
前言
模型量化这个概念在深度学习领域已经很常见了,它主要是通过使用定点数表示模型中的weights和运行时的activations来实现对模型尺寸的压缩和运行的加速。
什么是量化?
量化是数学运算与数字信号处理里广为使用的一种方法,它将一个大的集合种的输入数字映射到一个小的集合中的数字,这个小的集合一般是有限集。这样做可以带来两个好处:
- 减少内存消耗,增加数据吞吐量,可以用缓存机制存放更多中间结果,减少重复计算;
- 量化的结果可以被更快的处理,一般硬件会对量化的结果的运算做优化。
最常见的量化应用场景是通信里面对语音信号的处理,在打电话的过程中你的声音信号先被量化成8位的数字信号,经过传输到达对方后再被恢复成声音信号,其实它是一个有损的信息压缩方法。这也是为什么电话里面听到得声音与当面说话得声音有差异得原因,因为量化在一定程度上出现了信息的丢失。
深度学习中的量化
深度学习中处理的数据是浮点数,常见的做法是将64位的浮点数转化位数较低的整数,具体采用的方法被称为uniform quantization。
假设问题中涉及到的浮点数的范围为 r∈(Xmin,Xmax) ,量化后的范围变为 q∈(0,nlevels−1) ,那么量化的公式为
quantization:q=Z+rSde−quantization:r=S(q−Z)
其中:
- S 为尺度(Scale),它定义了量化的步长,如果浮点数的变换小于这个步长,量化结果将不变;
- Z 是零点(Zero-point), Xmin 的量化结果。
矩阵乘法
矩阵乘法是神经网络中最为常见得计算,我们看看如何用量化来实现矩阵乘法。
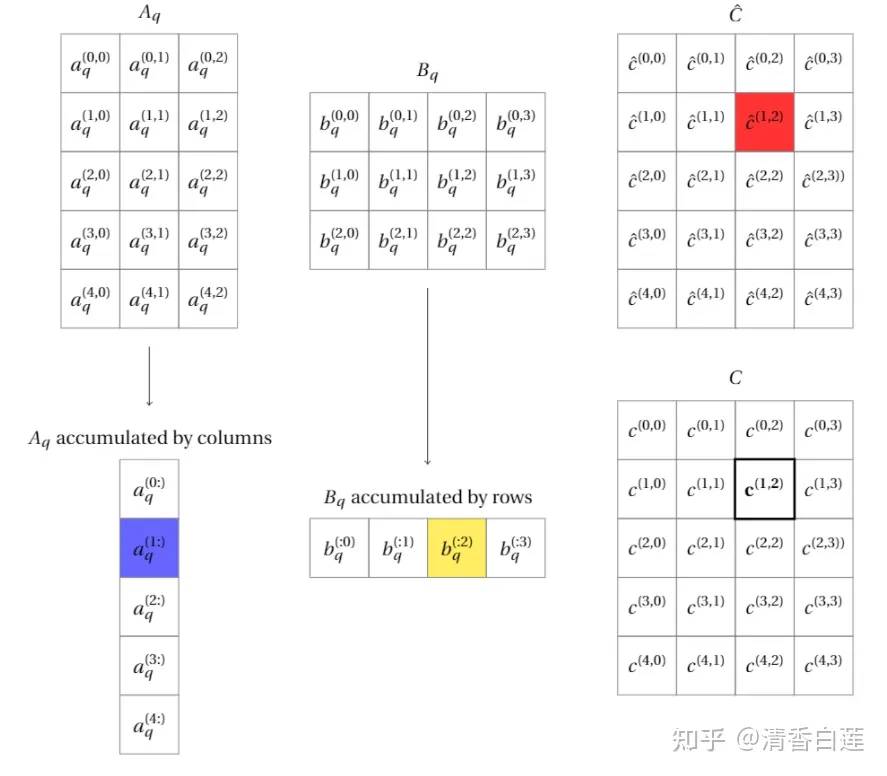
假设 A 与 B 分别是 M∗K 与 K∗N 的矩阵,现在先将矩阵 A 与 B 量化,那么就可以通过量化后的矩阵的低精度整数运算近似得到直接相乘的结果,整个过程如下

具体流程为,先将 A 与 B 量化为整数矩阵
Aq:A(i,k)=Sa(Aq(i,k)−Za),i∈(0,M),k∈(0,K)
Bq:A(k,j)=Sb(Bq(k,j)−Zb),k∈(0,K),j∈(0,N)
那么矩阵A 与 B 的相乘可以简化为量化后的整数矩阵相乘,即
Cq:C(i,j)=∑k=0KA(i,k)∗A(k,j)=SaSb∑k=0KK((Aq(i,k)−Za)((Bq(k,j)−Zb)=
SaSb∑k=0KAq(i,k)Bq(k,j)−Za∑k=0KBq(k,j)−Zb∑k=0KAq(i,k)+KZaZb=
SaSbCq(i,j)−Za∑k=0KBq(k,j)−Zb∑k=0KAq(i,k)+KZaZb
可以看出计算矩阵A 与 B 的相乘的结果 C 中的每个元素需要量化矩阵的计算结果得到。
神经元的量化计算
神将网络中的神经元的计算逻辑是将输入信息一个线性变换再灌入一个非线性的激活函数,比较常见的是RELU函数,整个过程如下
Linear:z=wx+bReLU:y=max(z,0)
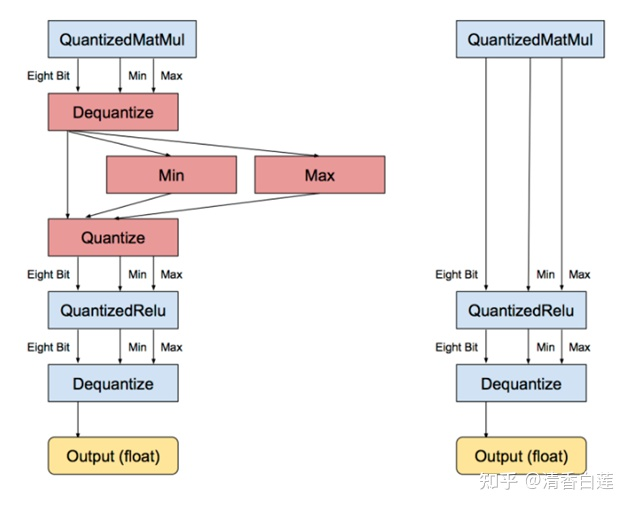
针对神经元/感知机的计算的量化有两种解决方案:
- 直接对weights量化,如下图左边所示,需要分两步,先对线性变换部分涉及的矩阵做量化,并对量化矩阵做计算,然后再对量化计算结果做dequantize,得到的结果再做量化完后输入QuantizedRelu,再做dequantize。
- 权重与激活函数的联合量化,如下图右边索斯,直接省略中间针对的线性变换量化计算结果的dequantize以及后面下一步的quantize。需要有校准数据,计算激活函数输出的范围,以确定联合量化的计算公式。
模型量化方式
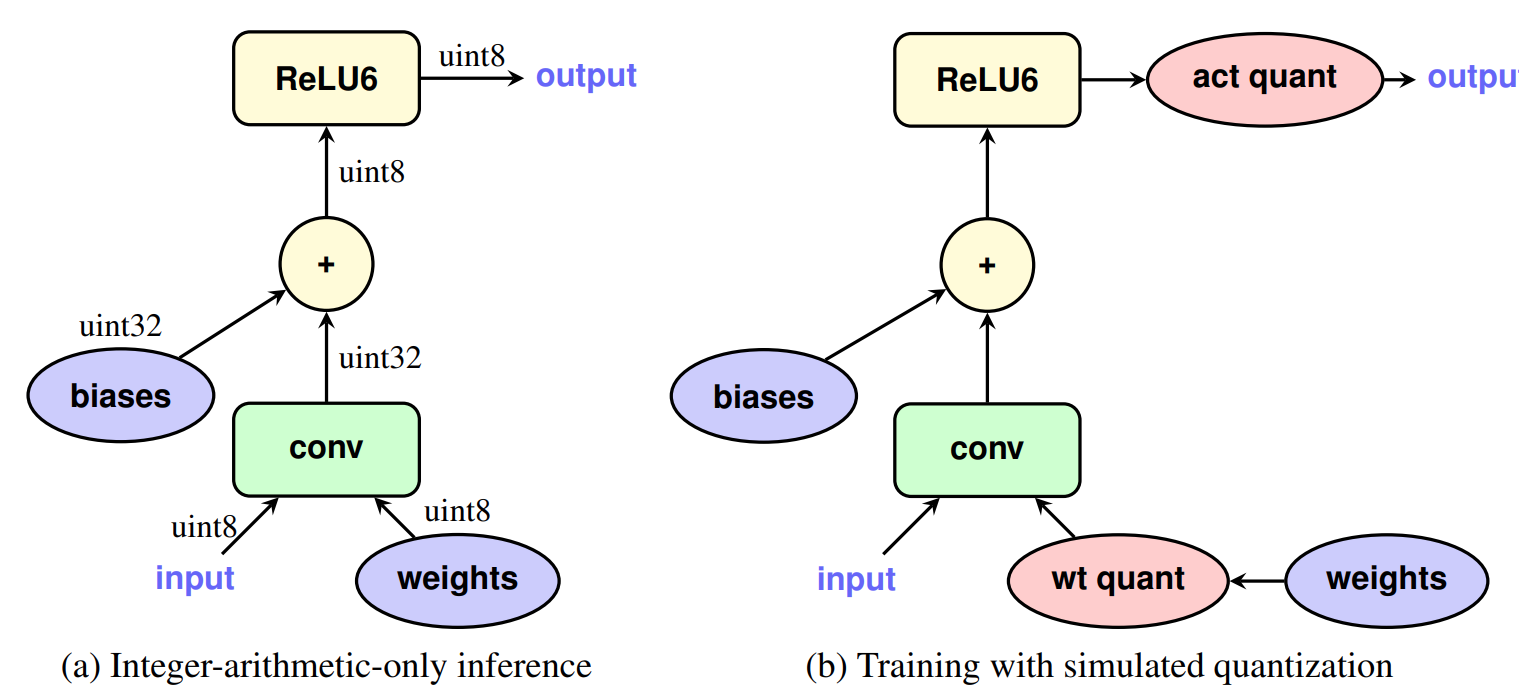
- 训练后量化:模型训练好之后再进行量化,这种方法一般对大模型效果不错,对小模型则效果比较差。
- 量化感知训练:在训练过程中对模型参数,inference与training使用的是量化过后的weights和activation,如下图所示。由于训练的loss能够反应了模型部署时的实际计算方式,所以效果一般会好过训练后量化,但训练方式变得更复杂。
参考:
Quantization and training of neural networks for efficient integer-arithmetic-only inference
补充:混合精度量化
就目前而言,8 bit及其以上的量化已经基本做到了无损,且已经可以在各个框架中直接一键转换了,8 bit以下的量化还处在各种论文刷SOTA的阶段,感觉还没有大规模工程化,尤其是1-bit,比如ResNet18的二值模型在ImageNet上离全精度至少还有五六个点的差距(保持原有结构的情况下)。
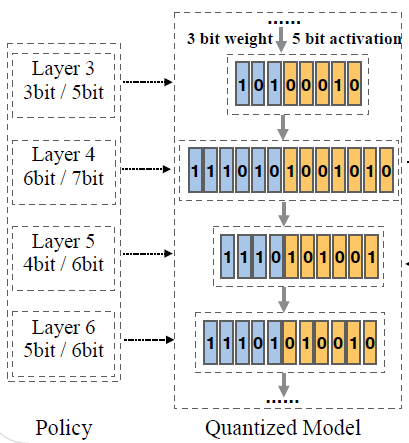
传统的模型量化方法都是将整个模型的weights和activations都固定量化到某个固定的bit位,但有个问题就是:高bit的量化能保证高精度但内存占用和计算量也更大,低bit的量化精度更低但内存占用和计算量更小,所以固定bit下的量化始终无法在Accuracy和 (FLOPs & Parameters)之间达到一个非常细粒度的trade-off,所以就需要混合精度量化(Mixed-Precision Quantization, MPQ)来对模型实现进一步的高效压缩。
混合精度量化区别于混合精度训练这个概念,后者指的是在模型训练过程中使用FP16来代替传统的FP32从而达到占用显存更少,计算速度更快的目的,而本文要谈的混合精度量化指的是通过设计某种policy,来对模型各层的weights和activations的量化bit位宽进行合理分配,如下图所示,其重点就是如何设计这个policy,从而使得混合精度量化之后模型能够在精度和硬件指标上达到最佳的平衡。
参考:混合精度量化(Mixed-Precision Quantization)相关论文总结
原文地址:http://www.cnblogs.com/carsonzhu/p/16868879.html