读写并行性,但是,跨多个磁盘访问块的定位时间会增加,因为整个请求的定位时间取决于所有驱动器上请求的最大定位时间;块大了,会减少文件内并发性,因此依赖多个并发请求来实现高吞吐量,但是,定位时间减少了。
块太小了不好,块太大了也不好,所以决定块的大小是很困难的事情。

对于我们接下来要讨论的问题,块的大小无关紧要。故为了便于我们理解研究,我们假设块大小为4KB。
4.2 Back To RAID-0 Analysis
开始对RAID-0进行评估:
- 容量很完美,N个磁盘,每个磁盘B个块,容量为N * B
- 可靠性完美,但是任何磁盘失效都会导致数据丢失
- 性能优秀,所有磁盘通常并行使用,以服务用户I/O请求
4.3 Evaluating RAID Performance
在评估RAID性能时,有两种不同的指标:
- 单请求延迟(single-request latency):在单个逻辑I/O请求中可以存在多少并行性
- 稳态吞吐量(steady-state throughput):许多并发请求的总带宽
由于RAID经常在高性能环境中使用,所以稳态带宽至关重要,这也是我们主要分析对象。
为了更好地理解吞吐量,我们需要提出一些有趣的工作负载:
- 顺序(sequential):对数组的请求来自连续的大块
- 随机(random):每个请求都很小,并且每个请求都位于磁盘上的另一个随机位置
当然,真实的工作负载经常是这两种工作负载的混合,为了简单化,我们仅考虑这两种单独的方法。
顺序工作负载:磁盘已其最高效的模式运行,花费很少的时间寻找和等待旋转,并且大部分时间用于传输数据。
随机工作负载:大部分时间都花在寻找和等待轮换上,而花费的时间却很少。
在我们的分析中为了捕获差异,我们假设磁盘在顺序工作负载下以S MB/s传输速率,在随机工作负载下以R MB/s传输数据。(通常情况下,S >> R)
让我们做些练习更好理解差异。计算S和R在给定的条件:假设平均大小为10MB的顺序传输,平均大小为10KB的随机传输,另外,假定如下特征:

计算S:首先花费7ms寻找时间,然后3ms旋转延迟,最后,传输开始。
传输时间 = 10MB / (50MB/s) = 0.2s = 200ms
故完成该请求总花费时间 = 210ms
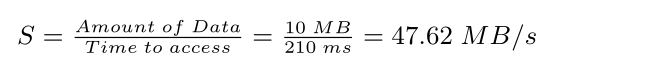
计算R:花费7ms寻找时间,然后3ms旋转延迟,最后传输开始。
传输时间 = 10KB / (50MB/s) = 0.195ms
故完成该请求总花费时间 = 10.195ms
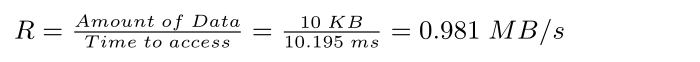
4.4 Back To RAID-0 Analysis, Again
让我们再来评估RAID-0的性能。
从单延迟请求来看,与单个磁盘的等待时间几乎相同;从稳态顺序吞吐量来看,可以获得系统的全部带宽。对于大量随机I/O,可以再次使用所有磁盘,也是全部带宽。
5. RAID Level 1: Mirroring
镜像系统(mirrored system):每个块不止一个副本,每个副本应该放在不同的磁盘,能够容忍磁盘失效。
假设对于每个逻辑块,RAID保存两个物理副本。如下所示:

上面是一种常见的磁盘块安排,叫做RAID-10(或RAID 1+0,镜像带),因为它使用了镜像对(RAID-1),然后在它们之上使用了带区(RAID-0);还有一种方法叫做RAID-01(或RAID 0+1,条带镜像),先条带化,然后再镜像。
当读一个块的内容时,RAID有两种选择;当写入数据时,RAID必须将对应的所有副本块更新。
5.1 RAID-1 Analysis
开始对RAID-1进行评估:
- 从容量来看,RAID-1是昂贵的。由于镜像等级为2,故N个磁盘,每个磁盘B块的容量只有(N * B) / 2
- 从可靠性来看,RAID-1很好。它能够容忍一个副本磁盘的失效(镜像等级为2)
- 从单请求延迟来看,单个读请求的延迟与单个磁盘上的延迟相同;但对于写请求,由于要更新两个副本,遭受了最欢情况下的寻道时间和旋转延迟,因此比单个磁盘的写入要高。
- 从稳态吞吐量来看,顺序读取仅仅提供了一般的带宽;随机读取可以获得全部带宽。
在分析RAID-1之前,我们需要解决一个问题:RAID一致性更新问题(consistent-update problem)。
由于向磁盘中写入数据需要同时更新所有副本的内容,那么假设镜像等级为2,将写操作发送给RAID,然后RAID必须将数据写到两个磁盘(磁盘0和磁盘1)。当RAID向磁盘发出写请求之前发生断电或系统崩溃。在这种情况下,假设对磁盘0的请求已完成,但对磁盘1的请求未完成,这就导致了两个磁盘的副本不一致。
解决这个问题的一般方法是在执行某种操作前,先使用某种类型的预写日志记录RAID即将执行的操作。通过这种方法,可以确保在发生崩溃的情况下进行正确的处理。
6. RAID Level 4: Saving Space With Parity
现在介绍另一种向磁盘阵列添加冗余的方法:奇偶校验(parity)。基于奇偶校验的方法尝试使用较少的容量,从而克服了镜像系统所付出的巨大空间损失,但是付出了性能的代价。

上图是5个磁盘的RAID-4系统。对于每个数据条带,添加了一个奇偶检验块,该奇偶校验块存储该数据条带的冗余信息。例如,P1具有从块4、5、6、7计算出的冗余信息。
要计算奇偶检验,简单的XOR可以很好地解决这个问题。对于给定的一组位,如果这些位中1的个数为偶数,则所有这些位的XOR返回0;如果个数为奇数,则返回1。如下所示:
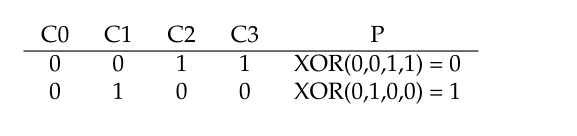
上述情况表明:包括奇偶检验位在内的任何行中的1的数目必须是偶数,这是RAID必须保持不变以使奇偶校验正确的不变性。
由于奇偶校验正确的不变性,我们可以通过此确定丢失的块的奇偶位信息。
当一个块有多个奇偶位信息时,为每个块的每个位计算奇偶校验,然后将结果放入奇偶校验块中。如下所示:
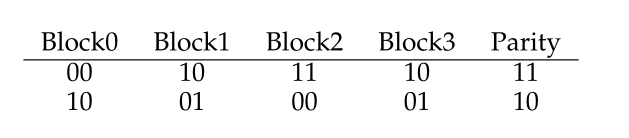
6.1 RAID-4 Analysis
让我们对RAID-4进行评估:
- 从容量来看,使用一个磁盘作为其要保护的魅族磁盘的奇偶校验信息,因此可用容量为(N – 1)* B
- 从可靠性来看,RAID-4只能容忍一个磁盘失效。
- 从稳态吞吐量来看,顺序读取除了奇偶校验磁盘外能够使用其他所有磁盘;执行顺序写操作时,RAID-4可执行简单的优化全条带写入(full-stripe write)。

考虑将上述块0、1、2和3作为写请求的一部分发送到RAID的情况。RAID计算P0的新值(通过对块0、1、2、3进行XOR),然后将所有块(包括奇偶校验块)写入上述5个磁盘中。 - 从稳态吞吐量来看,随机读取和顺序读取一样;随机写操作就比较有趣了,对于上图如果我们要重新写数据到块1,那么奇偶校验块P0将不再准确地反映条带的正确奇偶校验值,所以还需要更新P0的值。更新P0的值有两种方法:
- 加法奇偶校验(additive parity):要更新奇偶校验块的值,请并行读入该条带中的所有其他数据块(上例中块0、2和3),并与新块(上例中块1)进行异或(XOR)。要完成写入操作,需要同时将新数据和新奇偶校验写入各自的磁盘,这种技术的问题在于它会随着磁盘数量的增加而增加。
- 减法奇偶检验(subtractive parity)。假设原始奇偶位如下:
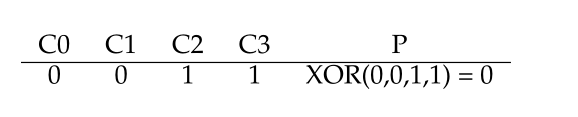
如果要对C2位进行新值重写,减法奇偶校验有三步:- 读旧数据值(C2old = 1)和旧奇偶校验值(Pold = 0)
- 比较旧数据值和新数据值。
- 如果相等,那么奇偶校验值不变(Pnew = 0);如果不等,那么把旧奇偶校验值取反(Pnew = 1)。
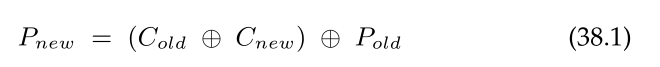
故对于此性能分析,假设使用减法奇偶校验。对于每次写入,RAID必须执行两次读取和两个写入。为了理解RAID能够并行执行几个,看下图:

假设RAID有两个写操作分别为块4和块13,数据位于磁盘0和磁盘1上,因此可以并行发生对数据的读写。问题出在奇偶校验磁盘,即使可以并行的访问数据磁盘,奇偶校验磁盘阻止了任何并行性的实现。由于奇偶校验磁盘盘的缘故,对系统的所有写入将被序列化。随机写操作下的RAID-4吞吐量非常糟糕。

7. RAID Level 5: Rotating Parity
RAID-5的工作原理几乎与RAID-4相同,只是它在驱动器之间旋转奇偶校验块。如下所示:

每个条带的奇偶校验块在磁盘上旋转,以消除RAID-4的奇偶校验此案瓶颈问题。
7.1 RAID-5 Analysis
RAID-5大部分特征分析都和RAID-4相同。
随机读性能更好点,因为能够使用所有的磁盘;随机写性能比RAID-4有了明显提高,因为它允许跨请求的并行性。假设上图中对块1的写操作和对块10的写操作:这将变成对磁盘1和磁盘4的请求(针对块1及其奇偶校验)和对磁盘0和磁盘2的请求(对于块10及其奇偶校验)。
8. RAID Comparison: A Summary
在下图总结了RAID级别的简化比较。为了简化分析,省略了很多细节。

最后祝大家新年快乐!(21年第一篇博客)

原文地址:http://www.cnblogs.com/astralcon/p/16792729.html