
回文自动机
基础操作
两个初始状态一个长度为 \(0,-1\) 的偶回文根和奇回文根。
转移 \(\delta(x,c)\) 从 \(x\) 节点代表的回文串转移到两端加入字符 \(c\) 后到达的节点。
\(fail(x)\) 指针,指向自身的后缀最长回文串。特殊地,偶回文根指向奇回文根,奇回文根没有 \(fail\) 指针,因为奇回文根不会失配。
怎么构建呢,考虑增量构建法。
加一个字符,假设当前加入的是第 \(p\) 个字符。
我们从上一次到达的点,一直跳 \(fail\) ,找一个边上可以扩展的一个点停下,也就是第一个满足 \(s[p-len_x-1]=s[p]\) 的点 \(x\)。看它是否有 \(\delta(x,s[p])\) 的转移,有就不管,没有就新建节点。新建节点的 \(fail\) 指针通过 \(x\) 再跳一次 \(fail\) 找到第一个满足前面条件的点确定。
为什么从上一次插入时到达的点开始?因为它是以 \(p-1\) 为结尾的一个尽可能长的回文串。为什么只用改第一个满足条件的点?这是因为后面的满足条件的点必定在之前出现过,这个我们稍晚一点给出证明。
关于为什么暴力跳 \(fail\) 的时间复杂度有保证,这是因为我们每次插入时的起点是上一次跳到的点。每次我们跳一次 \(fail\) ,在 \(fail\) 树上的深度至少减一,而连接一个 \(fail\) 只会深度加一,可得复杂度线性。
关于插入时后面的满足条件的点必定出现过的证明。因为后面的点必定为前面的点的后缀,这些点又是回文,所以它前面肯定出现过。以及,状态数是线性的,这个可以通过刚才说的进行归纳证明。因为转移的节点唯一,然后转移数同样是线性的。
边界情况,偶根作为 \(0\) 的话可以解决一起。
#include<bits/stdc++.h>
#define ll long long
#define db double
#define file(a) freopen(#a".in","r",stdin),freopen(#a".out","w",stdout)
#define sky fflush(stdout)
#define gc getchar
#define pc putchar
namespace IO{
template<class T>
inline void read(T &s){
s=0;char ch=gc();bool f=0;
while(ch<'0'||'9'<ch) {if(ch=='-') f=1;ch=gc();}
while('0'<=ch&&ch<='9') {s=s*10+(ch^48);ch=gc();}
if(ch=='.'){
T p=0.1;ch=gc();
while('0'<=ch&&ch<='9') {s=s+p*(ch^48);p/=10;ch=gc();}
}
s=f?-s:s;
}
template<class T,class ...A>
inline void read(T &s,A &...a){
read(s);read(a...);
}
template<class T>
inline void print(T x){
if(x<0) {x=-x;pc('-');}
static char st[40];
static int top;
top=0;
do{st[++top]=x-x/10*10+'0';}while(x/=10);
while(top) {pc(st[top--]);}
}
template<class T,class ...A>
inline void print(T s,A ...a){
print(s);print(a...);
}
};
using IO::read;
using IO::print;
const int N=5e5+3;
int n;
char la_ans;
struct Pali_auto{
int len[N+2],fail[N+2];
int tr[N+2][26];
ll cnt[N+2];
char s[N];
int tot,la,tip;
inline int newnode(int L){
len[++tot]=L;
memset(tr[tot],0,sizeof(tr[tot]) );
fail[tot]=cnt[tot]=0;
return tot;
}
inline void build(){
tot=-1;
la=tip=0;
newnode(0);
newnode(-1);
fail[0]=1;
}
inline int extend(int x){
while(s[tip-len[x]-1]!=s[tip]){
x=fail[x];
}
return x;
}
inline ll ins(char ch){
s[++tip]=ch;
int c=ch-'a';
int x=extend(la);
if(!tr[x][c]){
int y=newnode(len[x]+2);
fail[y]=tr[extend(fail[x])][c];
cnt[y]=cnt[fail[y] ]+1;
tr[x][c]=y;
}
la=tr[x][c];
return cnt[la];
}
}t;
char s[N];
int main(){
file(a);
scanf("%s",(s+1) );
n=strlen(s+1);
t.build();
for(int i=1;i<=n;++i){
//pc(s[i]);
ll k=t.ins(s[i]);
printf("%lld ",k);
s[i+1]=(s[i+1]-97+k)%26+97;
}
return 0;
}
一点性质
性质1
回文串的 \(border\) 是回文串。其回文后缀为其 \(border\)。
证明:
在 \(s\) 为回文的前提下,其 \(border\) 相等且互为反串,得证。
性质2
一个串 \(s\) 的半长(及以上)的 \(border\) 为回文串,则 \(s\) 为回文串。
证明:
达到半长可覆盖全串,易证。
性质3
回文串 \(x\) ,\(y\) 为 \(x\) 的最长回文真后缀,\(z\) 为 \(y\) 的最长回文真后缀, \(u,v\) 满足 \(x=uy,y=uz\),则:
1.\(|u|\ge |v|\)。
2.若 \(|u|>|v|\) ,则 \(|u|>|z|\) 。
3.若 \(|u|=|v|\),\(u=v\)。
证明:
1.显然 \(|u|\) 为 \(x\) 的最小周期,\(|v|\) 为 \(y\) 的最小周期。由 \(y\) 为 \(x\) 的 \(border\) 兼后缀,\(|u|\) 也为 \(y\) 的周期。若 \(|u|>|v|\) ,则 \(|v|\) 为 \(y\) 的最小周期不成立,矛盾。因此 \(|u|\ge |v|\)。
2.首先 \(v\) 为 \(x\) 前缀,设字符串 \(w\) 满足 \(x=vw\) ,则 \(z\) 为 \(w\) 的 \(border\) (由 \(y=vz\))。假设 \(|u|\le |z|\) ,则 \(|zu|=|w|\le 2|z|\),则 \(w\) 为回文串,\(w\) 为 \(x\) 的 \(border\)。再由 \(|u|>|v|\) ,得 \(|zu|=|w|>|vz|=|y|\),与 \(y\) 为最长回文后缀相矛盾。所以 \(|u|>|z|\)。
3.因为 \(u,v\) 皆为 \(x\) 的前缀,且长度相等,因此 \(u=v\)。
性质4
字符串 \(s\) 的所有回文后缀按长度排序后可划分为 \(O(\log |s|)\) 组等差数列。
证明:
对于 \(s\) 的最长回文后缀的 \(border\) 使用 border理论性质5 即可。
或者用性质3可知每次相邻的三个回文后缀长度,最小的长度必定小于最大的长度的一半。
应用
本质不同回文子串个数
除去初始状态后的状态数量。
回文子串出现次数
在 \(fail\) 树上做个 topo 排序累加一下子树中串出现次数即可。
最小回文划分
问最少将字符串 \(s\) 划分成多少个部分使得其各部分回文。
设 \(f[i]\) 表示前缀 \(s[1,i]\) 的最小回文划分,朴素的DP转移式是:(\(pali\) 为回文缩写)
回文子串个数是 \(O(n^2)\) 的,直接做会寄。
考虑回文后缀会划分成 \(O(\log |s|)\) 个等差数列。我们可以维护整个等差数列的 \(f\) 贡献和。记 \(g[x]\) 为从 \(x\) 开始的等差数列贡献和,\(dif[x]\) 表示 \(len[x]-len[fail[x] ]\),\(slink[x]\) 为 \(x\) 的 \(fail\) 父亲链上第一个满足 \(dif[p]\not=dif[fail[p] ]\) 的 \(p\)。我们的等差数列的贡献不包括 \(slink\) ,\(slink\) 的贡献放到下一个等差数列中计算。
首先知道一个结论,若 \(x\) 与 \(fail[x]\) 位于同一等差数列,那么 \(fail[x]\) 的上一次出现位置为 \(i-dif[x]\),这个结论我们等会给出证明。那么你发现 $g[fail[x]] $ 保存的贡献只比 \(g[x]\) 存的少一个。因为它原来保存的贡献位置只差为 \(dif[x]\) ,而现在 \(fail[x]\) 向后移动了 \(dif[x]\) 并加上了 \(x\) 的贡献,所以 \(x\) 把原来平移走的贡献补上,多出来的是 \(g[fail[x] ]\) 中最后一个贡献平移之后的结果,这个贡献是 \(f[i-dif[x]-len[slink[x] ]]\)。这么干讲可能比较抽象,我把 OI-wiki 那个图抽过来。
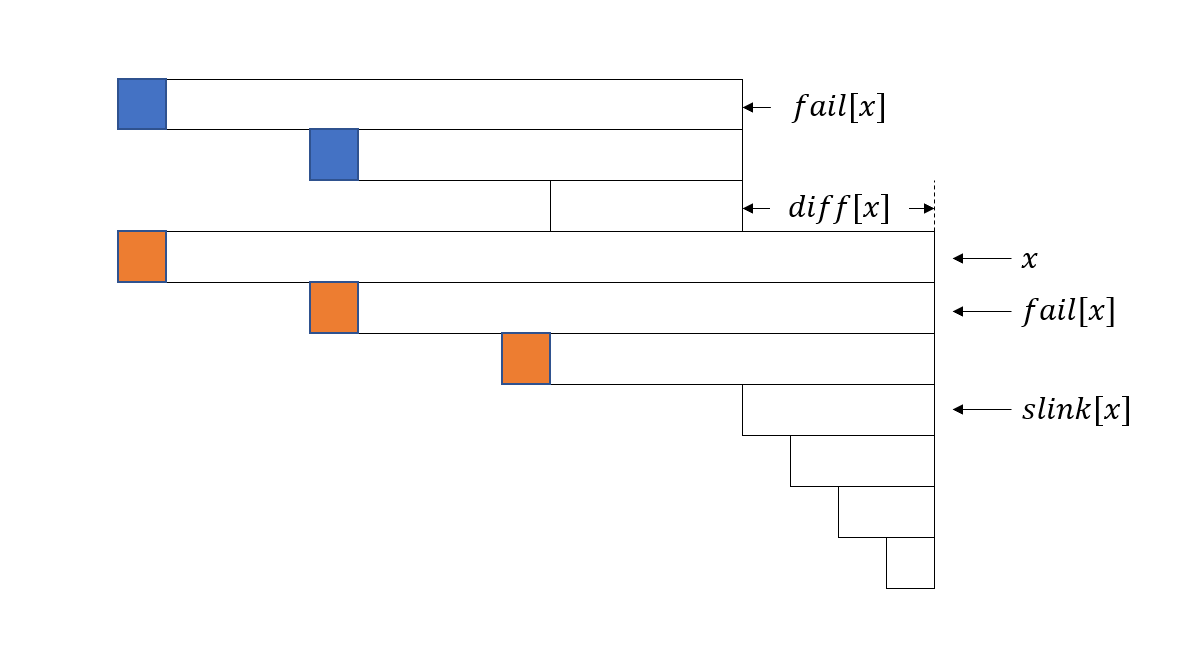
大概就是这样?
关于那个结论:“若 \(x\) 与 \(fail[x]\) 位于同一等差数列,那么 \(fail[x]\) 的上一次出现位置为 \(i-dif[x]\) ” 的证明。
啊,首先 \(fail[x]\) 肯定是在 \(i-dif[x]\) 出现过的。只要证明 \(fail[x]\) 在 \((i-dif[x],i)\) 中不曾出现即可。考虑反证,假设 \(fail[x]\) 在区间 \((i-dif[x],i)\) 出现过,由于他们属于同一等差数列(这里指 \(dif\) 相等)有 \(2|fail[x]|\ge |x|\) ,显然 \(fail[x]\) 与前面的 \(i-dif[x]\) 位置的 \(fail[x]\) 有交。记交集为 \(a\),\(b\) 满足 \(ab=fail[x]\) 。显然 \(aba\) 为回文串,这个比 \(fail[x]\) 长,与 \(fail[x]\) 为 \(x\) 的最长回文后缀矛盾,因此得证。
原文地址:http://www.cnblogs.com/cbdsopa/p/16871305.html