
【实验目的】
理解朴素贝叶斯算法原理,掌握朴素贝叶斯算法框架。
【实验内容】
针对下表中的数据,编写python程序实现朴素贝叶斯算法(不使用sklearn包),对输入数据进行预测;
熟悉sklearn库中的朴素贝叶斯算法,使用sklearn包编写朴素贝叶斯算法程序,对输入数据进行预测;
【实验报告要求】
对照实验内容,撰写实验过程、算法及测试结果;
代码规范化:命名规则、注释;
查阅文献,讨论朴素贝叶斯算法的应用场景。
| 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
| 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 碍滑 | 是 |
| 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 碍滑 | 是 |
| 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 碍滑 | 是 |
| 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 碍滑 | 是 |
| 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 碍滑 | 是 |
| 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 是 |
| 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 是 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 是 |
| 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 否 |
| 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 否 |
| 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 否 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 否 |
| 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
解答:
1.针对下表中的数据,编写python程序实现朴素贝叶斯算法(不使用sklearn包),对输入数据进行预测


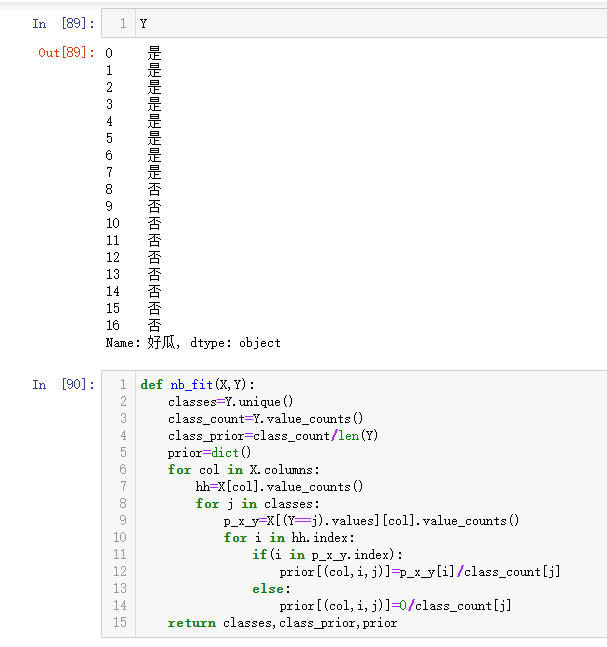

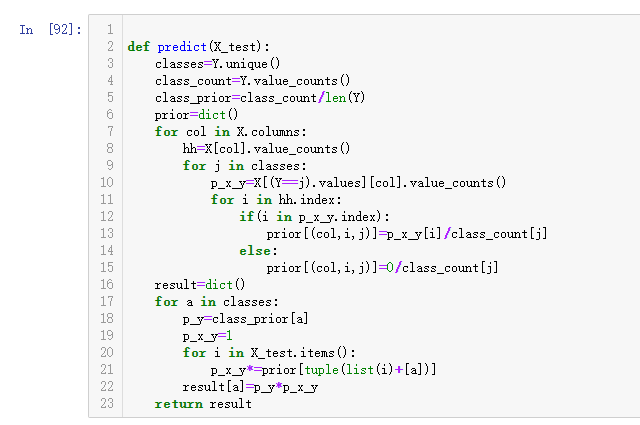
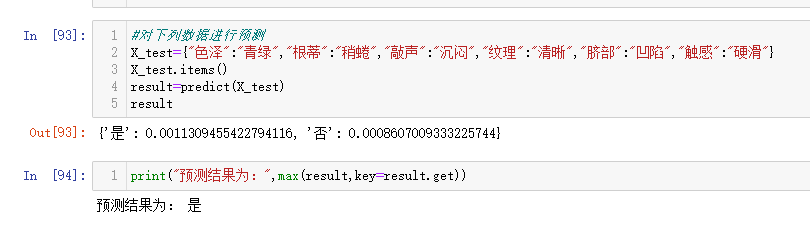
2.熟悉sklearn库中的朴素贝叶斯算法,使用sklearn包编写朴素贝叶斯算法程序,对输入数据进行预测
代码:
import numpy as np
import pandas as pd
import collections as cc
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from scipy.stats import norm
import time
class NaiveBayesClassifier:
def __init__(self,X_train,y_train,X_test,y_test):
self.X_train, self.y_train = X_train, y_train
self.X_test, self.y_test = X_test, y_test
self.class_labels = np.sort(np.unique(self.y_train))
self.class_len = len(self.class_labels)
self.n_samples, self.n_features = X_train.shape
self.prior_prob = np.zeros(self.class_len)
self.feature_names = X_train.columns
self.class_values_num = dict()
self.classified_train_data = dict()
def prior_probability(self):
print(“开始计算先验概率:”)
start_prior = time.time()
self.class_values_num = cc.Counter(self.y_train)
for i, key in zip(range(self.class_len),self.class_values_num.keys()):
self.prior_prob[i] = (self.class_values_num[key]+1)/(self.n_samples+self.class_len)
end_prior = time.time()
print(“结束计算并花费时间:%.6f”%(end_prior-start_prior))
print(“每个类别的先验概率为:”)
for c, label in enumerate(self.class_labels):
print(label,”:”,self.prior_prob[c])
def feature_probability_statistic(self):
print(“开始统计特征频率:”)
start = time.time()
for label in self.class_labels:
train_class = self.X_train[self.y_train ==label]
feature_counter = dict()
for name in self.feature_names:
feature_data = train_class.loc[:, name]
if feature_data.dtype == “object”:
feature_counter[name] = cc.Counter(feature_data)
else:
mu, sigma = norm.fit(feature_data)
feature_counter[name] = {“mu”:mu,”sigma”:sigma}
self.classified_train_data[label]=feature_counter
end =time.time()
print(“结束统计特征频率并花费时间:”, end-start)
def predict(self):
print(“开始预测测试样本:”)
start_test = time.time()
y_test_pred = [ ]
for i in range(self.X_test.shape[0]):
test_sample = self.X_test.iloc[i, :]
y_hat = [ ]
for k, label in enumerate(self.class_labels):
prob_ln = np.log(self.prior_prob[k])
label_frequency = self.classified_train_data[label]
for j in range(self.n_features):
feat_name = self.feature_names[j]
test_value = test_sample[j]
if type(test_value) == str:
n_values = len(set(self.X_train.loc[:, feat_name]))
prob_ln += np.log((label_frequency[feat_name] [test_value]+1)/(self.class_values_num[label]+n_values))
else:
mu,sigma = label_frequency[feat_name].values()
prob_ln += np.log(norm.pdf(test_value,mu,sigma)+le-7)
y_hat.append(prob_ln)
y_test_pred.append(self.class_labels[np.argmax(y_hat)])
end_test = time.time( )
print(“结束并预测测试样本并花费时间:”,end_test-start_test)
print(“-“*60)
return y_test_pred
if __name__ ==”__main__”:
#test_data=dict{“色泽”:”青绿”,”根蒂”:”稍蜷”,”敲声”:”沉闷”,”纹理”:”清晰”,”脐部”:”凹陷”,”触感”:”硬滑”,”好瓜”:”是”}
#type(test_data)
train_data = pd.read_excel(“F:/机器学习/西瓜.xlsx”)
X_train,y_train = train_data.iloc[1:-1, 1:-1],train_data.iloc[:, -1]
test_data = pd.read_excel(“F:/机器学习/西瓜.xlsx”)
X_test,y_test = test_data.iloc[:, 1:-1],test_data.iloc[:, -1]
nbc = NaiveBayesClassifier(X_train,y_train,X_test,y_test)
nbc.prior_probability()
nbc.feature_probability_statistic()
y_pred = nbc.predict()
print(classification_report(y_test,y_pred))
print(“^”*100)
aa=list(y_train)
print(“原始数据分类为:”)
print(y_pred)
print(“将原始数据进行朴素贝叶斯重新分类为:”)
print(aa)
结果:

3.查阅文献,讨论朴素贝叶斯算法的应用场景
答:朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。朴素贝叶斯主要运用于文本分类,垃圾邮件分类,信用评估,钓鱼网站检测等领域。
原文地址:http://www.cnblogs.com/bkya-bc/p/16879374.html