
python基础-内置函数、可迭代对象、迭代器对象、异常捕获
一、重要内置函数
1.zip
1.zip作用:组合
将两个列表中 位置顺序相同的一起结合成元组
2.语法结构:zip(数据集名1,数据集名2,数据集名3)
3.特点:
1)如果数据集中的数据个数不同,则zip中只会以短的数据集个数为接收标准
2)zip的返回值需要转换成列表不然返回的是<zip object at 0x1048bed80>
# 案例
l1 = [1, 2, 3, 4, 5, 4, 3, 2, 1]
l2 = ['jason', 'kevin', 'oscar', 'duoduo', 'leethon', 'jack', 'uzi']
l3 = [989, 'name', 11, 22, 33, 44, 55] # 以元素个数最少的数据集为接收标准
res = zip(l1, l3, l2) # 返回值并不是数据
print(list(res)) # 想要得到zip函数处理的结果需要转换成列表
----------结果------------
[(1, 989, 'jason'), (2, 'name', 'kevin'), (3, 11, 'oscar'), (4, 22, 'duoduo'), (5, 33, 'leethon'), (4, 44, 'jack'), (3, 55, 'uzi')]
2.filter过滤
1.filter作用:过滤
将两个列表中 位置顺序相同的一起结合成元组
2.语法结构:filter(函数,数据集名)
3.特点:
1)本质:filter的其实就是,按照 for 循环得到数据集中的数据值,通过 lambda 函数去过滤数据集中符合标准的数据值
2)filter函数的返回值也不是一个数,而是处理之后的数据集地址,想得到结果需要转换成列表 <filter object at 0x102f74220>
# 案例
l1 = [100, 2, 3, 40, 5, 41, 322, 2, 1]
res = filter(lambda x: x + 40, l1)
print(list(res)) # 处理之后的结果需要用列表接收
----------结果------------
[100, 2, 3, 40, 5, 41, 322, 2, 1]
3.sorted升序排序
1.sorted作用:升序排序
将数据集中的数据, 按照大小升序排列类似于 sort方法
2.语法结构:sorted(数据集名)
3.特点:
默认升序排列,返回值则是升序后的数据集
# 案例
l1 = [100, 2, 3, 40, 5, 41, 322, 2, 1]
res = sorted(l1)
print(res)
----------结果------------
[1, 2, 2, 3, 5, 40, 41, 100, 322]
二、常见内置函数
1.abs()绝对值
1.作用:取数据的绝对值
2.语法: abs(数据)
# 举例
print(abs(-99))
print(abs(100))
----------结果------------
99
100
2.all()
1.作用:所有数据值对应的布尔值为 True结果才是 True,否则返回 False
2.语法: all(数据)
3.特点:有一个不是 True则返回 False
# 布尔值False: 0 None False 空列表[] 空字典{} 空集合()
# 举例
l1 = [100, 2, 3, 40, 5, 41, 322, 2, 1]
print(all(l1))
print(all([100, 0, 322, 2, 1]))
----------结果------------
True
False
3.any()
1.作用:所有数据值对应的布尔值有一个为 True结果才是 True,否则返回 False
2.语法:any(数据)
3.特点:只有数据集中的元素布尔值全部为 False,才返回 False,不然都是 True
# 举例
l1 = [100, 2, 3, 40, 5, 41, 322, 2, 1]
print(any(l1))
print(any([0, None, False, [], {}, ()]))
----------结果------------
True
False
4.bin二进制 oct十进制 hex十六进制 int整数
1.作用:将其他进制数转为该进制数
2.语法
3.特点:bin 和 int 中的数字会默认是十进制, oct 和 hex或默认中间的数字是二进制数
# 举例
print(bin(100)) #bin(默认该数字是十进制数)
print(oct(100)) #oct(默认该数字是二进制数)
print(hex(100)) #hex(默认该数字是二进制数)
print(int(100)) #int(默认该数字是十进制数)
----------结果------------
0b1100100
0o144
0x64
100
5.bytes() 编码
?????????????
1.作用:返回一个新的“bytes”对象,它是0<=x<256范围内的不可变整数序列。
2.语法:class bytes([source[, encoding[, errors]]])
# 举例
print((bytes()))#为空
print((bytes([1,2,255])))#可迭代类型
print(type(bytes([1,2,255])))
print((bytes("China",'utf-8')))#字符串
print((bytes("中国",'gbk')))#字符串
print((bytes([1,2,256])))#报错
----------结果------------
b''
b'\x01\x02\xff'<class 'bytes'>
b'China'
b'\xd6\xd0\xb9\xfa'
Traceback (most recent call last):
File "D:/Pythonproject/111/bytes.py", line 6, in <module>
print((bytes([1,2,256])))#报错
ValueError: bytes must be in range(0, 256)
6.callable() 调用
1.作用:判断某一个名字是否可以加括号()调用
2.语法:callable(名称)
3.特点:返回值是布尔值
# 举例
name = 'jason'
def index():
print('from index')
print(callable(name))
print(callable(index))
----------结果------------
False
True
7.chr() ord()
基于ASCII码表作数字与字母转换
print(chr(65)) # A
print(ord('A')) # 65
1.作用:基于ASCII码表作数字与字母转换
2.语法: chr(ASCII码编号) 返回对应字母
ord(对应字母) 返回ASCII码编号
# 举例
print(chr(65)) # A
print(ord('A')) # 65
8.dir()
1.作用:返回括号内对象里面能调用的 名字
2.语法:dir(数据)
3.特点
# 举例
l1 = [100, 2, 3, 40, 5, 41, 322, 2, 1]
print(dir('hello'))
print(dir(l1))
----------结果------------
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
9.divmod()
返回元组(整数,余数)
res = divmod(100,3)
print(res) # (50,0)
# 案例
page_num,more = divmod(100,10)
if more:
page_num += 1
print('总页码为:',page_num)
----------结果------------
元组 第一个数据为整除数 第二个是余数
1.作用: 返回元组第一个数据为整除数 第二个是余数
2.语法: divmod(整数,余数)
3.特点: 返回的是元组
# 案例
res = divmod(100,3)
print(res) # (50,0)
# 案例页面分页原理
page_num, more = divmod(100, 10)
if more:
page_num += 1
print('总页码为:', page_num)
----------结果------------
总页码为: 10
10.enmerate() 枚举
1.作用:将i中的元素遍历,并按照顺序和递增的起始值 一一组队输出成一个个元组
2.语法: enumerate(i,start=起始值)
i为数据值,type是想判断的数据类型
3.特点: 返回的是元组
# 举例
s1 = 'hello'
for i in enumerate(s1,start=100):
print(i)
----------运行结果--------
(100, 'h')
(101, 'e')
(102, 'l')
(103, 'l')
(104, 'o')
11.eval() exec()
1.作用:能自动识别字符串在的py代码并执行
2.语法: eval(字符串)
exec(字符串)
3.特点:
eval() # 只能识别简单的python代码,具有逻辑性的都不想
exec() # 可以识别具有一定逻辑性的python代码
s1 = 'print("不是摆烂而是我放松的姿态")'
eval(s1)
exec(s1)
s2 = 'for i in range(3):print(i)'
eval(s2) # 报错,只能识别简单的python代码
exec(s2)
----------结果------------
不是摆烂而是我放松的姿态
不是摆烂而是我放松的姿态
# 报错
0
1
2
12.hash()哈希加密
1.作用:加密
# 举例
print(hash('不是摆烂而是我放松的姿态'))
----------结果------------
4878369790386566897
13.id input instance
1.id() 返回内存地址
2.input() 获取输入
3.判断的数据类型
isinstance(i,type)
i为数据值,type是想判断的数据类型
14.map() max() min()
1.map() 映射
2.max() \ min() 最大值 最小值
15.open
1.作用:由应用程序向操作系统发起系统调用 open(...),操作系统打开该文件,对应一块硬盘空间,并且返回一个文件对象
2.语法: open(文件路径, 读写模式, encoding='utf8')
3.特点:返回一个文件对象
16.pow幂指数
1.作用:计算x的y次幂
2.语法:pow(x, y[, z])
函数是计算 x 的 y 次方,如果 z 在存在,则再对结果进行取模,其结果等效于 pow(x,y) %z
取模运算是求两个数相除的余数
# 举例
print(pow(2, 2, 2))
print(pow(2, 3))
print(pow(2, 4))
----------结果------------
0
8
16
17.range() xrange()
三个参数,最后那个参数和分页相关?
1.作用
此函数是 Python 内置函数,用于生成一系列连续整数,可以简单的理解为是帮我们产生一个内部含有多个数字的数据。
2.语法
#(1) range(值1) >>>产生的数据,左包含,右不包含
for i in range(101): # 起始位置为0 终止位置为100
print(i) # [0,.......100]
#(2) range(值1,值2)
for i in range(10, 20): # 第一个为起始位置 第二个终止位置
print(i)
#(3) range(值1,值2,值3)
for i in range(1, 20, 2): # 第三个数为等差值 默认不写为1
print(i)
3.特点
Python 2中除 range() 函数外,还提供了一个 xrange() 函数,它可以解决 range() 函数不经意间耗掉所有可用内存的问题。
但在 Python 3 中,已经将 xrange() 更名为 range() 函数,并删除了老的 xrange() 函数。
18.round() 五舍六入
1.作用: 把浮点型的数据保留整数
2.语法: round(数据)
3.特点:五舍六入
# 举例
print(round(98.3)) # 98
print(round(98.6)) # 99
19.sum() 求和
1.作用:将数据集中的数据求和
2.语法:sum(数据集)
# 举例
l1 = [100, 2, 3, 40, 5, 41, 322, 2, 1]
print(sum(l1)) # 516
20.zip()
详情见上面
内置函数和数据类型内置方法的区别:
方法是只有该数据类型才能用
内置函数不规定数据类型
三、可迭代对象
1.可迭代对象
数据对象 内置有__iter__方法的称为可迭代对象
# 判断是否是可迭代对象 即判断是否有双下iter方法
"""
1.内置方法 通过点的方式能够调用的方法
2.__iter__ 双下iter方法
"""
2.可迭代对象的范围
不是可迭代对象
int float bool 函数对象
是可迭代对象(支持for循环)
str list dict tuple set 文件(也是跌打器对象)
3.可迭代的含义(可迭代对象的作用)
"""
迭代:更新换代(每次更新都必须依赖上一次的结果)
eg:手机app更新
"""
可迭代的含义:在python中可以理解为是否支持for循环
四、迭代器对象
1.迭代器对象
可迭代对象调用__iter__ 双下iter方法 就变成了迭代器对象
# 迭代器对象判断的本质是看是否内置有__iter__和__next__
2.迭代器对象作用
提供了一张不依赖于索引 (字典和集合没有索引的概念) 取值的方式
# 正因为有迭代器的存在,我们的 字典 集合(无序类型) 才能够被for循环
3.迭代器对象实操
# 案例
s1 = 'hello' # 可迭代对象
res = s1.__iter__() # 调用__iter__方法迭代器对象
print(res.__next__()) # 迭代取值 : for循环本质
一旦__next__取不到值就会报错
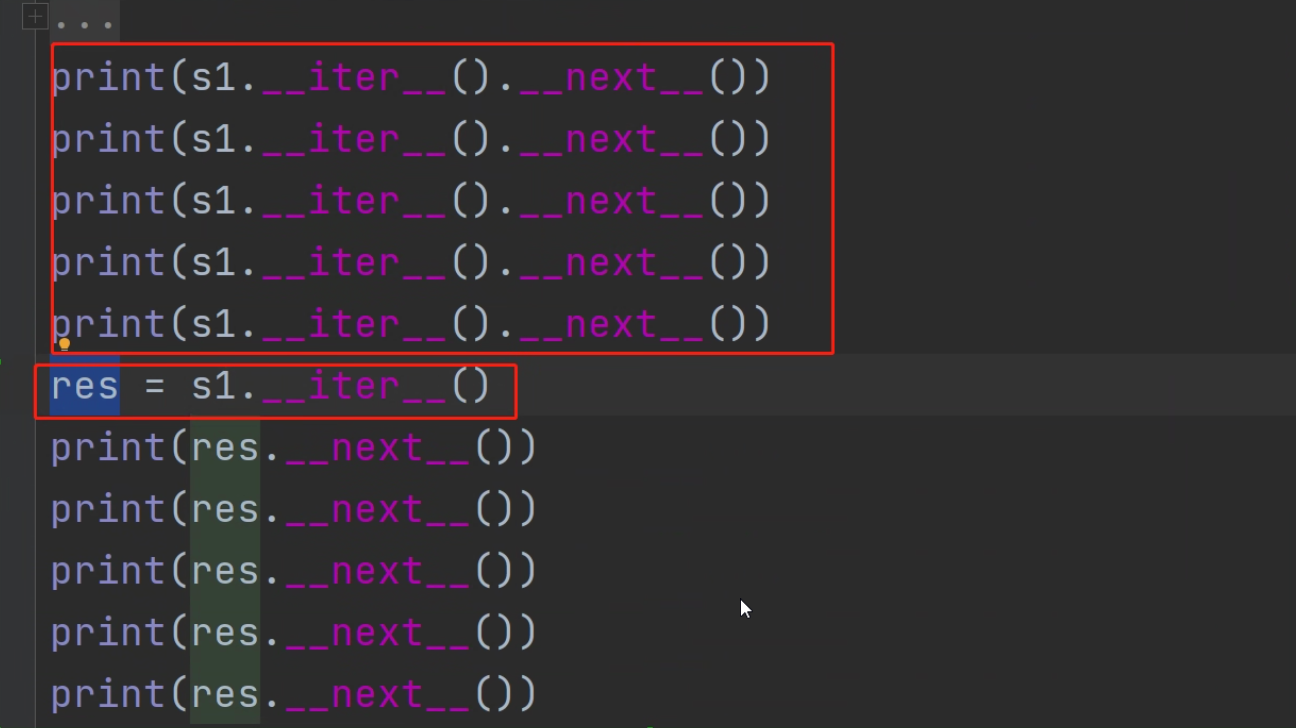
4.注意事项
可迭代对象调用__iter__会变成迭代器对象,迭代器对象如果还调用可迭代对象调用__iter__还是迭代器对象没有变化
# 注意案例
s1 = 'hello'
print(s1.__iter__().__next__())
print(s1.__iter__().__next__())
print(s1.__iter__().__next__())
print(s1.__iter__().__next__())
print(s1.__iter__().__next__())
5.简写
iter() # __iter__
next() # __next__
6.字典和集合取值
# 案例字典
d = {'name':'jason'}
res = d.__iter__()
print(res) # 取值取的还是键 name
五、for循环的本质
for 变量名 in 可迭代对象:
循环体代码
"""
1.先将in后面的数据调用__iter__转变被迭代器对象(文件本身就是迭代器对象,在调用__iter__也还是迭代器对象)
2.一次用迭代器对象调用__next__取值
3.一旦__next__取不到值报错,for循环会自动捕获并处理
"""
六、异常捕获/处理
1.异常
异常就是代码运行报错,也叫bug
# 代码运行一旦异常会直接结束整个程序的运行,我们在编写代码的过程中要尽量避免
2.异常类型
1)语法错误
不允许出现错误
2)逻辑错误
允许出现,因为它一眼发现不了,代码运行之后才可能会出现
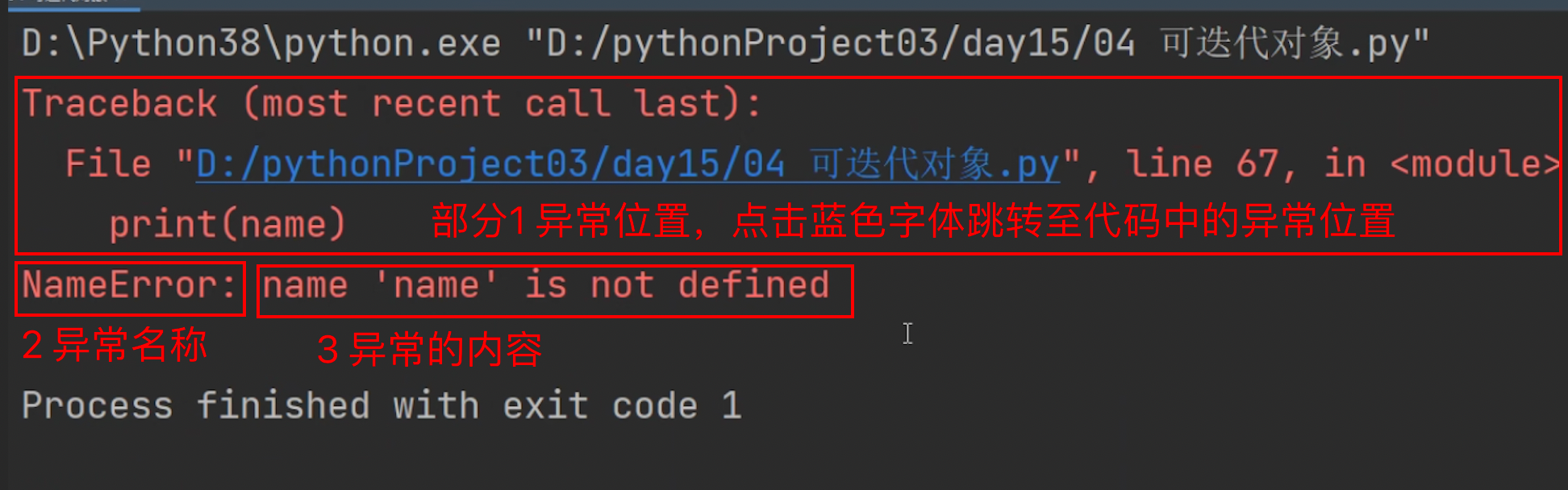
3.异常报错显示区的内容
部分 1)异常出现的位置
部分 2)异常出现的类型:部分 3)异常的类型
原文地址:http://www.cnblogs.com/DuoDuosg/p/16792946.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性