
汇编语言符号解析
参考文献链接
https://www.docin.com/p-1987059541.html
https://blog.csdn.net/tj_nonstoper/article/details/124784395
http://www.kaotop.com/it/168644.html
https://blog.csdn.net/weixin_42277902/article/details/125591295
https://zhuanlan.zhihu.com/p/497460602











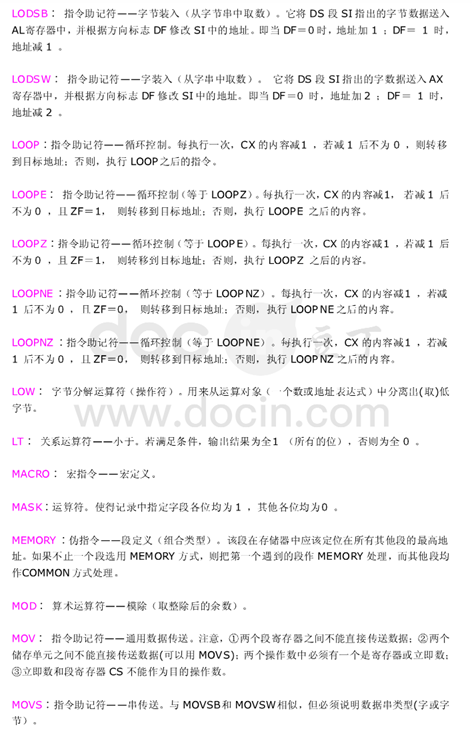







STM8汇编语言所用各种符号汇总
学习STM8汇编指令或汇编语言时会碰到很多符号,吃不准这些符号代表什么意思,很难透彻地理解STM8汇编指令或汇编语句的含义,下面做了个归纳汇总,方便大家对照查阅。
汇编语言符号集锦
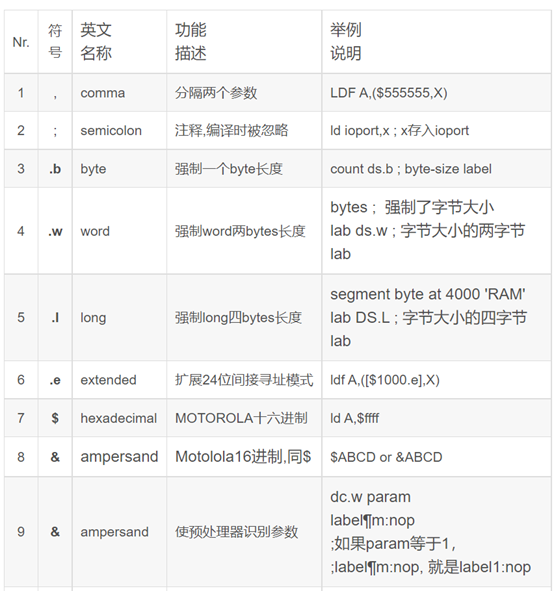
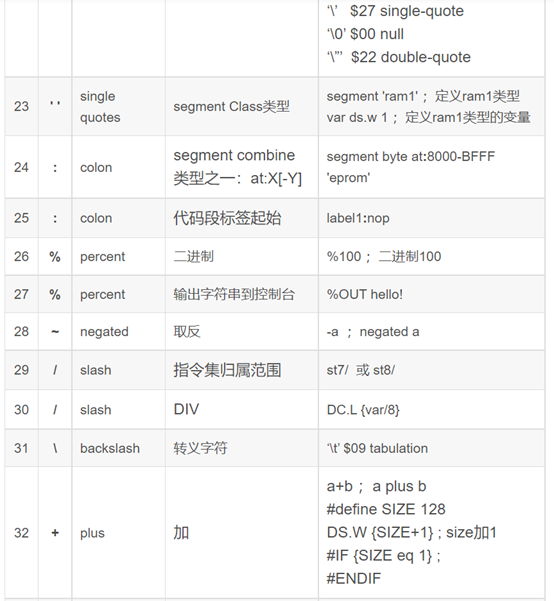
Nr. 符号 英文来源 功能描述 举例
1 , comma 隔开指令的两个参数 LDF A,($555555,X)
2 ; semicolon 注释,编译时被忽略 ld ioport,x ; store into ioport
3 .b byte 强制一个byte长度 count ds.b ; byte-size label
4 .w word 强制word两bytes长度
bytes ; 强制了字节大小
lab ds.w ; 字节大小的两字节lab
5 .l long 强制long四bytes长度
segment byte at 4000 ‘RAM’
lab DS.L ; 字节大小的四字节lab
6 .e extended 扩展24位间接寻址模式 ldf A,([$1000.e],X)
7 $ hexadecimal MOTOROLA十六进制 ld A,$ffff
8 # pound key 立即操作数
ld A,#1;十进制1赋给A
ld A,#$ff;十六进制ff赋给A
立即位操作数
bset memory,#3;将#3位置位
btjt memory,#3, label
;如果#3位为1则跳转
条件汇编 #IF {count eq 1};如count等于1 包含外部资源 #include “mapping.inc”
9 * asterisk 乘MULT a * b 程序计数器PC当前值 lab01 jra * 字符* ld A , #’*’
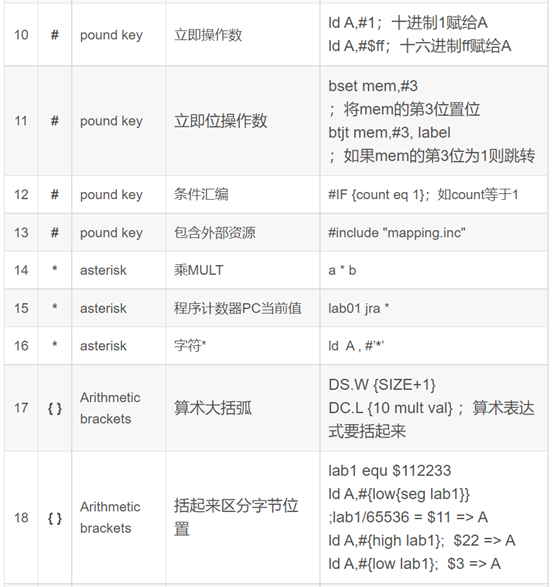
10 { } Arithmetic brackets 算术大括弧
DS.W {SIZE+1}
DC.L {10 mult val}
;算术表达式要括起来
括起来区分字节位置
lab1 equ $112233
ld A,#{low{seg lab1}}
;lab1/65536 = $11 => A
ld A,#{high lab1}; $22 => A
ld A,#{low lab1}; $3 => A
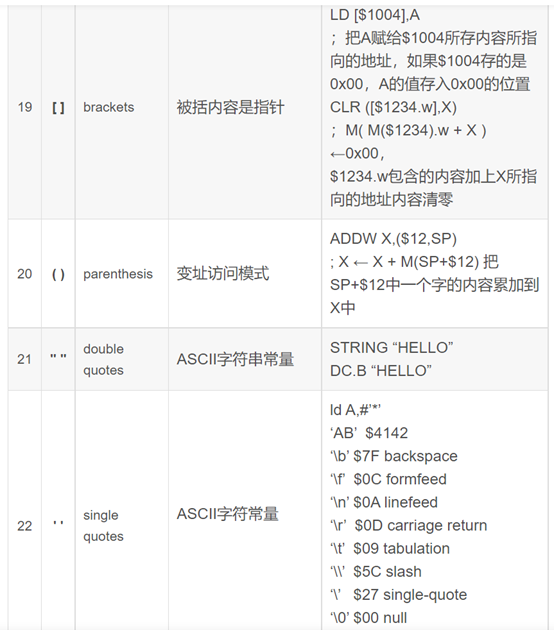
11 [ ] brackets 被括内容是指针
LD [$1004],A
;把A赋给$1004所存内容所指向的地址,如果$1004存的是0x00,A的值存入0x00的位置
CLR ([$1234.w],X)
;M( M($1234).w + X ) ←
0x00,$1234.w包含的内容加上X所指向的地址内容清零
12 ( ) parenthesis 变址访问模式
ADDW X,($12,SP)
; X ← X + M(SP+$12) 把SP+$12中一个字的内容累加到X中
13 ” ” double quotes ASCII字符串常量
STRING “HELLO”
DC.B “HELLO”
14 ‘ ‘ single quotes ASCII字符常量
ld A,#’*’
‘AB’ $4142
‘\b’ $7F backspace
‘\f’ $0C formfeed
‘\n’ $0A linefeed
‘\r’ $0D carriage return
‘\t’ $09 tabulation
‘\\’ $5C slash
‘\’ $27 single-quote
‘\0’ $00 null
‘\”’ $22 double-quote
segment Class类型 segment ‘ram1’ ;ram1类型
var3 ds.w 1
15 :
colon
segment combine
类型之一:at:X[-Y]
segment byte at:8000-BFFF ‘eprom’
label1:nop
16 % percent 二进制 %100 输出字符串到控制台 %OUT hello!
17 ~ negated 取反 -a negated a
18 / slash 指令集归属范围
st7/ 或 st8/
DIV DC.L {var/8}
19 & ampersand
Motolola
十六进制,和$一样
$ABCD or &ABCD ;HEX 使预处理器可识别参数
dc.w param
labelm:nop
;如果param等于1,
;labelm:nop
;就是label1:nop
20 \ backslash 转义字符 ‘\t’ $09 tabulation
21 + plus 加
a+b ;a plus b
#define SIZE 128
DS.W {SIZE+1} ; OK
#IF {SIZE eq 1} ; OK
#ENDIF
22 – minus 减
a-b ; a minus b
23 – strike 范围中划线 segment byte at:8000-BFFF ‘eprom’
详解汇编语言各种指令的解释与用法
【数据传输指令】
一、通用数据传送指令
1、传送指令MOV(move)
指令的汇编格式:MOV DST,SRC 指令的基本功能:(DST)<-(SRC) 将原操作数(字节或字)传送到目的地址。指令支持的寻址方式:目的操作数和源操作数不能同时用存储器寻址方式,这个限制适用于所有指令。指令的执行对标志位的影响:不影响标志位。指令的特殊要求:目的操作数DST和源操作数SRC不允许同时为段寄存器;目的操作数DST不能是CS,也不能用立即数方式。
2、进栈指令 PUSH(push onto the stack)
出栈指令 POP (pop from the stack) 指令的汇编格式:PUSH SRC ;POP DST 指令的基本功能:PUSH指令在程序中常用来暂存某些数据,而POP指令又可将这些数据恢复。PUSH SRC (SP)<-(SP)-2 ;(SP)<-(SRC) POP DST (DST)<-((SP));(SP)<-(SP) 指令支持的寻址方式:push 和 pop指令不能不能使用立即数寻址方式。指令对标志位的影响:PUSH 和 POP指令都不影响标志位。指令的特殊要求:PUSH 和 POP指令只能是字操作,因此,存取字数据后,SP的修改必须是+2 或者 -2; POP指令的DST不允许是CS寄存器;
3、交换指令 XCHG(exchange)
指令的汇编格式:XCHG OPR1,OPR2 指令的基本功能:(OPR1)<->(OPR2) 指令支持的寻址方式:一个操作数必须在寄存器中,另一个操作数可以在寄存器或存储器中。指令对标志位的影戏:不影响标志位。指令的特殊要求:不允许使用段寄存器。
二、累加器专用传送指令
4、输入指令 IN(input)
输出指令 OUT (output) 指令的汇编格式:IN ac,port port<=0FFH IN ac,DX port>0FFH OUT port,ac port<=0FFH OUT DX,ac port>0FFH 指令的基本功能:对8086及其后继机型的微处理机,所有I/O端口与CPU之间的通信都由输入输出指令IN和OUT来完成。IN指令将信息从I/O输入到CPU,OUT指令将信息从CPU输出到I/O端口,因此,IN和OUT指令都要指出I/O端口地址。 IN ac,port port<=0FFH (AL)<-(port)传送字节 或 (AX)<-(port+1,port)传送字 IN ac,DX port>0FFH (AL)<-((DX))传送字节或 (AX)<-((DX)+1,(DX))传送字 OUT port,ac port<=0FFH (port)<-(AL)传送字节 或 (port+1,port)<-(AX)传送字 OUT DX,ac port>0FFH (DX)<-(AL)传送字节 或 ((DX)+1,(DX))<-(AX)传送字指令对标志位的影响:不影响标志位。指令的特殊要求:只限于在AL或AX与I/O端口之间传送信息。传送16位信息用AX,传送8位信息用AL,这取决于外设端口的宽度。
5、换码指令 XLAT(translate)
指令的汇编格式:XLAT opr 或 XLAT 指令的基本功能:这条指令根据AL寄存器提供的位移量,将BX指使的字节表格中的代码换存在AL中。 (AL)<-((DS)*16+(BX)+(AL)) 指令对标志位的影响:不影响标志位。指令的特殊要求:所建字节表格的长度不能超过256字节,因为存放位移量的是8位寄存器AL。opr为表格的首地址,因为opr所表示的偏移地址已存入BX寄存器,所以opr在换码指令中可有可无,有则提高程序的可读性。
三、地址传送指令
6、有效地址传送器 LEA(load effective address)
指令的汇编格式:LEA reg,src 指令的基本功能:LEA指令把源操作数的有效地址送到指定的寄存器,这个有效地址是由src选定的一种存储器寻址方式确定的。指令支持的寻址方式:各种存储器寻址方式。指令对标志位的影响:不影响标志位。指令的特出要求:指令中reg不能是段寄存器;
7、指针送寄存器和DS LDS(load DS with point)
指针送寄存器和ES LES (load ES with point) 指令的汇编格式:LDS reg,src LES reg,src 指令的基本功能:LDS和LES指令把确定内存单元位置的偏移地址送寄存器,段地址DS或ES。这个偏移地址和段地址(也称地址指针)是由src指定的两个相继字单元提供的。 LDS reg,src (reg)<-(src) (DS)<-(src+2) LES reg,src (reg)<-(src) (ES)<-(src+2) 指令支持的寻址方式:src必须为存储器寻址方式指令对标志位的影响:不影响标志位。指令的特殊要求:指令中REG不能是段寄存器;
四、标志寄存器传送指令
8、标志寄存器的低字节送AH LAHF(load AH with FLAGS)
指令的汇编格式:LAHF 指令的基本功能:(AH)<-(FLAGS)0-7 指令对标志位的影响:不影响标志位
9、AH送标志寄存器低字节 SAHF(store AH into FLAGS) 指令的格式:SAHF 指令的基本功能:(FLAGS)0-7<-(AH) 指令对标志位的影响:由装入值来确定标志位的值。
10、标志进栈 PUSHF(push the flags)
指令的汇编格式:PUSHF 指令的基本功能:(SP)<-(SP)-2 ((SP)+1,(SP))<-(FLAGS)0-15 指令对标志位的影响:不影响标志位。
11、标志出栈 POPF(pop the FLAGES)
指令的汇编格式:POPF 指令的基本功能:(FLAGS)0-15<-((SP)+1,(SP)) (SP)<-(SP)+2 指令对标志位的影响:由装入值来确定标志位的值。
【算术指令】
一、加法指令
12、加法指令 ADD(addition)
指令的汇编格式:add dst,src 指令的基本功能:(dst)<-(src)+(dst) 指令支持的寻址方式:他们两个操作数不能同时为存储器寻址。即为除源操作数为立即数的情况外,源操作数和目地操作数必须有一个寄存器寻址方式。指令对标志位的影响:SF=1 加法结果为负数(符号位为1) SF=0 加法结果为正数(符号位为0) ZF=1 加法结果为零 ZF=0 加法结果不为零 CF=1 最高有效位向高位有进位 CF=0 最高有效位向高位无进位 OF=1 两个同符号数相加(正数+正数或负数+负数),结果符号与其相反。 OF=0 两个不同符号数相加,或同符号数相加,结果符号与其相同。
13、带进为加法指令 ADC(add with carry)
指令的汇编格式:ADD dst,src 指令的基本功能:(dst)<-(src)+(dst)+CF 指令支持的寻址方式:他们两个操作数不能同时为存储器寻址。即为除源操作数为立即数的情况外,源操作数和目地操作数必须有一个寄存器寻址方式。指令对标志位的影响:SF=1 加法结果为负数 SF=0 加法结果为正数 ZF=1 加法结果为零 ZF=0 加法结果不为零 CF=1 最高有效位向高位有进位 CF=0 最低有效位相高位无进位 OF=1 两个同符号数相加,结果符号与其相反, OF=0 两个同符号数相加,或同符号相加,结果符号与其相同
14、加1指令 INC(increament)
指令的汇编格式:INC opr 指令的基本功能:(opr)<-(opr) 指令支持的寻址方式 可以使用除立即数方式外的任何寻址方式指令对标志位的影响:SF=1 加法结果为负数 SF=0 加法结果为正数 ZF=1 加法结果为零 ZF=0 加法结果不为零 OF=1 两个同符号数相加,结果符号与其相反, OF=0 两个同符号数相加,或同符号相加,结果符号与其相同。
二、减法指令
15、减法指令 SUB(subtract) 指令的汇编格式:SUB dst,src 指令的基本功能:(dst)<-(dst)-(src) 指令支持的寻址方式:他们两个操作数不能同时为存储器寻址。即为除源操作数为立即数的情况外,源操作数和目地操作数必须有一个寄存器寻址方式。指令对标志位的影响:SF=1 减法结果为负数(符号位为1) SF=0 减法结果为正数(符号位为0) ZF=1 减法结果为零 ZF=0 减法结果不为零 CF=1 二进制减法运算中最高有效位向高位有借位(被减数小于减数,不够减的情况) CF=0 二进制减法运算中最高有效为向高位无借位(被减数〉=减数,够减的情况) OF=1 两数符号相反(正数-负数,或负数-正数),而结果符号与减数相同。 OF=0 同符号数相减时,或不同符号数相减,其结果符号与减数不同。
16、带借位减法指令 SBB(subtract with borrow)
指令的汇编格式:SBB dst,src 指令的基本功能:(dst)<-(dst)-(src)-CF 指令支持的寻址方式:他们两个操作数不能同时为存储器寻址。即为除源操作数为立即数的情况外,源操作数和目地操作数必须有一个寄存器寻址方式。指令对标志位的影响:SF=1 减法结果为负数(符号位为1) SF=0 减法结果为正数(符号位为0) ZF=1 减法结果为零 ZF=0 减法结果不为零 CF=1 二进制减法运算中最高有效位向高位有借位(被减数小于减数,不够减的情况) CF=0 二进制减法运算中最高有效为向高位无借位(被减数〉=减数,够减的情况) OF=1 两数符号相反(正数-负数,或负数-正数),而结果符号与减数相同。 OF=0 同符号数相减时,或不同符号数相减,其结果符号与减数不同。
17、减1指令 DEC(decrement)
指令的汇编格式:DEC opr 指令的基本功能:(opr)<-(opr)-1 指令支持的寻址方式:可以使用除立即数方式外的任何寻址方式。指令对标志位的影响:SF=1 减法结果为负数(符号位为1) SF=0 减法结果为正数(符号位为0) ZF=1 减法结果为零 ZF=0 减法结果不为零 OF=1 两数符号相反(正数-负数,或负数-正数),而结果符号与减数相同。 OF=0 同符号数相减时,或不同符号数相减,其结果符号与减数不同。
18、比较指令 CMP(compare)
指令的汇编格式:CMP opr1,opr2 指令的基本功能:(opr1)-(opr2),根据相减结果设置条件码,但不回送结果。指令支持的寻址方式:他们两个操作数不能同时为存储器寻址。即为除源操作数为立即数的情况外,源操作数和目地操作数必须有一个寄存器寻址方式。指令对标志位的影响:
SF=1 减法结果为负数(符号位为1) SF=0 减法结果为正数(符号位为0) ZF=1 减法结果为零 ZF=0 减法结果不为零 CF=1 二进制减法运算中
最高有效位向高位有借位(被减数小于减数,不够减的情况) CF=0 二进制减法运算中最高有效为向高位无借位(被减数〉=减数,够减的情况) OF=1 两数符号相反(正数-负数,或负数-正数),而结果符号与减数相同。 OF=0 同符号数相减时,或不同符号数相减,其结果符号与减数不同。
19、求补指令 NEG(negate)
指令的汇编格式:NEG opr 指令的基本功能:(opr)<- -(opr) 指令支持的寻址方式:可以使用除立即数方式外的任何寻址方式。指令对标志位的影响:CF=1 不为0的操作数求补时 CF=0 为0的操作数求补时 OF=1 操作数为-128(字节运算)或操作数为-32768(字运算) OF=0 当求补运算的操作数不为-128(字节)或-32768(字)时三、乘法指令
20、无符号乘法指令 NUL(unsigned multiple)
有符号乘法指令 IMUL(signed muliple) 指令的汇编格式:NUL src IMUL src 指令的基本功能:(AX)<-(AL)*(src) (DX,AX)<-(AX)*(src) 指令支持的寻址方式:src可以使用除立即数方式以外的任一种寻址方式。指令对标志位的影响:乘法指令只影响标志位CF和OF,其他条件码位无定义。 MUL指令的条件码设置为: CF OF=0 0 乘积的高一半为0(字节操作的(AH)或字操作的(DX)) CF OF=1 1 乘积的高一半不为0 IMUL指令的条件码设置为: CF OF=0 0 乘积的高一半为低一半的符号扩展. CF OF=1 1 其他情况指令的特殊要求:MUL和IMUL指令的区别仅在于操作数是无符号还是带符号数,它们的共同点是,指令中只给出源操作数src,目的操作数是隐含的,它只能是累加器(字运算为AX,字节运算为AL)。隐含的乘积寄存器是AX或DX(高位)和AX(低位)。
四、符号扩展指令
21、节扩展为字 CBW(convert byte to word)
指令的汇编格式:CBW 指令的基本功能:(AH)=00H 当(AL)的最高有效位为0时 (AH)=FFH 当(AL)的最高有效位为1时指令对标志位的影响:不影响标志位指令的特殊要求:这是条无操作数的指令,进行符号扩展的操作数必须存放在AL寄存器 AX寄存器中。
22、字扩展为双字 CWD(convert word to double word)
指令的汇编格式:CWD 指令的基本功能:(DX)=0000H 当(AX)的最高有效位为0时 (DX)=FFFFH 当(AX)的最高有效位为1时指令对标志位的影响:不影响标志位指令的特殊要求:这是条无操作数的指令,进行符号扩展的操作数必须存放在AL寄存器或AX寄存器中。
五、除法指令
23、无符号数除法 DIV(unsigned divide) 带符号数除法 IDIV (singed divide) 指令的汇编格式:DIV src IDIV src 指令的基本功能:字操作 (AL)<-(AX)/src的商 (AH)<-(AX)/src的余数字节操作 (AX)<-(DX,AX)/src的商 (DX)<-(DX,AX)/src的余数指令支持的寻址方式:src作为除数,可用除立即数以外的任一种寻址方式来取得。指令对标志位的影响:不影响条件码。指令的特殊要求:除法指令要求字操作时,被除数必须为32位,除数是16位,商和余数是16位的;字节操作时,被除数必须为16位,除数是8位,得到的商和余数是8位的。
六、十进制调整指令
【逻辑指令】
一、逻辑运算
指令的格式:ANDdst,src 指令的基本功能:(dst)<-(dst)与(src) 指令支持的寻址方式:两个操作数不能同时为存储器寻址。即为除源操作数为立即数的情况外,源操作数和目地操作数必须有一个寄存器寻址方式。指令对标志位的影响:指令执行后 CF 和 OF 置零,AF无定义。 SF=1 指令执行后的结果为负数(符号位为1) SF=0 指令执行后的结果为正数(符号位为0) ZF=1 指令执行后的结果为零 ZF=0 指令执行后的结果不为零 PF=1 结果操作数中1的个数为偶数时置1 PF=0 结果操作数中1的个数为奇数时置0 25、逻辑或 OR(logic or) 指令的汇编格式:OR dst,src 指令的基本功能:(dst)<-(dst)或(src) 指令支持的寻址方式:两个操作数不能同时为存储器寻址。即为除源操作数为立即数的情况外,原操作数和目的操作数必须有一个寄存器寻址方式。指令对标志位的影响:令执行后 CF 和 OF 置零,AF无定义。 SF=1 指令执行后的结果为负数(符号位为1) SF=0 指令执行后的结果为正数(符号位为0) ZF=1 指令执行后的结果为零 ZF=0 指令执行后的结果不为零 PF=1 结果操作数中1的个数为偶数时置1 PF=0 结果操作数中1的个数为奇数时置0 26、逻辑非 NOT(logic not) 指令的汇编格式:NOT orc 指令的基本功能:(dst)<-(opr) 指令支持的寻址方式:除立即数寻址方式以外的其余寻址方式指令对标志位的影响:对标志位无影响 27、异或 XOR(exclusice or) 指令的汇编格式:XOR dst,src 指令的基本功能:(dst)<-(dst)异或(src) 指令支持的寻址方式:两个操作数不能同时为存储器寻址。即为除源操作数为立即数的情况外,原操作数和目的操作数必须有一个寄存器寻址方式。指令对标志位的影响:令执行后 CF 和 OF 置零,AF无定义。 SF=1 指令执行后的结果为负数(符号位为1) SF=0 指令执行后的结果为正数(符号位为0) ZF=1 指令执行后的结果为零 ZF=0 指令执行后的结果不为零 PF=1 结果操作数中1的个数为偶数时置1 PF=0 结果操作数中1的个数为奇数时置0 28、测试指令 TEST 指令的汇编格式:TEST opr1,opr2 指令的基本功能:(opr1)与(opr2) 指令支持的寻址方式:两个操作数不能同时为存储器寻址,即为除源操作数为立即数的情况外,源操作数和目的操作数必须有一个寄存器寻址方式。指令对标志位的影响:令执行后 CF 和 OF 置零,AF无定义。 SF=1 指令执行后的结果为负数(符号位为1) SF=0 指令执行后的结果为正数(符号位为0) ZF=1 指令执行后的结果为零 ZF=0 指令执行后的结果不为零 PF=1 结果操作数中1的个数为偶数时置1 PF=0 结果操作数中1的个数为奇数时置0
二、移位指令
29、逻辑左移 SHL(shift logical left) 指令的汇编格式:SHL dst,cnt 指令的基本功能:SHL指令向左逐位移动cnt次,每次逐位移动后,最低位用0来补充,最高位移入CF。指令支持的寻址方式:目的操作数dst可以是除立即数外的任何寻址方式。移位次数(或位数)cnt=1时,1可以直接写在指令中,cnt〉1时,cnt必须放入CL寄存器中。指令对标志位的影响:CF=移入的数值 OF=1 当cnt=1时,移动后最高位的值发生变化。 OF=0 当cnt=1时,移动时最高位的值未发生变化。 SF、ZF、PF根据移动后的结果设置
30、逻辑右移 SHR (shift logical right) 指令的汇编格式:SHR dst,cnt 指令的基本功能:SHR指令向右逐位移动cnt次,每次逐位移动后,最高位用0来补充,最低位移入CF。指令支持的寻址方式:目的操作数dst可以是除立即数外的任何寻址方式。移位次数(或位数)cnt=1时,1可以直接写在指令中,cnt〉1时,cnt必须放入CL寄存器中。指令对标志位的影响:CF=移入的数值 OF=1 当cnt=1时,移动后最高位的值发生变化。 OF=0 当cnt=1时,移动时最高位的值未发生变化。 SF、ZF、PF根据移动后的结果设置。 31、算术左移 SAL(shift arithmetic left) 指令的汇编格式:SAL dst cnt 指令的基本功能:SAL指令向左逐位移动cnt次,每次逐位移动后,最低位用0来补充,最高位移入CF。指令支持的寻址方式:目的操作数dst可以是除立即数外的任何寻址方式。移位次数(或位数)cnt=1时,1可以直接写在指令中,cnt〉1时,cnt必须放入CL寄存器中。指令对标志位的影响:CF=移入的数值 OF=1 当cnt=1时,移动后最高位的值发生变化。 OF=0 当cnt=1时,移动时最高位的值未发生变化。 SF、ZF、PF根据移动后的结果设置。 32、算术右移 SAR(shift arithmetic right) 指令的汇编格式:SAR dst,cnt 指令的基本功能:SAR指令向右逐位移动cnt次,每次逐位移动后,最高位用符号位来补充,最低位移入CF。指令支持的寻址方式:目的操作数dst可以是除立即数外的任何寻址方式。移位次数(或位数)cnt=1时,1可以直接写在指令中,cnt〉1时,cnt必须放入CL寄存器中。指令对标志位的影响:CF=移入的数值 OF=1 当cnt=1时,移动后最高位的值发生变化。 OF=0 当cnt=1时,移动时最高位的值未发生变化。 SF、ZF、PF根据移动后的结果设置。 33、循环左移 ROL(rotate left) 指令的汇编格式:ROL dst,cnt 指令的基本功能:ROL 对由dst指定的寄存器或存储器操作数左移循环移动cnt所指定的次数,每左移一次,把最高位同时移入CF和操作数最低位。指令支持的寻址方式:目的操作数dst可以是除立即数外的任何寻址方式。移动次数(或位数)cnt=1时,1可以直接写在指令中,cnt〉1时,cnt必须放入CL寄存器中。指令对标志位的影响:CF=移入的数值 OF=1 当cnt=1时,移动后最高位的值发生变化。 OF=0 当cnt=1时,移动时最高位的值未发生变化。 SF、ZF、PF根据移动后的结果设置。 34、循环右移 ROR(rotate right) 指令的汇编格式:ROR dst,cnt 指令的基本功能:ROR 对由dst指定的寄存器或存储器操作数右移循环移动cnt所指定的次数,每右移一次,把最低位同时移入CF和操作数最高位。指令支持的寻址方式:目的操作数dst可以是除立即数外的任何寻址方式。移动次数(或位数)cnt=1时,1可以直接写在指令中,cnt>1时,cnt必须放入CL寄存器中。指令对标志位的影响:CF=移入的数值 OF=1 当cnt=1时,移动后最高位的值发生变化。 OF=0 当cnt=1时,移动时最高位的值未发生变化。 SF、ZF、PF根据移动后的结果设置。 35、带进位的循环左移RCL(rotate left through carry) 指令的汇编格式:RCL dst,cnt 指令的基本功能:RCL 对由dst指定的寄存器或存储器操作数,连同进位标志CF左循环移动,m所指定的次数,每左移一次,把操作数的最高位移入CF,而CF中原有内容移入操作数的最低位。指定支持的寻址方式:目的操作数dst可以是除立即数外的任何寻址方式。移动次数(或位数)cnt=1时,1可以直接写在指令中,cnt〉1时,cnt必须放入CL寄存器中。指令对标志位的影响:CF=移入的数值。 OF=1 当cnt=1时,移动后最高位的值未发生变化。 OF=0 当cnt=1时,移动后最高位的值发生变化。 SF、ZF、PF标志位不受影响。 36、带进位的循环右移 RCR(rotate right through carry) 指令的汇编格式:RCR dst,cnt 指令的基本功能:RCR 对由dst指定的寄存器或存储器操作数,连同进位标志CF右循环移动,m所指定的次数,每右移一次,把操作数的最高低位移入CF,而CF中原有内容移入操作数的最高位。指令支持的寻址方式:目的操作数dst可以是除立即数外的任何寻址方式。移动次数(或位数)cnt=1时,1可以直接写入指令中,cnt〉1时,cnt必须放入CL寄存器中。指令对标志位的影响:CF=移入的数值。 OF=1 当cnt=1时,操作数最高位的值未发生变化。 OF=0 当cnt=1时,操作数最高位的值发生变化。 SF、ZF、PF标志位不受影响。
【串处理指令】
一、设置方向标志指令
37、DF置零 CLD(clear direction flag) DF置一 STD (set direction flag) 指令的汇编格式:CLD STD 指令的基本功能:CLD DF=0 STD DF=1 二、串处理指令 38、串传送 MOVSB / MOVSW(move string byte/word) 指令的汇编格式:MOVSB MOVSW 指令的基本功能:(ES:DI)<-(DS:SI) (SI)<-(SI)+/-1(字节)或+/-2(字) (DI)<-(DI)+/-1(字节)或+/-2(字) 指令对条件码的影响:不影响条件码。指令的特殊要求:源串必须在数据段中,目的串必须在附加段中,串处理指令隐含的寻址方式是SI和DI寄存器的间接寻址方式。源串允许使用段跨越前缀来指定段。 39、存串 STOSB / STOSW(stroe from string byte/word) 指令的汇编格式:STOSB STOSW 指令的基本功能:(ES:DI)<-(AL)或(AX) (DI)<-(DI)+/-1(字节)或+/-2(字) 指令对条件码的影响:不影响条件码。指令的特殊要求:源串必须在数据段中,目的串必须在附加段中,串处理指令隐含的寻址方式是SI和DI寄存器的间接寻址方式。源串允许使用段跨越前缀来指定段。 40、取串LODSB / LODSW(load from string byte/word) 指令的汇编格式:LODSB LODSW 指令的基本功能:(AL)或(AX)<-(DS:SI) (SI)<-(SI)+/-1(字节)或+/-2(字) 指令对条件码的影响:不影响条件码。指令的特殊要求:源串必须在数据段中,目的串必须在附加段中,串处理指令隐含的寻址方式是SI和DI寄存器的间接寻址方式。源串允许使用段跨越前缀来指定段。 41、串比较 CMPSB / CMPSW(compare string byte/word) 指令的汇编格式:CMPSB CMPSW 指令的基本功能:(DS:SI)-(ES:DI) 根据比较结果设置条件码 (SI)<-(SI)+/-1(字节)或+/-2(字) (DI)<-(DI)+/-1(字节)或+/-2(字) 指令对条件码的影响:SF=1 减法结果为负数(符号位为1) SF=0 减法结果为正数(符号位为0) ZF=1 减法结果为零 ZF=0 减法结果不为零 CF=1 二进制减法运算中最高有效位向高位有借位(被减数小于减数,不够减的情况) CF=0 二进制减法运算中最高有效为向高位无借位(被减数〉=减数,够减的情况) OF=1 两数符号相反(正数-负数,或负数-正数),而结果符号与减数相同。 OF=0 同符号数相减时,或不同符号数相减,其结果符号与减数不同。 42、串扫描 SCASB / SCASW(scan string byte / word) 指令的格式:SCASB SCASW 指令的基本功能:(AL)<-(ES:DI)或(AX)<-(ES:DI) 根据扫描比较的结果设置条件码。 (DI)<-(DI)+/-1(字节)或+/-2(字) 指令对条件码的影响:SF=1 结果为负数(符号位为1) SF=0 结果为正数(符号位为0) ZF=1 结果为零 ZF=0 结果不为零 CF=1 二进制减法运算中最高有效位向高位有借位(被减数小于减数,不够减的情况) CF=0 二进制减法运算中最高有效为向高位无借位(被减数〉=减数,够减的情况) OF=1 两数符号相反(正数-负数,或负数-正数),而结果符号与减数相同。 OF=0 同符号数相减时,或不同符号数相减,其结果符号与减数不同。
三、串重复前缀
43、重复执行串 REP 指令的汇编格式:REP (CX)=重复次数指令的基本功能:① (CX)=0时,串指令执行完毕,否则执行② ~ ④ ② (CX)←(CX)-1③ 执行串指令(MOVS或STOS)④ 重复执行① 44、相等/为零时重复执行串指令 REPE/REPZ 指令的汇编格式:REPE / REPZ (CX)=比较/扫描的次数指令的基本功能:① (CX)=0或ZF=0时,结束执行串指令,否则继续② ~ ④ ② (CX)←(CX)-1③ 执行串指令(CMPS或SCAS)④ 重复执行① 45、不等/不为零时重复执行串指令 REPNE / PEPNZ 指令的汇编格式:REPNE / PEPNZ (CX)=比较/扫描的次数指令的基本功能:① (CX)=0或ZF=1,结束执行串指令,否则继续② ~ ④ ② (CX)←(CX)-1③ 执行串指令(CMPS或SCAS)④ 重复执行①
【控制转移指令】
一、无条件转移指令
46、短转移 JMP SHORT label(short jump) 指令的汇编格式:JMP SHORT label 指令的基本功能:(IP)<-当前(IP)+8位位移量 8位位移量是汇编程序在汇编源程序时,根据目标地址和当前IP之间的距离自动生成的。指令对条件码的影响:对标志位无影响。 47、近转移JMP NEAR PTR label(near jump) 指令的汇编格式:直接转移 JMP label (direct jump) 寄存器间接转移 JMP reg (register indirect jump) 存储器间接转移 JMP WORD PTR OPR (memory indirect jump) 指令的基本功能:JMP label (IP) <- OFFSET label = (IP)当前+16位位移量 JMP reg (IP) <- (reg) JMP WORD PTR OPR (IP) <- (PA+1,PA) 指令支持的寻址方式:指令中的转向地址可以是直接寻址方式、寄存器寻址方式、寄存器间接寻址方式和存储器寻址方式。指令对条件码的影响:对标志位无影响。 48、远转移 JMP FAR PTR label(for jump) 指令的汇编格式:JMP FAR PTR label 指令的基本功能:(IP)<-label的段内偏移地址 (CS)<-label所在段的段地址指令支持的寻址方式:远转移的目的地址可以使用除立即寻址方式外的任何寻址方式来表示。指令对条件码的影响:对标志位无影响。
二、条件转移指令
指令的汇编格式及功能根据条件码的值转移: 49、JZ(JE) OPR ZF=1 ZF=0(运算结果为0,ZF就置1) 50、JNZ(JNE) OPR ZF=0 51、JS OPR SF=1 SF=0(二进制最高位是什么,SF就是什么,如最高位为1则SF=1) 52、JNS OPR SF=0 53、JO OPR OF=1 OF=1 (两个负数相加变成正数,溢出) 54、JNO OPR OF=0 55、JP OPR PF=1 PF=0 (反映结果“1”的个数,奇数☞0 偶数个☞1) 56、JNP OPR PF=0 57、JC OPR CF=1CF=1(最高位有进位或借位就置1) 58、JNC OPR CF=0 比较两个无符号数,根据比较的结果转移 59、JB(JNAE,JC) OPR CF=1 被减数小于减数则转移 60、JNB(JAE,JNC) OPR CF=0 被减数大于或等于减数则转移 61、JBE(JNA) OPR CF或ZF=1 被减数小于或等于减数则转移 62、JNBE(JA) OPR CF或ZF=0 被减数大于减数则转移比较两个带符号数,根据比较结果转移 63、JL/JNGE OPR SF异或OF=1 被减数小于减数则转移 64、JNL/JGE SF异或OF=0 被减数不小于减数则转移 65、JLE/JNE (SF异或OF)与ZF=1 被减数不大于减数则转移 66、JNLE/JG (SF异或OF)与ZF=0 被减数大于减数则转移根据CX寄存器的值转移 67、JCXZ (CX)=0 CX内容为零则转移指令的特殊要求:所有条件转移指令都是短转移指令,转移的目标地址必须在当前IP地址的-128至+127字节范围之内,因此条件转移指令是2字节指令。
三、循环指令
68、循环LOOP(loop) 指令的汇编格式:LOOP label 指令的基本功能:① (CX)←(CX)-1 ② 若(CX)≠0,则(IP)←(IP)当前+位移量,否则循环结束。指令的特殊要求:循环指令都是短转移格式的指令,也就是说,位移量是用8位带符号数来表示的,转向地址在相对于当前IP值的-128 ~ +127字节范围之内。 69、为零/相等时循环 LOOPZ/LOOPE(loop while nonzero or equal) 指令的汇编格式:LOOPNZ/LOOPNE label 指令的基本功能:① (CX)←(CX)-1 ② 若ZF=1且(CX)≠0,则(IP)←(IP)当前+位移量,否则循环结束。指令的特殊要求:循环指令都是短转移格式的指令,也就是说,位移量是用8位带符号数来表示的,转向地址在相对于当前IP值的-128 ~ +127字节范围之内。 70、不为零/不相等时循环 LOOPNZ/LOOPNE(loop while nonzero or not equal) 指令的汇编格式:LOOPNZ/LOOPNE label 指令的基本功能:① (CX)←(CX)-1 ② 若ZF=0且(CX)≠0,则(IP)←(IP)当前+位移量,否则循环结束。指令的特殊要求:循环指令都是短转移格式的指令,也就是说,位移量是用8位带符号数来表示的,转向地址在相对于当前IP值的-128 ~ +127字节范围之内。
四、子程序调用
71、段内直接近调用 CALL SUBROUT 指令的基本功能:(SP)<-(SP)-2 ((SP)+1,(sp))<-(IP) (IP)<-(IP)+16位位移量段内间接近调用 CALL DESTIN 指令的基本功能:(SP)<-(SP)-2 ((SP)+1,(SP))<-(IP) (IP)<-(EA) 72、段间直接调用 CALL FAR PTR SUBROUT 指令的基本功能:(SP)<-(SP)-2,((SP))<-(CS)当前 (SP)<-(SP)-2,((SP))<-(IP)当前 (IP)<-偏移地址(在指令的第2、3个字节) (CS)<-段地址(在指令的第4、5个字节)
五、返回指令
73、段内返回(近返回) RET 指令的基本功能:(IP)<-((SP)+1,(SP)) (SP)<-(SP)+2 段间返回(远返回) RET 指令的基本功能:(IP)<-((SP)),(SP)<-(SP)+2 (CS)<-((SP)),(SP)<-(SP)+2 带立即数返回 RET N 执行操作:① 返回地址出栈(操作同段内或段间返回)
② 修改堆栈指针:(SP) ← (SP)+N
六、中断及中断返回指令
74、INT n 中断指令(interrupt),n为中断类型号 执行操作:① 入栈保存FLAGS:(SP) ← (SP)-2,((SP)) ← (FLAGS) ② 入栈保存返回地址:(SP) ← (SP)-2,((SP)) ← (CS) (SP) ← (SP)-2,((SP)) ← (IP) ③ 转中断处理程序:(IP) ← (n×4) (CS) ← (n×4+2) 75、IRET 中断返回指令(return from interrupt) 执行操作:① 返回地址出栈:(IP) ← ((SP)),(SP) ← (SP)+2 (CS) ← ((SP)),(SP) ← (SP)+2 ② FLAGS出栈:(FLAGS) ← ((SP)),(SP) ← (SP)+2 76、INTO 溢出则中断(中断类型为4) 执行操作:若OF=1(有溢出),则: ① 入栈保存FLAGS:(SP) ← (SP)-2,((SP)) ← (FLAGS) ② 入栈保存返回地址:(SP) ← (SP)-2,((SP)) ← (CS) (SP) ← (SP)-2,((SP)) ← (IP) ③ 转中断处理程序:(IP) ← (4×4)= (10H) (CS) ← (4×4+2)= (12H
HELLO,WORLD进阶汇编程序系列
Editor:admin Time:2004-3-21 12:49 Read:9785 Score:8 Print
Writer:LLUCT
Excerpt:80×86汇编小站
Preface:
感谢网友lluct为本站提供原创……适合初学者学习哦
Content:
TITLE ***HELLO,WORLD进阶程序之选择分支 BY LLUCT***
DATA SEGMENT ;定义数据段
MSG1 DB ‘***WELCOME TO MY PROGRAM BY LLUCT***’,’$’
;定义输出的第一个字符串信息,字符串必须用DB定义,$为结束标志
MSG2 DB ‘1:BASIC MESSAGE 2:ADVANCED MESSAGE’,’$’
;定义输出的字符串信息:选择菜单
MSG3 DB ‘PLEASE CHOOSE:’,’$’
;定义输出的字符串信息:选择前缀
MSG4 DB ‘HELLO,WORLD!^-^’,’$’
;定义输出的字符串信息:分支1的信息
MSG5 DB ‘THIS IS MY FIRST ASM_86 PROGRAM! @^-^@’,’$’
;定义输出的字符串信息:分支2的信息
ERRMSG DB ‘CHOOSE ERROR! -_-b’,’$’
;定义输出的字符串信息:选择错误信息
DATA ENDS ;数据段结尾
CODE SEGMENT ;定义代码段
ASSUME CS:CODE ;规定CS的内容
ASSUME DS:DATA ;规定DS的内容
START: MOV AX,DATA ;程序从START开始
MOV DS,AX ;DS置初值,DATA的段地址
CALL ENTER ;调用显示回车换行子程序
LEA DX,MSG1 ;输出第一个字符串的偏移地址
CALL DISPCHS ;调用显示字符串子程序
CALL ENTER ;调用显示回车换行子程序
CALL ENTER ;这个…同上啊^-^
LEA DX,MSG2 ;输出第二个字符串的偏移地址
CALL DISPCHS ;调用显示字符串子程序
AGAIN: CALL ENTER ;定义AGAIN标号.用于选择错误循环
LEA DX,MSG3 ;输出第三个字符串的偏移地址
CALL DISPCHS ;调用显示字符串子程序
MOV AH,01H ;调用1号功能:从键盘输入一个字符并回显
INT 21H ;完成输入回显
CMP AL,’1′ ;输入的字符和1相比较
JE BASICP ;如果相等,转移到BASICP标号(JE=Jump if Equal)
CMP AL,’2′ ;输入的字符和2相比较 ||
JE ADVANP ;如果相等,转移到ADVANP标号(JE=如果相等就转移)
JMP ERROR ;否则就无条件转移到ERROR标号
EXIT: MOV AH,4CH ;4C号功能调用:终止当前程序并返回调用程序
INT 21H ;返回DOS
BASICP: CALL ENTER ;什么,还要解释啊.晕-_-!!!
LEA DX,MSG4 ;输出第三个字符串的偏移地址
CALL DISPCHS ;调用显示字符串子程序
CALL ENTER ;……….
JMP EXIT ;无条件转移到EXIT标号
ADVANP: CALL ENTER ;55555555
LEA DX,MSG5 ;解释了四次,应该懂了吧
CALL DISPCHS ;调用显示字符串子程序
CALL ENTER ;再问就死给你看
JMP EXIT ;无条件转移到EXIT标号
ERROR: CALL ENTER
LEA DX,ERRMSG ;输出选择错误信息
CALL DISPCHS ;调用显示字符串子程序
MOV DL,07H ;输出ASCII码的报警(响铃)控制符BEL(07H)
CALL DISPCH ;调用显示单个字符子程序
CALL ENTER
JMP AGAIN
DISPCH PROC NEAR
;显示单个字符子程序,NEAR说明子程序和主程序在同一个代码段中(现无主程序调用)
MOV AH,02H ;2号功能调用:显示器输出字符
INT 21H ;完成输出显示
RET ;返回
DISPCH ENDP ;子程序结尾
ENTER PROC NEAR ;显示回车换行子程序
MOV DL,0DH ;输出ASCII码的回车控制符CR(0DH)
CALL DISPCH ;调用显示单个字符子程序
MOV DL,0AH ;输出ASCII码的换行控制符LF(0AH)
CALL DISPCH ;调用显示单个字符子程序
RET ;返回
ENTER ENDP ;子程序结尾
DISPCHS PROC NEAR
;显示字符串子程序,NEAR说明子程序和主程序在同一个代码段中(现无主程序调用)
MOV AH,09H ;9号功能调用:显示字符串
INT 21H ;完成输出显示
RET
DISPCHS ENDP
CODE ENDS ;代码段结尾
END START ;结束汇编
;把以上代码复制到记事本等文本程序中,并保存.(如helloch.asm)
;编译:masm helloch.asm
;连接:link helloch.obj
;执行:helloch.exe
======================================================
title ***hello,world进阶之字符串输入输出 by lluct***
data segment ;定义数据段
input db 100 dup(?)
;定义输入的字符串,字符串必须用db定义,长度为100个字节
msg1 db ‘Hello,’,’$’
;定义输出的前缀字符串信息,字符串必须用db定义,$为结束标志(24h)
msg2 db ‘,Welcome to here!’,’$’
;定义输出的后缀字符串信息
headmsg db ‘PLEASE INPUT YOUR NAME:’,’$’
;开始显示的字符串信息
data ends ;数据段结尾
code segment ;定义代码段
assume cs:code ;规定cs的内容
assume ds:data ;规定ds的内容
start: mov ax,data ;程序从start开始
mov ds,ax ;ds置初值,data的段地址
mov si,0 ;变址寄存器置初值0
call enter ;调用显示回车换行子程序
lea dx,headmsg ;输出开始显示的字符串的偏移地址
call dispchs ;调用显示字符串子程序
repeat: mov ah,01h
;定义repeat标号,用于循环输入单个字符.调用1号功能:从键盘输入一个字符并回显
int 21h ;完成输入回显
cmp al,0dh ;输入的字符和CR(回车)比较
je exit ;如果等于回车就转移到exit
mov input[si],al ;把al的值传送到input的si地址中(好像是这样吧)
inc si ;si加1
jmp repeat ;无条件转移到repeat
exit: call enter
mov input[si],24h ;给输入完成的字符串加上结束标志($)
call enter
lea dx,msg1 ;输出前缀字符串的偏移地址
call dispchs ;调用显示字符串子程序
lea dx,input ;输出刚才输入的字符串
call dispchs
lea dx,msg2
call dispchs
call enter
mov ah,4ch ;4c号功能调用:终止当前程序并返回调用程序
int 21h ;返回dos
enter proc near ;显示回车换行子程序
mov dl,0dh ;输出ascii码的回车控制符cr(0dh)
call dispch
mov dl,0ah ;输出ascii码的换行控制符lf(0ah)
call dispch
ret ;返回
enter endp ;子程序结束
dispch proc near
mov ah,02h ;2号功能调用:显示器输出字符
int 21h ;完成输出显示
ret ;返回
dispch endp
dispchs proc near
mov ah,09h ;9号功能调用:显示字符串
int 21h ;完成输出显示
ret ;返回
dispchs endp
code ends ;代码段结尾
end start ;结束汇编
;把以上代码复制到记事本等文本程序中,并保存.(如heinout.c)
;编译:masm heinout.asm
;连接:link heinout.obj
;执行:heinout.exe
中断是指CPU对系统发生的某个事件作出的一种反应:CPU暂停正在执行的程序,保留现场后自动转去执行相应的处理程序,处理完该事件后再返回断点继续执行被”打断”的程序
在我们所用的电脑中,所有的硬件都需要执行中断请求的动作,简单说它的作用就是用来停止其相关硬件的工作状态。我们可以举一个日常生活中的例子来说明,假如你正在给朋友写信,电话铃响了,这时你放下手中的笔去接电话,通话完毕再继续写信。这个例子就表现了中断及其处理的过程:电话铃声使你暂时中止当前的工作,而去处理更为急需处理的事情——接电话,当把急需处理的事情处理完毕之后,再回过头来继续原来的事情。在这个例子中,电话铃声就可以称为“中断请求”,而你暂停写信去接电话就叫作“中断响应”,那么接电话的过程就是“中断处理”。由此我们可以看出,在计算机执行程序的过程中,由于出现某个特殊情况(或称为“事件”),使得系统暂时中止现行程序,而转去执行处理这一特殊事件的程序,处理完毕之后再回到原来程序的中断点继续向下执行,而这个过程就被称为中断。
中断的作用
我们可以再举一个例子来说明中断的作用。假设有一个朋友来拜访你,但是由于不知何时到达,你只能在门口等待,于是什么事情也干不了;但如果在门口装一个门铃,你就不必在门口等待而可以在家里去做其他的工作,朋友来了按门铃通知你,这时你才中断手中的工作去开门,这就避免了不必要的等待。而计算机也一样,例如打印文稿的操作。因为cpu传送数据的速度高,而打印机速度较慢,如果不采用中断技术,cpu将经常处于等待状态,这会使得电脑的工作效率极低。而采用了中断方式后,cpu就可以在打印的同时进行其他的工作,而只在打印机缓冲区内的当前内容打印完毕,而发出中断请求之后才予以响应,这时才暂时中断当前的工作转去执行停止打印的操作,之后再返回执行原来的程序。这样就大大地提高了计算机系统的效率。
irq中断
计算机中的中断有好几种,根据中断信号产生的来源可以分为:硬件中断和软件中断。硬件中断多由外围设备和计算机系统控制器发出,软件中断一般由软件命令产生。在硬件中断中又有“可屏蔽中断”和“不可屏蔽中断”之分。顾名思义,可屏蔽中断可以由计算机根据系统的需要来决定是否进行接收处理或是延后处理(即屏蔽),而不可屏蔽中断便是直接激活相应的中断处理程序,它不能也不会被延误。而irq中断就是可屏蔽的硬件中断,它的全称为interrupt request 即“中断请求”。
在电脑的系统中,是由一个中断控制器8259或是8259a的芯片(现在此芯片大都集成到其他的芯片内)来对系统中每个硬件的中断进行控制。目前共有16组irq,去掉其中用来作桥接的一组irq,实际上只有15组irq可供硬件调用。而这些irq都有自己建议的配置。
分配irq中断
我们日常所用的操作系统对于irq的设置也不尽相同,所以在安装新硬件的时候,系统往往并不能自动检测正确的irq来分配给所需调用的硬件,这就会造成此硬件设备或是原来的旧硬件出现不能正常工作的现象。其实这是系统自动将该硬件的irq分配给了其他与此irq相同的硬件上,从而发生冲突使硬件不能正常工作。一般如果遇到这种情况,只要将新旧两个硬件的irq配置手动调开就可以解决了。
对于一些常用的硬件一般都有其默认的irq数值。比如声卡常常使用irq5或7。虽然这些配件使用其他的irq值大多数也能工作,但假如碰到特别“挑剔”的软件或游戏等程序,例如只能识别irq值为5或7的声卡,那么如果将它设成irq9就白费心机了。
8.3.1 中断的基本概念
中断(Interrupt)是指计算机在实行期间,系统内发生非寻常的或非预期的急需处理事件,使得CPU暂时中断当前正在执行的程序而转去执行响应的事件处理程序。待处理完毕后又返回原来中断处继续执行或调度新的程序执行的过程。
现代计算机系统一般都具有处理突发事件的能力。例如:从磁带上读入一组信息,当发现读入信息有错误时,只要让磁带退回重读该组信息就可能克服错误,而得到正确的信息。
这种处理突发事件的能力是由硬件和软件协作完成的。首先由硬件的中断装置发现产生的事件,然后,中断装置中止现行程序的执行,引出处理该事件的程序来处理。计算机系统不仅可以处理由于硬件或软件错误而产生的事件,而且可以处理某种预定处理伪事件。例如:外围设备工作结束时,也发出中断请求,向系统报告它已完成任务,系统根据具体情况作出相应处理。引起中断的事件称为中断源。发现中断源并产生中断的硬件称中断装置。在不同的硬件结构中,通常有不同的中断源和平不同的中断装置,但它们有一个共性,即:当中断事件发生后,中断装置能改变处理器内操作执行的顺序。
中断源:引起中断发生的事件被称为中断源。中断请求:中断源向CPU发出的请求中断处理信号。中断响应:CPU收到中断请求后转相应的事件处理程序。禁止中断(关中断):CPU内部的处理机状态字PSW的中断允许位已被清除,不允许CPU响应中断。开中断:PSW的中断允许位的设置。中断屏蔽:在中断请求产生之后,系统用软件方式有选择地封锁部分中断而允许蓁部分的中断仍能得到响应。
8.3.4 中断处理过程
中断处理过程:
(1) CPU检查响应中断的条件是否满足。CPU响应中断的条件是:有来自于中断源的中断请求、CPU允许中断。如果中断响应条件不满足,则中断处理无法进行。 (2) 如果CPU响应中断,则CPU关中断,使其进入不可再次响应中断的状态。 (3) 保存被中断进程现场。为了在中断处理结束后能使进程正确地返回到中断点,系统必须保存当前处理机状态字PSW和程序计数器PC等的值。这些值一般保存在特定堆栈或硬件寄存器中。 (4) 分析中断原因,调用中断处理子程序。在多个中断请求同时发生时,处理优先级最高的中断源发出的中断请求。 (5) 执行中断处理子程序。对陷阱来说,在有些系统中则是通过陷阱指令向当前执行进程发软中断信号后调用对应的处理子程序执行。 (6) 退出中断,恢复被中断进程的现场或调度新进程占据处理机。 (7) 开中断,CPU继续执行。
1.什么叫中断?
简单来说,中断是一种使CPU中止正在执行的程序而转去处理特殊事件的操作。这些引起中断的事件称为中断源,它们可能是来自外设的输入输出请求,也可能是计算机的一些异常事故或其它内部原因。 更具体地,我们定义CPU中断为这样一个过程:在特定的事件(中断源,也称中断请求信号)触发下引起CPU暂停正在运行的程序(主程序),转而先去处理一段为特定事件而编写的处理程序(中断处理程序),等中断处理程序处理完成后,再回到主程序被打断的地方继续运行。
2.中断的作用
一方面,有了中断功能,PC系统就可以使CPU和外设同时工作,使系统可以及时地响应外部事件。而且有了中断功能,CPU可允许多个外设同时工作。这样就大大提高了CPU的利用率,也提高了数据输入、输出的速度。 另一方面,有了中断功能,就可以使CPU及时处理各种软硬件故障。计算机在运行过程中,往往会出现事先预料不到的情况或出现一些故障,如电源掉电、存储出错,运算溢出等等。计算机可以利用中断系统自行处理,而不必停机或报告工作人员。
3.中断类型
在PC机系统中,根据中断源的不同,中断常分为两大类:硬件中断和软件中断。 硬件中断也称为外部中断,它又可以分为两种: 1).可屏蔽中断:是可以被CPU屏蔽的由中断电路发出的中断请求信号在CPU的INTR端引起的中断,它常常由PC机的外设或一些接口功能产生,如键盘、打印机、串行口等。可屏蔽意味着这类型中断可以在CPU要处理其它紧急操作时,被软件屏蔽或忽略。 2).非屏蔽中断:是由CPU的NMI端引起的中断,如当系统出现掉电、内存奇偶校验错误等,系统都将使用非屏蔽中断。非屏蔽是指CPU不能用软件指令来禁止对这种中断响应,也就是CPU必须响应由NMI端送来的中断信号。 软件中断,又称为内部中断,是指程序中使用INT中断指令引起的中断。
4.CPU响应中断的条件
除了非屏蔽中断外,其它中断都可以用软件来屏蔽或开放。系统只有具备如下的中断条件,CPU才可能对中断请求进行响应。 1) 设置中断请求触发器 2) 设置中断屏蔽触发器 3) 设置中断允许触发器
5.CPU处理中断过程
当满足了中断的条件后,CPU就会响应中断,转入中断程序处理。具体的工作过程如下所述。 1) 关中断 2) 保留断点 3) 保护现场 4) 给出中断入口,转入相应的中断服务程序 5) 恢复现场 6) 开中断与返回
6.中断冲突
虽然现在Windows操作系统从Win9X开始已经支持即插即用功能,大大简化了用户的操作,但是如果不能认出要安装的新设备,那么自动分配中断时就会产生冲突。现在新的硬件产品层出不穷,各种产品又相互兼容,功能类似,这就导致了操作系统常常不能正确检测出新设备,中断冲突也就不可避免了。
7.中断控制器8259A的结构
Intel 8259A是与8088/8086系列兼容的可编程的中断控制器。后来的微机系统也沿用这种中断机制及其功能,只是因为集成芯片技术的提高,不单独以8259A芯片的形式出现,而是集成到一个叫做”南桥芯片”或”HUB芯片”的芯片里了。 8259A包括以下几个部分: 1).中断请求寄存器IRR(Interrupt Request Register):有8条外界中断请求线IR0~IR7,每一条请求线有一个相应的触发器来保存请求信号。 2).中断服务寄存器ISR(IN Service Register):保存正在服务的中断。 3).优先权电路:对保存在IRR中的各个中断请求,经过判断确定最高的优先权,并在中断响应周期把它选通至中断服务寄存器。 4).中断屏蔽寄存器IMR(Interrupt Mask Register):寄存器的每一位,可以对IRR中的相应的中断源进行屏蔽。但对于较高优先权的输入线实现屏蔽并不影响较低优先权的输入。 5).数据总线缓冲器:是8259A与系统数据总线的接口,它是8位的双向三态缓冲器。凡是CPU对8259A编程时的控制字,都是通过它写入8259A的,8259A状态信息,也是通过它读入CPU的;在中断响应周期,8259A送至数据总线的CALL指令或中断向量也是通过它传送的。 6).读/写控制逻辑:CPU能通过它实现对8259A的读出(状态信号)和写入(初始化编程)。 7).级连缓冲器:实现8259A芯片之间的级连,使得中断源可由8级扩展至64级。 8).控制逻辑部分:对芯片内部的工作进行控制,使它按编程的规定工作。
8.8259A的级连 在一个系统中,8259A可以级连,有一个主8259A,若干个从8259A,最多可以有8个从8259A,把中断源扩展到64个。
非 法 传 送 种 种
1.两个操作数的类型不一致 –—–例如源操作数是字节,而目的操作数是字;或相反
• 绝大多数双操作数指令,除非特别说明,目的操作数与源操作数必须类型一致,否则为非法指令 MOV AL , 050AH;非法指令:050Ah为字,而AL为字节
• 寄存器有明确的字节或字类型,有寄存器参与的指令其操作数类型就是寄存器的类型
• 对于存储器单元与立即数同时作为操作数的情况,必须显式指明;
byte ptr 指示字节类型 , word ptr 指示字类型。
2.两个操作数不能都是存储器 –——传送指令很灵活,但主存之间的直接传送却不允许
• 8086指令系统不允许两个操作数都是存储单元(除串操作指令),要实现这种传送,可通过寄存器间接实现
mov ax , buffer1;ax←buffer1(将buffer1内容送ax)
mov buffer2 , ax;buffer2←ax;这里buffer1和buffer2是两个字变量、;实际表示直接寻址方式
3.段寄存器的操作有一些限制 –—-段寄存器属专用寄存器,对他们的操作能力有限
• 不允许立即数传送给段寄存器 MOV DS,100H;非法指令:立即数不能传送段寄存器
• 不允许直接改变CS值 MOV CS,[SI] ;不允许使用的指令
• 不允许段寄存器之间的直接数据传送 MOV DS,ES;非法指令:不允许段寄存器间传送
MOV BL,AX(数据长度不匹配)
MOV DS,2000H(不允许给段存储器用立即数赋值)
MOV CS,AX(禁止用MOV指令给CS赋值)
MOV [AX],[2000H](禁止直接在存储器间传送)
MOV [2000H],20H(数据长度不确切,应改为
MOV BYTE PTR [2000H],20H)
1、(1)状态标志:CF-进位标志,ZF-零标志,SF-符号标志,PF-奇偶标志
OF-溢出标志,AF-辅助进位标志。
(2)控制标志:DF-方向标志,IF-中断允许标志,TF-陷井标志。
2、8086机器代码格式一般是:
操作码寻址方式偏移量立即数。
3、(1)源操作数为立即寻址,目的操作数为寄存器寻址。
(2)源操作数为寄存器相对寻址,目的操作数为寄存器寻址。
(3)源操作数为寄存器寻址,目的操作数为寄存器间接寻址。
(4)源操作数和目的操作数均为固定寻址。
4、此题要求出物理地址,物理地址的计算公式为:
段地址(段首地址)*10H+偏移地址(有效地址)
(1)源操作数为立即寻址方式,操作数地址就在本条指令中。
(2)源操作数为直接寻址方式,其物理地址为
DS*10H+100H=20100H
(3)源操作数为寄存器间接寻址,其物理地址为
SS*10H+BP=15010H
(4)源操作数为基址变址寻址,其物理地址为
DS*10H+BX+SI+VAL=201E0H
8086 有14个16位寄存器,这14个寄存器按其用途可分为(1)通用寄存器、(2)指令指针、(3)标志寄存器和(4)段寄存器等4类。 (1)通用寄存器有8个, 又可以分成2组,一组是数据寄存器(4个),另一组是指针寄存器及变址寄存器(4个). 数据寄存器分为: AH&AL=AX(accumulator):累加寄存器,常用于运算;在乘除等指令中指定用来存放操作数,另外,所有的I/O指令都使用这一寄存器与外界设备传送数据. BH&BL=BX(base):基址寄存器,常用于地址索引; CH&CL=CX(count):计数寄存器,常用于计数;常用于保存计算值,如在移位指令,循环(loop)和串处理指令中用作隐含的计数器. DH&DL=DX(data):数据寄存器,常用于数据传递。他们的特点是,这4个16位的寄存器可以分为高8位: AH, BH, CH, DH.以及低八位:AL,BL,CL,DL。这2组8位寄存器可以分别寻址,并单独使用。另一组是指针寄存器和变址寄存器,包括: SP(Stack Pointer):堆栈指针,与SS配合使用,可指向目前的堆栈位置; BP(base Pointer):基址指针寄存器,可用作SS的一个相对基址位置; SI(Source Index):源变址寄存器可用来存放相对于DS段之源变址指针; DI(Destination Index):目的变址寄存器,可用来存放相对于 ES 段之目的变址指针。这4个16位寄存器只能按16位进行存取操作,主要用来形成操作数的地址,用于堆栈操作和变址运算中计算操作数的有效地址。 (2) 指令指针IP(Instruction Pointer) 指令指针IP是一个16位专用寄存器,它指向当前需要取出的指令字节,当BIU从内存中取出一个指令字节后,IP就自动加1,指向下一个指令字节。注意,IP指向的是指令地址的段内地址偏移量,又称偏移地址(Offset Address)或有效地址(EA,Effective Address)。 (3)标志寄存器FR(Flag Register) 8086有一个18位的标志寄存器FR,在FR中有意义的有9位,其中6位是状态位,3位是控制位。 OF: 溢出标志位OF用于反映有符号数加减运算所得结果是否溢出。如果运算结果超过当前运算位数所能表示的范围,则称为溢出,OF的值被置为1,否则,OF的值被清为0。 DF:方向标志DF位用来决定在串操作指令执行时有关指针寄存器发生调整的方向。 IF:中断允许标志IF位用来决定CPU是否响应CPU外部的可屏蔽中断发出的中断请求。但不管该标志为何值,CPU都必须响应CPU外部的不可屏蔽中断所发出的中断请求,以及CPU内部产生的中断请求。具体规定如下: (1)、当IF=1时,CPU可以响应CPU外部的可屏蔽中断发出的中断请求; (2)、当IF=0时,CPU不响应CPU外部的可屏蔽中断发出的中断请求。 TF:跟踪标志TF。该标志可用于程序调试。TF标志没有专门的指令来设置或清楚。(1)如果TF=1,则CPU处于单步执行指令的工作方式,此时每执行完一条指令,就显示CPU内各个寄存器的当前值及CPU将要执行的下一条指令。(2)如果TF=0,则处于连续工作模式。 SF:符号标志SF用来反映运算结果的符号位,它与运算结果的最高位相同。在微机系统中,有符号数采用补码表示法,所以,SF也就反映运算结果的正负号。运算结果为正数时,SF的值为0,否则其值为1。 ZF: 零标志ZF用来反映运算结果是否为0。如果运算结果为0,则其值为1,否则其值为0。在判断运算结果是否为0时,可使用此标志位。 AF:下列情况下,辅助进位标志AF的值被置为1,否则其值为0: (1)、在字操作时,发生低字节向高字节进位或借位时; (2)、在字节操作时,发生低4位向高4位进位或借位时。 PF:奇偶标志PF用于反映运算结果中“1”的个数的奇偶性。如果“1”的个数为偶数,则PF的值为1,否则其值为0。 CF:进位标志CF主要用来反映运算是否产生进位或借位。如果运算结果的最高位产生了一个进位或借位,那么,其值为1,否则其值为0。) 4)段寄存器(Segment Register) 为了运用所有的内存空间,8086设定了四个段寄存器,专门用来保存段地址: CS(Code Segment):代码段寄存器; DS(Data Segment):数据段寄存器; SS(Stack Segment):堆栈段寄存器; ES(Extra Segment):附加段寄存器。当一个程序要执行时,就要决定程序代码、数据和堆栈各要用到内存的哪些位置,通过设定段寄存器 CS,DS,SS 来指向这些起始位置。通常是将DS固定,而根据需要修改CS。所以,程序可以在可寻址空间小于64K的情况下被写成任意大小。 所以,程序和其数据组合起来的大小,限制在DS 所指的64K内,这就是COM文件不得大于64K的原因。8086以内存做为战场,用寄存器做为军事基地,以加速工作。
由于16位/32位CPU是微机CPU的两个重要代表,所以,在此只介绍它们内部寄存器的名称及其主要功能。
1、 16位寄存器组
16位CPU所含有的寄存器有
4个数据寄存器(AX、BX、CX和DX)
2个变址和指针寄存器(SI和DI) 2个指针寄存器(SP和BP)
4个段寄存器(ES、CS、SS和DS)
1个指令指针寄存器(IP) 1个标志寄存器(Flags)
2、 32位寄存器组
32位CPU除了包含了先前CPU的所有寄存器,并把通用寄存器、指令指针和标志寄存器从16位扩充成32位之外,还增加了2个16位的段寄存器:FS和GS。
32位CPU所含有的寄存器有
4个数据寄存器(EAX、EBX、ECX和EDX)
2个变址和指针寄存器(ESI和EDI) 2个指针寄存器(ESP和EBP)
6个段寄存器(ES、CS、SS、DS、FS和GS)
1个指令指针寄存器(EIP) 1个标志寄存器(EFlags)
具有一个输入端口和两个输出端口。
宏与子程序的区别宏和子程序都是为了简化源程序的编写,提高程序的可维护性,但是它们二者之间存在着以下本质的区别: 1、在源程序中,通过书写宏名来引用宏,而子程序是通过CALL指令来调用; 2、汇编程序对宏通过宏扩展来加入其定义体,宏引用多少次,就相应扩展多少次,所以,引用宏不会缩短目标程序;而子程序代码在目标程序中只出现一次,调用子程序是执行同一程序段,因此,目标程序也得到相应的简化; 3、宏引用时,参数是通过“实参”替换“形参”的方式来实现传递的,参数形式灵活多样,而子程序调用时,参数是通过寄存器、堆栈或约定存储单元进行传递的; 4、宏引用语句扩展后,目标程序中就不再有宏引用语句,运行时,不会有额外的时间开销,而子程序的调用在目标程序中仍存在,子程序的调用和返回均需要时间。总之,当程序片段不长,速度是关键因素时,可采用宏来简化源程序,但当程序片段较长,存储空间是关键因素时,可采用子程序的方法来简化源程序和目标程序。
DATA SEGMENT
MSG1 DB
MSG2 DW
DATA ANDS
CODE SEGMENT
ASSUME CS:CODE,DS:DATA
START:MOV AX, DATA
MOV DS, AX
MOV DX OFFSET MSG1
( MOV BX
MOV AH, 4CH
INT 21H
CODE ENDS
END START
关于assume的作用,许多人都简单的解释说,这是告诉编译器哪一个段和哪一个段寄存器相关联。举个简单例子来说: assumecs:code,ds:data 这是告诉编译器cs和code关联,ds和data关联,后来又看到这样的代码 movax,data movds,ax 让许多人一头雾水,既然ds和data关联了,怎么又要把data的值送到ds,这到底是怎么回事? 这里,先不做过多的说明,我们先看看下面这个例子:
下面的程序,把data段中的字符串拷贝到dseg段中,并且调用dos的21h中断的9号功能来显示 dseg段中的字符串:
;segtest.asm datasegment msgdb’Hello,howareyou?’,0dh,0ah,24h dataends dsegsegment hellodb32dup(0) db0dh,0ah,24h dsegends codesegment assumecs:code,ds:dseg,es:data start: movax,dseg movds,ax;把dseg段的段地址送入ds movax,data moves,ax;把data段的段地址送入es movsi,offsetmsg;把源字符串的偏移送入si movdi,offsethello;把目标字符串的偏移送入di cploop: moval,msg[si];(1)这里是一个寄存器相对寻址,那么这个物理地址是怎么形成的呢? cmpal,24h jzok movhello[di],al;(2)这里又是一个寄存器相对寻址,这个物理地址又是怎么形成的? incsi incdi jmpshortcploop ok: movdx,offsethello movah,9h int21h movax,4c00h int21h codeends endstart
对于(1)和(2)中两个地址的形成我们来分析一下: 这两个都是寄存器相对寻址,即有效地址都是一个寄存器加上一个16位的偏移量 对于(1)EA=(si)+msg的偏移地址 物理地址就是:(段寄存器)×16+EA 段寄存器有四个cs,ds,es,ss,那么编译器怎么知道用哪一个呢?这里就显示出了assume的作用,是assume告诉了编译器,data段中的标号的段地址要从es中取得,即这一句: es:data告诉了编译器在datasegment和dataends之间的所有的标号都要使用es作为段寄存器来寻址,于是当编译器看到这个msg标号的时候,它就知道了这里物理地址的形成是用(es)×16+EA 同理,对于(2),当编译器看到hello这个标号的时候,它就知道要取ds中的值作为段地址。如果没有 assume说明哪一个段和哪一个寄存器关联,那么,编译器就无法确定到底用哪一个段寄存器来计算物理地址。
从这里,我们也可以看出,assume的作用仅仅是告诉编译器,我碰到一个标号,要计算它的物理地址的时候,从哪一个段寄存器里面取出段值,至于这个段寄存器的值对不对,那它就不管了,这是程序员的事情,反正它只管根据assume里面的设定来用段寄存器,所以,对于程序员来说,不仅要用assume告诉编译器计算物理地址的时候要从哪一个段寄存器取值,而且要在指令中明确的把对应段的段值送到设定好的段寄存器中。 用伪指令assume告诉编译器,data段中的标号的段地址要从es中取值,而指令 movax,data moves,ax 则把data段的段地址送入es中,这样编译器计算msg标号的物理地址的时候,才能得到正确的段地址。
当然,如果你不用assume指明哪一个段和哪一个寄存器相关联,比如我把assumecs:code,ds:dseg,es:data改为 assumecs:code这也可以,即我不把ds和dseg关联,也不把es和data关联,但是你必须在指令中明确的告诉编译器使用哪一个段寄存器 指令moval,msg[si]必须改为moval,es:msg[si],而指令movhello[di],al也必须改为movds:hello[di],al,这样编译器才能知道使用哪一个段寄存器计算物理地址。如果编译器无法确定标号的段地址,那么程序编译就不会通过。
汇编语言基础知识
80386常用寄存器
一、常用寄存器
1.1 通用寄存器
EAX:累加寄存器
EBX:基址寄存器
ECX:计数寄存器
EDX:I/O指针–数据寄存器
ESI:(字符串操作源指针)源变址寄存器
EDI:(字符串操作目的指针)目的变址寄存器、
ESP:堆栈指针寄存器,存放对战的栈顶地址,不可做为通用寄存器
EBP:基址指针寄存器,表示栈区域的基地址,保存ESP,函数返回时把值返回ESP
1.2 段寄存器
Intel公司决定采用 (段地址<<4)+段偏移 的方式,组合成20位地址。 • 16bit段地址保存在段寄存器中;段偏移也是16bit。 • 通过将段地址左移4bit的方式,将两个16bit地址组合成20bit地址。
1.3 程序状态与控制寄存器
EFLAGS,标志寄存器:
存储相关指令的某些执行结果
为CPU执行相关指令提供行为数据
控制CPU的相关工作方式
CF:进位标识位:
无符号运算,记录运算结果的最高有效位向更高有效位的进位或借位值
加法,进位则CF=1
减法,借位则CF=1
PF:奇偶标志位
结果中1的个数为偶数,则PF=1
结果中1的个数为奇数,则PF=0
AF:辅助进位标志位
字操作时,发生低字节向高字节进位或借位,AF=1
字节操作时,低4位向高4位进位或借位时,AF=1
ZF:零标志位
结果位0,则ZF=1
SF:符号标志位
记录相关指令执行后,其结果为负数,SF=1
OF:溢出标志位
发生溢出,则OF=1
EIP:指令指针寄存器
保存着CPU下一条将要执行指令的地址
EIP自动增加,不能直接修改EIP,可以由JMP、CALL、RET、中断或异常修改
二、常用基本指令
2.1 数据传送指令
将数据、地址或立即数传送到寄存器或存储单元
MOV:把源操作数传送到目的操作数
MOV EAX,EDX; 寄存器EDX –》EAX的数据传送
MOV WORD PTR[BX+DI],2; 16位立即数2送偏移地址为位BX+DI的字单元
LEA:将源操作数的有效地址传送到通用寄存器
LEA EAX,[EBP-4]; 将SS段中EBP-4所指向的存储单元送入EAX
等价于MOV EAX,EBP-4
PUSH:操作数压入栈
PUSH EAX; 寄存器EAX的值存入栈顶ESP
POP:出栈
POP EAX; 栈顶ESP保存的数据取出,赋值给EAX,再将ESP+4
2.2 算术运算指令
加法指令:ADD,INC
减法指令:SUB,DEC
乘法指令:MUL
除法指令:DIV
2.2.1 加法指令
ADD :将源操作数和目的操作数相加,结果从到目的操作数
ADD EAX,EBX; 将EAX,EBX的值相加,结果送到EAX中
ADD指令的执行会影响CF,ZF
INC:将目的操作数+1
INC EAX:将EAX的值加一
目的操作数可以是通用寄存器,也可以是内存单元
2.2.2 减法指令
SUB:将目的操作数减去源操作数,结果送入目的操作数
SUB EAX,EBX;计算EAX-EBX的值,结果保存到EAX中
SUB 指令执行同样会影响CF,ZF等标志位
DEC:将目的操作数减一
同上INC
2.2.3 乘法指令
MUL:无符号数乘法指令,将源操作数和目的操作数相乘,结果送入目的操作数
IMUL:有符号数乘法指令,将源操作数和累加器中的操作数相乘,结果送入目的操作数
MUL,IMUL指令的源操作数为通用寄存器或存储器操作数,目的操作数缺省存放在寄存器(EAX)中
MUL EBX;将EAX*EBX的值保存在EAX中
2.2.4 除法指令
DIV:无符号数除法指令
IDIV:有符号数除法指令
DIV、IDIV指令的源操作数为通用寄存器或存储器操作数,目的操作数缺省存放在寄存器(EAX)中
DIV EBX;将EBX除以EAX的值保存在EAX中,余数放在EDX中
2.3 逻辑运算和移位指令
2.3.1 逻辑运算指令
AND:逻辑与
OR:逻辑或
XOR:逻辑异或
指令格式: AND(OR/XOR) DEST,SRC
源操作数可以是通用寄存器、存储器操作数或立即数,目的操作数是通用寄存器或存储器操作数
AND EAX,EBX;将EAX,EBX按逻辑与,结果存在EAX
NOT:逻辑非,按位取反,结果存入目的操作数
NOT DEST
2.3.2 移位指令
SAL:算术左移
SHL:逻辑左移
指令格式:SAL (SHL) DEST,OPR
SAL ECX,4; ECX左移4位,结果存在ECX中
说明:SAL、ECX指令功能完全相同,按照操作数 OPRD 的规定的移位位 数对目的操作数进行左移操作,每移一位,最低位补0,最高位移入标志 位 CF 中。左移都是补0。
SAR:算术右移,
每移一位, 最低位移入标志位 CF,最高位(符号位)保持不变。相当于对有符号数进行除 2 操作。最高位填充符号位。正数填充0,负数填充1
SHR:逻辑右移
每移一位, 最低位移入标志位 CF,最高位补0。
指令格式:SAR DEST,ORPD
2.3.3 循环移位指令
ROL:循环左移
ROR:循环右移
指令格式:ROL DEST,OPRD
2.4 控制转移指令
2.4.1 无条件转移指令
JMP:无条件转移
CALL:过程调用,等价于PUSH EIP+4;JMP addr
RET:过程返回,从栈中将保存的返回地址取出,跳转到原函数执行,等价于POP EIP
2.4.2 条件转移指令
指令 转移条件 说明
JC $dest CF=1 有进位/借位时转移
JNC $dest CF=1 无进位/借位时转移
JE/JZ $dest ZF=1 相等/等于0时转移
JNE/JNZ $dest ZF=0 不相等/不等于0时转移
JS $dest SF=1 是负数时 转移
JNS $dest SF=0 不是负数时转移
通常条件转移指令会和能改变 EFLAGS 对应位的指令配合使用
CMP 指令和 SUB 指令相同,但不会将计算结果保存到目的操作数。因此, CMP EAX, 3 执行之后会修改 EFLAGS 的 ZF 标志位:
如果 EAX – 3 = 0,则 ZF 置为 1
如果 EAX – 3 ≠ 0,则 ZF 置为 0
JZ 指令查看 ZF 标志位,如果是 1 ,则跳转到对应位置,否则顺序执行
PLT表和GOT表
1、Linux编译过程
预处理、编译、汇编、链接
1.1 预处理
处理所有宏定义 #define 以及所有的条件预编译指令(#if #ifdef #elif #else #endif)
处理#include预编译指令,将被包含的文件插入到该预编译指令的位置
删除所有注释
添加行号和文件标识,以便编译时产生调试用的行号及编译错误警告行号
保留所有#pragma编译器指令,后续编译过程需要使用
1.2 编译
编译:利用编译程序,将源语言编写的程序转化为目标语言的过程
目标语言就是汇编语言
1.3 汇编
汇编:对汇编语言编写的代码进行处理,生成处理器能够识别的指令,即机器码
生成目标文件
1.4 链接
汇编生成的目标文件 .o 不能直接运行
只有我们自己写的代码转换成了机器码,他需要和系统组件(标准库、动态链接库等)搭起来才能运行
链接LInk是一个打包的过程,将所有二进制形式的目标文件和系统组件组合 成一个可执行文件,完成连接的过程叫 链接器
2、静态编译动态链接
静态编译
在编译时,将生成的目标文件.o 和需要的库文件一起打包到可执行文件中。此使静态库可理解为一组目标文件的集合,即很多目标文件压缩打包后形成的文件。
特点:
程序运行时与函数库无关
资源冗余
在编译时就发生了
动态链接
动态库的程序在程序运行时才会被载入,规避了空间浪费的问题
3、延迟绑定
把对某个函数地址进行重定位的工作,推迟到该函数被第一次调用时再进行
ELF使用 PLT 过程链接表 技术实现延迟绑定
3.1 重定向
在程序编译的期间,引用外部函数和变量时,只需要知道其声明和类型。函数的定义以及变量(外部符号)时,只需要知道其生命和类型。函数的定义以及变量的值要到链接甚至执行时才能确定。
call read:调用read
在编译时,会充填上一个占位值,使程序能够正确调用read函数,就是重定位
不直接在代码段放置并修改占位值,因为代码段不可修改,真正:在调用外部函数时,首先跳转到PLT表,PLT表中的代码会解析函数的真实地址,并将它充填到GOT表中,此后直接跳转GOT表就可以执行对应的外部函数。
3.2 GOT表
全局偏移表,用于记录在ELF文件中所用到的共享库中符号的真实地址
3.3 PLT表
在真正的实现中,并不直接在代码段放置并修改占位值,因为代码段是不可修改的。真正实现方法是:在调用外部函数时,首先跳转到PLT表,PLT标会解析函数真实地址,并填到GOT表中
过程链接表
4、GOT表的攻击利用
GOT表项保存的使外部函数的真实地址
由于GOT表字段需要动态修改,所以它是可写的
修改GOT表字段的值,就可以控制程序流
打印GOT表字段的值,就可以泄露libc地址
库函数指 Linux GNU C 函数库,由 GNU 组织在开发 Linux 时编写。
包括 stdio,ctype,string 等常用库 • 库函数被编译为动态链接库,由各个程序共享。
泄漏 libc 的地址,是完成攻击的重要部分
栈溢出基本原理
1、函数栈调用原理
函数调用栈:是指程序运行时内存一段连续的区域,用来保存函数运行时的状态信息,包括函数参数与局部变量等
栈由高地址向低地址扩展。(相对,堆由低地址向高地址扩展)
函数栈的状态主要涉及三个传感器:
ESP:栈顶指针
EBP:栈底指针
EIP:指向下一条执行的指令(PC)
1.1 参数逆序入栈
将被调用函数的参数逆序压入栈中
64位机首先用寄存器传参,前六个参数被传入RDI,RSI,RDX,RCX,R8,R9,其余参数再压入栈
1.2 保存返回地址
将调用函数进行调用之后的下一条指令地址作为返回地址,压入栈中,目的是保存caller的rip信息
1.3 保存(主调函数的)栈基地址
将调用函数的基地址(ebp的值)压入栈内
将当前栈顶地址传到ebp寄存器内
1.4 进入函数执行
抬高ESP,为新的函数栈留出空间,保留新函数的临时变量
新函数能使用的空间在ESP到EBP之间,EBP不会移动,保证之前栈中的临时变量不会改变
1.5 清理(被调函数的)局部变量
(函数返回的过程)
把EXP挪到EBP的位值,之前ESP和EBP之间的变量都作废
1.6 恢复(主调函数)函数栈
将主调函数的栈基地址从栈中取出,保存到EBP寄存器内,此使栈顶指针ESP指向返回地址
1.7 恢复EIP,清理参数
再将返回地址从栈内弹出,并存到EIP寄存器内
手动或自动清理参数
2、栈溢出
缓冲区溢出(buffer overflow),是针对程序设计缺陷,向程序输入缓冲区写入使之溢出的内容(通常是超过缓冲区能保存的最大数据量的数据),从而破坏程序运行、趁着中断之际获取程序乃至系统的控制权。
缓冲区溢出发生在函数栈时,称为栈溢出
漏洞利用的目的是获得控制权(执行任意指令)
控制程序流,让EIP载入攻击指令的地址
如果我们能在函数返回之前,修改Retrun Address的值,就能让EIP跳转到我们指定的位置。比如说,如果我们写入了一段shellcode,并把Return Address的值修改为shellcode的地址,那么函数返回时就会执行shellcode。
利用缓冲区溢出
当上一个栈的变量(如字符串)使用了危险函数(gets等),就会造成溢出。溢出的数据覆盖后续的变量,直至修改Return Address。
如果将Return Address修改为system函数的地址,就会启动新进程执行一条命令。
3、ROP技术
ROP 返回导向编程,攻击者使用堆栈的控制来在现有程序代码中的子程序中的返回指令之前,立即间接地执行精心挑选的指令或机器指令组。
因为所有执行的指令来自原始程序内的可执行存储器区域,所以这避免了直接代码注入的麻烦,并绕过了用来组织来自用户控制的存储器的指令的执行的大多数安全措施(NX)
3.1 32位
32位架构下,函数的参数保存在栈中
将对应参数布置在栈中即可
返回地址下方是第二次的返回地址
3.2 64位
64位架构下,函数的前六个参数保存 在RDI,RSI,RDX,RCX,R8和 R9中, 如果还有更多的参数才保存在栈里。
劫持控制流后,必须先将参数设置到寄存器中,再跳转到相应的函数执行
对应上文的利用方法,必须先将字符串“/bin/sh”的地址保存在RDI,再跳转到system执行
参数布置在RDI
利用特殊的程序片段(gadget)来设置寄存器的值
利用工具 ROPgadget 来寻找可用的程序片段
ROPgadget –binary stack1-x64 –only “pop|ret”
格式化字符串漏洞
1、格式化字符串原理
格式化字符串函数可以接受可变数量的参数,并将第一个参数作为格式化字符串,根据其解析之后的参数,通俗的来说,格式化字符串函数就是将计算机内存中表示的数据转化为我们人类可读的字符串格式。
printf等
格式化字符串的基本格式如下:
%[parameter] [flags] [fieldwidth] [.precision] [length] type
parameter: 指定第几个参数,用n$指定第n个参数
fieldwidth:指定输出的最小宽度
precision:指定输出的精度(最大宽度)
type:转换说明,指明转换的类型
%d/%i:转换为有符号数
%s:将指定参数作为地址,转换为指向的字符串
length:输出的长度
默认4Byte,h表示2Byte,hh表示1Byte
???
2、格式化字符串漏洞
C语言并未检查格式化字符串和参数的对应关系
(printf(“%d %d %d %s”, 123 , 345))
如果用户能控制格式化字符串,就能够实现:
读取内存值:利用%d,%p打印栈中的值,%s获取指定内存地址的值
修改内存值:利用%n实现对指定内存地址的写入
引发程序崩溃:当%s对应的地址不是可读位置,将引发错误
假设我们能够控制栈的内容,在printf的第二个参数的位置设置为puts@got的地址
“%2$p”:打印puts@got的内容
”aaaaa%2¥n“:将puts@got的内容修改为5
在x64架构下,前六个参数保存于寄存器
局部覆盖
将值 0x080485AF 修改为 0x08048437
只需要覆盖低2Byte即可
大端序:高位字节放在内存的低地址,低位字节放在内存的高地址。
小端序:低位字节放在内存的低地址,高位字节放在内存的高地址。
字符串存放
低地址 高地址
iamfsadsad
整数表示
高位 低位
0x1232BCD
大端 一般书写
低地址 高地址
\x12\x34\xAB\xCD
小端
低地址 高地址
\xCD\xAB\x34\x12
GLIBC HEAP
1、内存分配器
1.1 HEAP
LInux提供两个系统调用来分配动态内存:
brk():扩充或收缩堆的大小
mmap():在内存空间寻找一块区域映射
1.2 内存分配器PTMALLOC2
仅使用这两个函数分配内存,对于应用程序非常不友好
现申请内存块a,再申请b;要想释放b,必须先释放a
内存分配器作为中间层
对应用程序提供接口 malloc/free
使用brk,mmap 系统调用获得内存,并负责管理
Linux 使用 ptmalloc2 作为分配器
2、PTMALLOC数据结构
2.1 PTMALLOC 管理概述
我们称malloc申请所得的内存为 chunk 块
chunk保存了内存分配器用于管理内存的数据结构
chunk有两种状态:使用 (malloc得到), 空闲 (free释放)
空闲chunk不会立即还给操作系统,而被分配器统一管理,存放于bin中
一般相同的chunk组织成为一个双链表,便于索引
2.2 CHUNK结构解析
prev_size:物理地址前一chunk的大小
size:当前chunk的大小,必须是2*SIZE_SZ的整 数倍,即32位架构下,必须是0x8的倍数;64位架 构下,必须是0x10的倍数。因此,低3bit被空出, 作为标志位:
A标志:是否是主分配区(main arena)
M标志:是否是mmap()映射区域
P标志:物理地址前一chunk(prev chunk)是 否正在被使用
prev_size: 物理地址前一chunk的大小
fd/bk: (forward, back)
fd 指向下一个(非物理相邻)空闲的 chunk
bk 指向上一个(非物理相邻)空闲的 chunk
fd_nextsize/bk_nextsize: 仅用于large bin
fd_nextsize 指向前一个与当前 chunk 大 小不同的第一个空闲块,不包含 bin 的头指 针。
bk_nextsize 指向后一个与当前 chunk 大 小不同的第一个空闲块,不包含 bin 的头指针。
2.3 CHUNK的空间复用
chunk的空间复用
当chunk处于使用状态时,其 fd/bk 和 fd_nextsize /bk_nextsize 区域都不起作 用,作为用户数据使用;其释放后,该字段 用于bin中的链表管理。
chunk 处于使用状态时,其物理地址后 一 chunk 的 prev_size 字段不起作用, 作为前一 chunk 的用户数据字段。
2.4 BINS介绍
用户释放掉的 chunk 不会马上归还给系统,ptmalloc 会统一管理 heap 和 mmap 映射区域中的空闲的 chunk。
当用户再一次请求分配内存时,ptmalloc 分配器会试图在空闲的 chunk 中挑选一块合适的给用户。这样可以避免频繁的系统调用,降低 内存分配的开销。
按照chunk的大小和使用状态,设置4种bin进行管理:
fast bin(单链表)
small bin(双链表)
large bin(双链表)
unsorted bin(双链表)
bins是一个数组,每个成员都是一个链 表指针,共127*2个成员。
为了方便起见,我们认为只有127个成员, 每个成员是一对双链表指针。
2.5 堆段的产生和初始化
第一次malloc后,进程会创建堆段 (heap segment)。除了会获得所申请空 间的内存大小,还会获得一个连续的内 存块,称为分配区(arena)
虽然程序可能只是向操作系统申请较小的 内存,操作系统会将一块相当大的空间 (20K)返回给用户程序,交由内存分配器 管理。这样做是为了避免过多地使用系统 调用。
当arena空间不足时,通过brk()来增加堆 空间。同理也可以缩小堆空间。
arena的相关信息记录在arena header 中,即右图所示的结构体内。
2.51 TOP CHUNK
topchunk 位于堆地址最高的位置,该chunk不属于任何bin,是特殊的chunk
当调用 malloc 时,分配器会先尝试在 bins中寻找合适的空闲块分配;如果 bins中没有合适的块,则会尝试 从 topchunk中切割出合适的大小,返回给 用户。
当释放一个chunk时,如果它与 topchunk物理地址相邻,则直接并入 topchunk 。
2.6 FAST BIN
大多数程序经常会申请以及释放一些比较小的内存块。如果将一 些较小的 chunk 释放之后发现存在与之相邻的空闲的 chunk 并 将它们进行合并,那么当下一次再次申请相应大小的 chunk 时, 就需要对 chunk 进行分割,这样就大大降低了堆的利用效率。 因为我们把大部分时间花在了合并、分割以及中间检查的过程中。 因此,ptmalloc 中专门设计了 fast bin,对应的变量就是 malloc state 中的 fastbinsY
32B <= fastbin <= 128B
单向链表。(所以只使用fd,废弃bk )
free时不复位inuse位!(避免合并)
采用LIFO原则(后被释放的chunk将先 被申请到)
fastbin 和 smallbin 的大小有重合,而 fastbin的优先级高于smallbin 。
2.7 SMALL BIN
32B <= smallbin <= 1008B
循环双向链表。为了简化结点的处理,头部也视为一 个结点
free 时inuse位置为 0
采用FIFO原则(先被释放的chunk将先被申请到)
无论是fd指针,还是bk指针,指向的都是chunk header的起始处!
2.8 UNSORTED BIN
unsortedbin 只有一个链表(在 bin 中只占一项),其链表结构组织 方式和 smallbin 相同。
unsorted bin 可以视为空闲 chunk 回归其所属 bin 之前的缓冲区。
当一个较大的 chunk (非topchunk)被分割成两半后,如果剩下的部分大于 MINSIZE(=32B),就会被放到 unsorted bin 中。
释放一个不属于 fast bin 的 chunk,并且该 chunk 不和 top chunk 紧邻 时,该 chunk 会被首先放到 unsorted bin 中。
释放一个不属于 fast bin 的 chunk,并且该 chunk 不和 top chunk 紧邻 时,该 chunk 会被首先放到 unsorted bin 中。
在特定时刻,unsortedbin会清空,将相应的chunk放入smallbin与 largebin。
2.9 LARGE BIN
smallbin 与 fastbin 中,每个链表chunk大小相同;而 largebin 仅限 定大小在一定范围即可。(范围太大,不便于细分)
循环双向链表,额外增设 fd_nextsize 和 bk_nextsize,用于快速适配。
同一链表内,按照chunk的大小进行排序,size大者靠前
相同size,则先释放者靠前。
3、MALLOC/FREE概述
3.1 MALLOC
malloc函数对应libc中的 _libc_malloc函数
_libc_malloc 仅是对 _ int_malloc 的封装,malloc的核心功能由 _int_malloc 实现
3.1.1 _LIBC_MALLOC
检查是否有内存分配函数的钩子函数(_malloc_hook)
如果有,则调用_malloc_hook指向的哈桑农户,并结束malloc
用于用户自定义的堆分配函数
寻找一个可供分配的arena
在指定的arena中申请对应的内存(_int_malloc)
如果分配失败,则尝试在其他的arena中分配
3.1.2 _INT_MALLO
将用户申请的内存大小转换为chunk大小
检查size的范围,先从bins中寻找是否有可用
如果符合fastbin大小,先在fastbin寻找
如果符合smallbin的大小,或者fastbin没有可用块,则在smallbin中寻找
如果都失败,调用malloc_consolidate函数,试图将fastbin的chunk合并,并将 合并后的chunk放入unsortedbin中(避免内存过于碎片化)
再将unsortedbin中的chunk依次取出判断,如果大小完全符合要求,则返回该 chunk;否则将chunk放入对应的bin(smallbin,largebin)
如果仍然失败,则从largebin中寻找最合适的块,必要时会切割chunk
到这里,说明bins中没有合适的chunk。此时将会从topchunk中切割
3.2 FREE
和malloc函数类似,free函数对应libc中的 _libc_free函数
__libc_free 仅是对 _int_free 的封装, free 的核心功能由 _int_free 实现
3.2.1 __LIBC_FREE
检查是否有内存分配函数的钩子函数(__free_hook)
用于用户自定义的堆分配函数
判断当前chunk是否是mmap函数分配的,若是则调用munmap解除映射即
找到当前chunk所在的arena,并从该arena释放该chunk
3.2.2 _INT_FREE
对chunk进行简单检查
指针必须 2*SIZE_SZ 对齐(x64下即 0x10 对齐)
chunk size必须大于 MINSIZE(x64下即 0x20)
检查其inuse标志
若chunk与topchunk相邻,则并入topchunk
检查chunk size的范围:
如果符合fastbin大小,则插入对应size的fastbin头部
如果不符合fastbin,就判断是否可以合并chunk——检查chunk物理地址相邻的前后chunk,若空闲则将它 们合并为一个大chunk。重复执行该步骤。
若发生了合并,且合并后chunk与topchunk相邻,也会并入topchunk,并结束。
将chunk放入对应的bin中(smallbin, largebin)

简单了解一下 SPIR-V
在深度学习编译器领域,SPIR-V是做GPU codegen时常见的IR。另外两个常见的IR是NVVM和ROCDL,这两个都是基于LLVM IR的拓展,分别面向nVidia和AMD的GPU。我们之前介绍过NVVM IR,今天就来简单了解一下SPIR-V,算是先占个坑,后面慢慢补充吧
What is SPIR-V
SPIR-V (standard portable intermediate representation) 是一个由Khronos提出的统一的IR。SPIR-V主要被用于实现Graphics和Parallel Compute领域的Shader、Kernel 编译器[1],目前,Vulkan,OpenGL,OpenCL,LevelZero等常用的drivers都支持SPIR-V。
以OpenCL为例,我们通常使用OpenCL C语言来编写device kernel,并且通过driver中集成的kernel compiler将其编译成可执行的GPU指令。在这种模式下,driver需要维护一个完整的compiler tool chain,来完成从前端OpenCL C到后端GPU指令的编译。如果未来出现了新的kernel语言,driver也必须相应的进行适配,这势必会增加driver实现的复杂程度。 引入SPIR-V之后,driver可以对SPIR-V进行适配,只提供hardware specific的tool chain。前端开发者负责开发前端kernel语言到SPIR-V的转换工具,如下图所示。如此,我们可以去除driver对前端kernel语言的依赖。
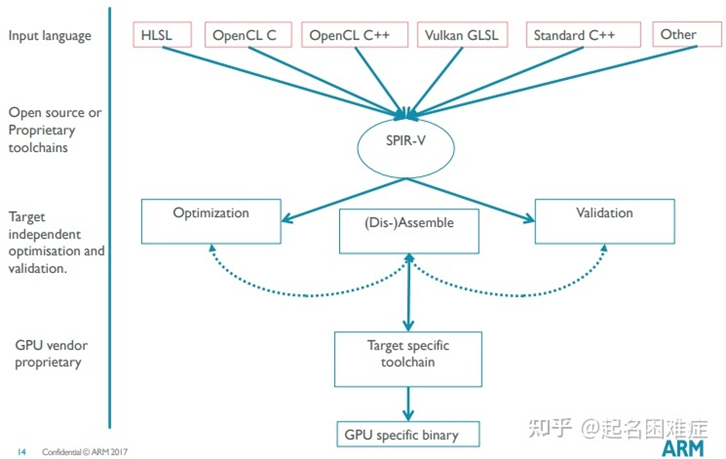
SPIR-V decouple frontend and backend
目前,SPIR-V的生态已经发展的很丰富了。如下图所示,SPIR-V可以与多种常见的IR或语言之间互相转换,Khronos和各种厂商也都提供了多种工具。比如,Khronos提供的spirv-cross工具进行SPIR-V和HLSL/GLSL等shader语言之间的转换,llvm-spirv translator 工具可以进行SPIR-V和LLVM IR之间的转换。

SPIR-V ecosystem
Understand Some Key Concepts in SPIR-V
Physical layout
SPIR-V是一种binary IR,一个SPIR-V模块是一个单线性的words stream。一个word占据32bit的空间。SPIR-V的Spec中直接定义了words stream中每一部分word的语义。如下图所示,一个SPIR-V module中的words可以被分成两部分:第一部分是4个words,是SPIR-V module的head,里面定义了magic number, version number等;第二部分是从第5个word开始存储所有的instructions。

SPIIR-V binary module physical layout
每一个instruction会占据多个words,具体多少个,跟不同的instruction类型有关。但每个instruction所占据的words的排布也是按照特定的格式的。如下图所示,每条instruction的第0个word被分成两部分,低16bit表示该instruction的opcode,比如不同的算数运算等,高16位表示该instruction所占据的word数量。从第1个word开始,分别表示该instruction的result type, result id, operands。
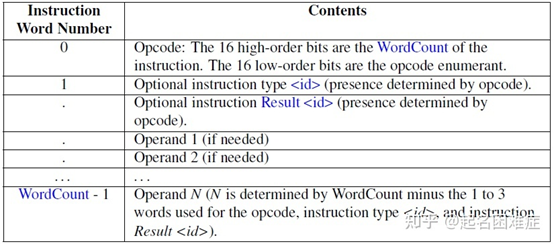
Single instruction physical layout
Spirv-cross和MLIR的spirv Dialect中都提供了对SPIR-V进行序列化和反序列化的code,可供参考。
Every thing is defined by instruction
从上面的描述我们能看到,一个SPIR-V module除了开始4个words的head之外,其他部分都是instructions。其实,在SPIR-V中,所有的内容都是由instruction定义的,包括Type,Capability等。以下图中的code为例,”%6 = OpTypeFloat 32″ 这条instruction定义了一个float32 类型,用%6这个id来表示,而“%10 = OpConstant %6 1”这条指令定义了一个type为%6(也就是float32)值为1的常量%10。

Define a float32 type %6 by using a type declaration instruction
Capability
因为SPIR-V要同时面向Graphics和Prallel Compute,所以它的feature很多,但并不是每个SPIR-V binary都需要用到所有的feature。SPIR-V通过Capability这个概念来区分一个binary究竟用了哪些部分的feature[4]。

An example of 3 used capabilities in a SPIR-V binary
比如,如果我们要面向Vulkan environment,就需要用到Shader feature而不需要用Kernel feature,所以就必须使用Shader Capability。 Validation的时候也会用到Capability,如果binary中实际使用的和定义的Capability不同,validation tools就会报错。
Entry point and execution model
如下图所示,一个SPIR-V的module中可以包含多个function,每个function都由OpFunction instruction定义,并以OpFunctionEnd instruction结束。
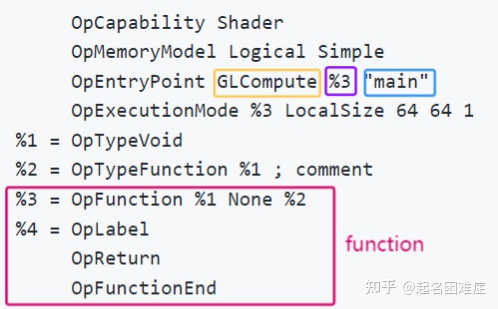
Function in a SPIR-V module
Kernel或者Shader本质上是特殊的function,它们被称为entry point,由OpEntryPoint定义。OpEntryPoint instruction的格式如下,其中Entry Point就是被标记的function (OpFunction instruction的result id),Execution Model表示当前entry point的执行模式,比如是一个OpenGL的compute shader或者OpenCL的Kernel[5]。下图中各个颜色的方框于上图中是对应的。

OpEntryPoint instruction格式
需要注意,ExecutionModel需要跟Capability匹配。如果Capability是Shader,则表示该SPIR-V module是面向Graphics应用的,那其中的EntryPoint的ExecutionModel就不能是Kernel,因为Kernel ExecutionModel是面向OpenCL等Parallel Compute API的。
参考文献链接
https://www.docin.com/p-1987059541.html
https://blog.csdn.net/tj_nonstoper/article/details/124784395
http://www.kaotop.com/it/168644.html
https://blog.csdn.net/weixin_42277902/article/details/125591295
https://zhuanlan.zhihu.com/p/497460602
原文地址:http://www.cnblogs.com/wujianming-110117/p/16864781.html