
Vision Transformer 的学习与实现
Transformer最初被用于自然语言处理领率,具体可见论文Attention Is All You Need。后来被用于计算机视觉领域,也取得了十分惊艳的结果(An Image Is Worth 16×16 Words: Transformers For Image Recognition At Scale),以至于现在的transformer大行其道。现在就来学习一下。
Vision Transformer 主要应用了NLP Transformer中的Encoder模块,而且总体的结构和处理过程基本保持了一致,成功将图像问题转换成序列问题。
下图是Vision Transfomer的具体结构和流程
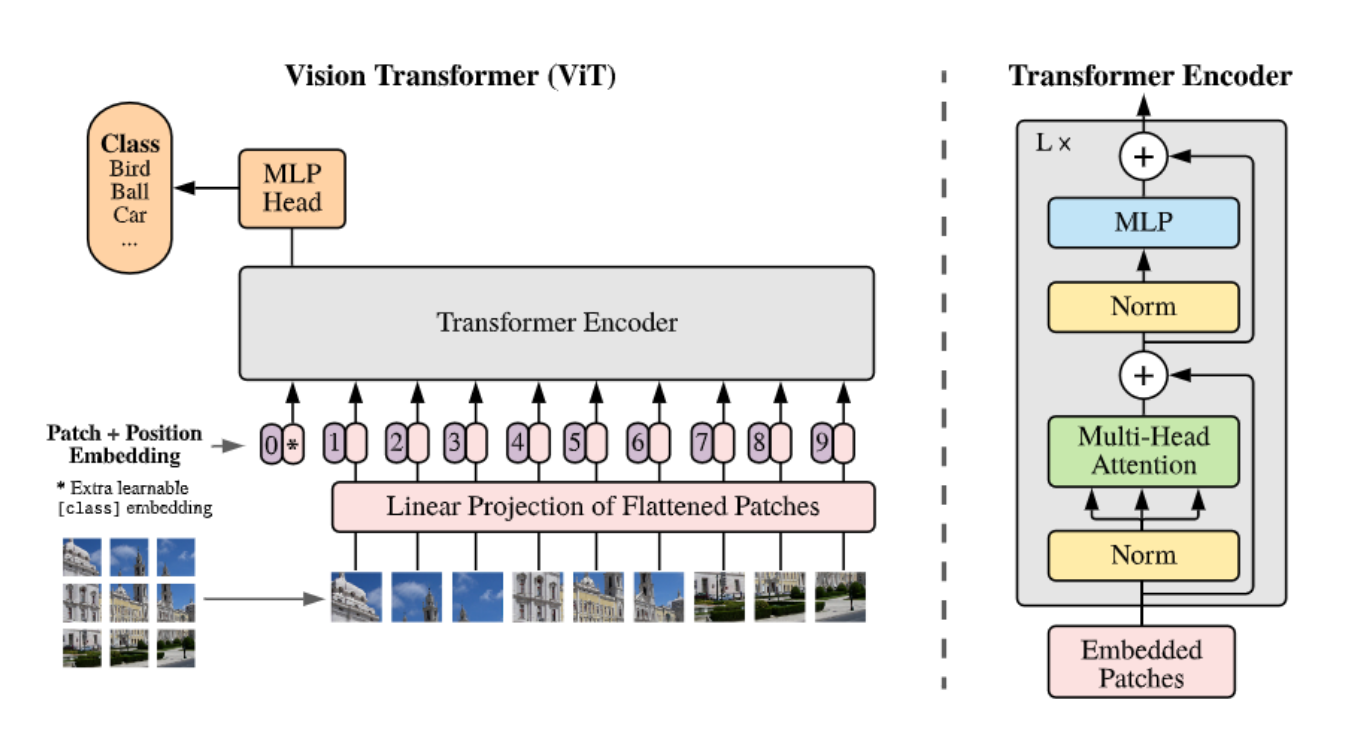
ViT的结构
Vision Transformer 的结构总体而言可以分为3个部分
-
Linear Projection of Flattened Patches (对切分的图像Patch,进行Embedding)
-
Transformer Encoder(Transformer的主要结构)
-
MLP Head (MLP分类头)
接下来我们将介绍这三个结构的一些细节
Linear Projection of Flattened Patches
在标准的Transformer模型中,处理的输入是token序列,是(num_token, num_dim)的二维向量。而图像的表示一般都是(H, W, C)的三维矩阵。因此ViT会先将图像切成若干个大小相等的Patch。
以宽高都为224的图像为例,一张图片的形状为(224, 224, 3),然后我们把他切成若干大小为16 * 16的Patches,因此我们可以得到 (224/16)^2 = 196个Patches,即从(224, 224, 3)可以变换为(196, 16, 16, 3)。之后我们把后三个维度处理成一个维度,即可得到一个(196, 768)的二维向量(196个token,每个token的维度是768),就成功将图像转换成了一个序列。
最后我们进行一个投影操作,也就是ViT的第一个主要结构,将token的维度数量投影到某一个规定的D。
此外,将这个序列输入进Encoder之前,还需要两个操作。第一,是加一个用于分类的class token(参考自Bert)。这个token的尺寸和之前的token序列相同,然后进行一个concate操作,那么最终输入进Encoder的序列尺寸就是(197, 768)。
第二,由于图像本身固有位置信息,而Transformer关注全局信息,缺少之前CNN的偏执归纳,因此需要加上位置编码。由于是一个加操作,token序列的尺寸仍无变化。
Transformer Encoder
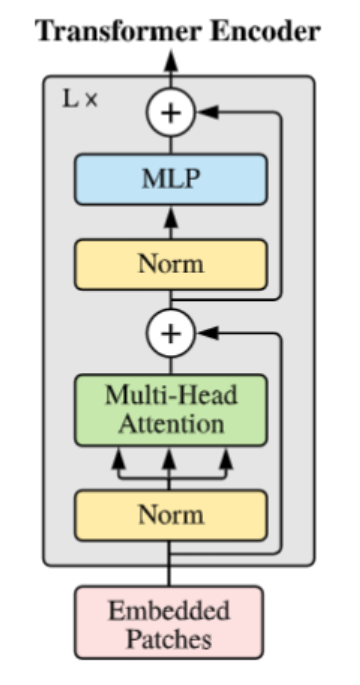
Transformer Encoder可以说是直接移植自NLP领域的Transformer。包括LayerNorm,Multi-Head Attention 和 MLP等操作,此外还有残差连接。
LayerNorm
层归一化,将数据分布拉到激活函数的非饱和区,类似于BatchNorm。至于这里为什么用LayerNorm,主要是因为在原生Transformer中,不同的mini-batch可能具有不同的输入长度(NLP问题),会导致BatchNorm出现问题,因此使用了LayerNorm。

-
BatchNorm:batch方向做归一化,计算N * H * W的均值
-
LayerNorm:channel方向做归一化,计算C * H * W的均值
在此过程中输出的维度不变。
Multi-Head Attention
多头注意力是Transformer的核心结构。注意力是指给定一个查询query,与所有的key-value对中的key进行注意力权重运算,最后通过该权重加权value运算。这里用到的注意力运算是点积运算,其中Q代表的是query,K代表的是key, V代表的是value,D代表特征长度。
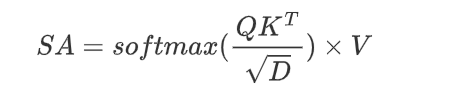
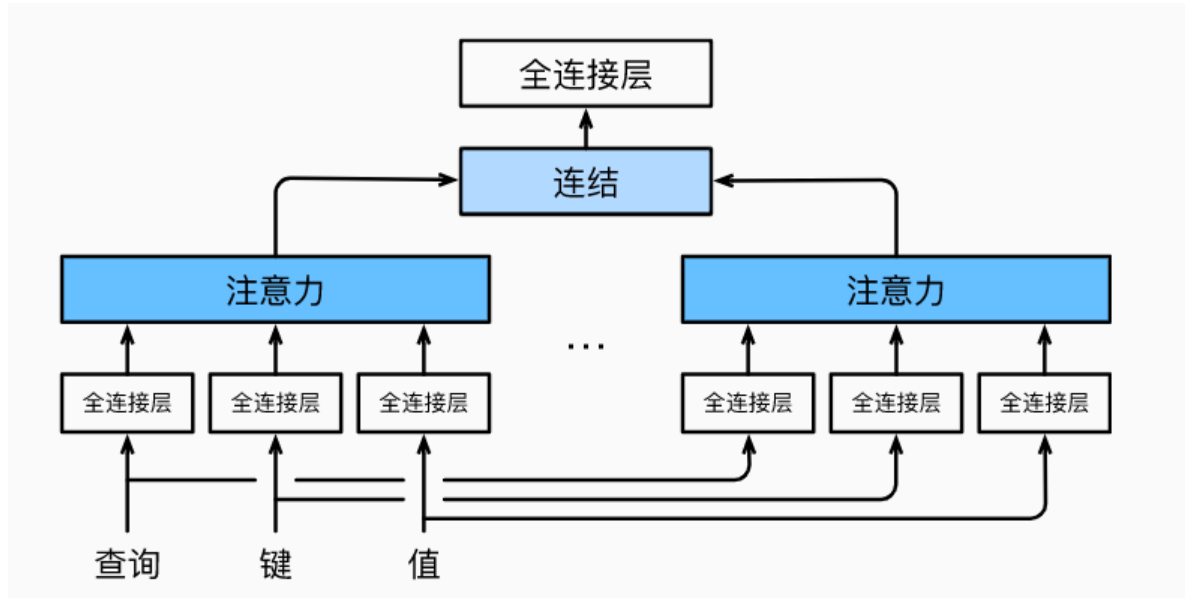
对同一组查询、键和值,根据多头注意力头的个数n,将其拆分成n份,送入不同的点积注意力模块。然后将得到的多个结果concate起来,最终经过一个全连接层输出。这种设计让每个注意力头可以关注不同的部分,有点类似于卷积层有多个卷积核关注不同特征通道的信息。在ViT中,使用的是自注意力机制,一个注意力头中的Q,K,V是同一个token序列 (num_token, num_dim)。
在Encoder中,尺寸为(197, 768)的token序列,被拆分成12份,形成12个(197, 64)的子token组,然后送入多头注意力。在注意力运算中Q(197, 64) , K^T(64, 197), V(197,64), 得到的结果是(197, 64)。然后将12个头concate起来,再经过一个全连接层,结果仍是(127, 768)。
MLP
这里的MLP就是两个全连接层,将token序列维度升维(197, 3072),然后再降维(197, 768),使其输出仍保持在(num_token, num_dim)上。激活函数是GELU。
因此通过一个Transformer Encoder,token序列的尺寸不变,因此可以在ViT中堆叠多个Encoder。除此之外,在Encoder中还有残差连接。
MLP Head
分类头,用于最终的分类。我们提取来自Encoder的输出,在197个token中,我们只要与分类有关的class token。即(1, 768)。然后通过全连接层和tanh激活函数等结构,进行分类。这样整个流程就结束了。
ViT的Pytorch实现
在Pytorch中,torch.nn模块里已经集成了MultiHeadAttention和TransformerEncoder,因此可以简洁实现。不过出于学习的目的,还是参考网上的许多资料自己手动实现一下。最核心的部分还是TransformerEncoder,其他部分在ViT里能较为轻松实现。
Transformer Encoder
Encoder的LayerNorm层,就一个简单的LayerNorm,残差连接在后边的forward中实现。
class Norm(nn.Module):
def __init__(self, num_dim):
super(Norm, self).__init__()
self.norm = nn.LayerNorm(num_dim)
def forward(self, x):
x = self.norm(x)
return xEncoder的MLP层,简单的Linear组合。
class MLP(nn.Module):
def __init__(self, num_dim, hidden_num, dropout=0.):
super(MLP, self).__init__()
self.mlp = nn.Sequential(
nn.Linear(num_dim, hidden_num),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_num, num_dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.mlp(x)多头注意力层,这个有些复杂,参考了动手学深度学习的实现方式。包括点积注意力,和两个用于转换token序列形状其实能够在多头注意力并行计算的辅助函数,最后就是多头注意力。在具体的实现中,给tensor的形状做了注释,方便理解。
class DotProductAttention(nn.Module):
def __init__(self, dropout):
super().__init__()
self.dropout = nn.Dropout(dropout)
def forward(self, q, k, v):
# q(batch, q_size, d) k(batch, k_size, d) v(batch, v_size, d)
d = q.shape[-1]
scores = torch.bmm(q, k.transpose(1, 2)) / math.sqrt(d)
# (batch, q_size, v_size)
attention_weights = F.softmax(scores, dim=1)
# (batch, q_size, v_size) * (batch, v_size, d)
return torch.bmm(self.dropout(attention_weights), v)
# (batch, q_size, d)
def transpose_qkv(x, num_heads):
# batch_size, num_token, num_dim
x = x.reshape(x.shape[0], x.shape[1], num_heads, -1)
# batch_size, num_token, num_heads, num_dim / num_heads
x = x.permute(0, 2, 1, 3)
# batch_size, num_heads, num_token, num_dim / num_heads
return x.reshape(-1, x.shape[2], x.shape[3])
# batch_size * num_heads, num_token, num_dim / num_heads
def transpose_output(x, num_heads):
# (batch_size*num_heads, num_token, num_dim/num_heads)
x = x.reshape(-1, num_heads, x.shape[1], x.shape[2])
# (batch_size, num_heads, num_token, num_dim/num_heads)
x = x.permute(0, 2, 1, 3)
# (batch_size, num_token, num_heads, num_dim/num_heads)
return x.reshape(x.shape[0], x.shape[1], -1)
# (batch_size, num_token, num_dim)
class MultiHeadAttention(nn.Module):
def __init__(self, q_size, k_size, v_size, num_dim, num_heads, dropout, bias=False):
super().__init__()
self.num_heads = num_heads
self.attention = DotProductAttention(dropout)
self.wq = nn.Linear(q_size, num_dim, bias)
self.wk = nn.Linear(k_size, num_dim, bias)
self.wv = nn.Linear(v_size, num_dim, bias)
self.wo = nn.Linear(num_dim, num_dim, bias)
def forward(self, q, k, v): # num_dim = qkv_size
# q, k, v (batch_size, num_token, num_dim)
# q, k, v (batch_size, num_token, num_dim)
q = transpose_qkv(self.wq(q), self.num_heads)
k = transpose_qkv(self.wk(k), self.num_heads)
v = transpose_qkv(self.wv(v), self.num_heads)
# (batch_size*num_heads, num_token, num_dim/num_head)
out = self.attention(q, k, v)
# (batch_size*num_head, num_token, num_dim/num_head)
out = transpose_output(out, self.num_heads)
# (batch_size, num_token, num_dim)
return self.wo(out)
# (batch_size, num_token, num_dim)然后我们把上边实现的组件合体起来,构成ViT的一个Encoder模块。
class TransFormerEncoder(nn.Module):
def __init__(self, num_dim, num_heads, dropout, num_hidden):
super(TransFormerEncoder, self).__init__()
self.norm1 = Norm(num_dim)
self.norm2 = Norm(num_dim)
self.attention = MultiHeadAttention(q_size=num_dim, k_size=num_dim, v_size=num_dim,
num_dim=num_dim, num_heads=num_heads, dropout=dropout)
self.mlp = MLP(num_dim, num_hidden, dropout)
def forward(self, x):
y = self.norm1(x)
y = self.attention(y, y, y)
tmp = y + x # shortcut
out = self.norm2(tmp)
out = self.mlp(out)
return out + tmp # shortcutVision Transformer
之后我们可以直接实现Vision Transformer,它的处理流程基本如下, 以batch_size=4, img_size=224, patch_size=16, num_dim=768, num_hidden=3072为例,也讲述一下tensor的变换形状。
-
将图片tensor切分成patches,可以使用eniops的rearrange,实现tensor的快速切分,然后图片就可以处理成序列。
(4, 3, 224, 224)—-(4, 196, 768)
-
然后对切分的patches做一个embedding操作,使用Linear线性层即可。
(4, 196, 768)—-(4, 196, 768)
-
给处理好的patches,concate一个class token。class token的形状和处理好的patches token一致,都是(196, 768)
(4, 196, 768)—-(4, 197, 768)
-
对于位置编码,采用了比较简单的可学习的位置编码,通过nn.Parameter实现。
采用加操作,不改变形状
-
进入Transformer Encoder。Encoder输入输出形状一致,也因此可以堆叠多个。
形状不变
-
最后取出class token,接一个分类头
(4, 768) —- (4, num_class)
class ViT(nn.Module):
def __init__(self, num_dim, num_embedding, num_hidden, num_layer, num_heads, dropout,
num_class=102, img_size=224, patch_size=16):
super(ViT, self).__init__()
self.num_patch = (img_size // patch_size) * (img_size // patch_size)
self.split_patch = Rearrange('b c (p1 h) (p2 w) -> b (h w) (p1 p2 c)', p1=patch_size, p2=patch_size)
self.embedding = nn.Linear(num_dim, num_embedding) # num_dim = num_embedding
self.pos = nn.Parameter(torch.randn(1, self.num_patch + 1, num_dim)) # 可学习位置编码
self.cls_token = nn.Parameter(torch.randn(1, 1, num_dim)) # class token
self.encoder = nn.Sequential()
for i in range(num_layer):
self.encoder.add_module(f'encoder {i}', TransFormerEncoder(num_dim, num_heads, dropout, num_hidden))
self.head = nn.Sequential(
nn.LayerNorm(num_dim),
nn.Linear(num_dim, num_class)
)
def forward(self, x):
x = self.split_patch(x)
batch, num_token, _ = x.shape
x = self.embedding(x) # (batch, num_token, num_dim)
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=batch) # (batch, num)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos
x = self.encoder(x)
x = x[:, 0] # 取出class token
out = self.head(x)
return out然后我们随便用一个randn生成一个tensor,看看能否跑通


应该是没有问题的。
ps. 个人的实现可能在一些细节方面同原著有些不一样,以后可能会再改进,欢迎大家批评指正。
102种鲜花分类
原文地址:http://www.cnblogs.com/Brisling/p/16793093.html