
转载自https://blog.csdn.net/weixin_44278406/article/details/103787143
声纹识别绪论
前言
指纹信息、人脸信息和声纹(voice-print)信息作为人体固有的生物信息,是智能电子设备私有化部署及辅助辨认个体的媒介。目前,指纹和(3D)人脸作为智能电子设备解锁信息已经成功商用,典型的如智能手机、人脸打卡系统等。声纹因为其变化性较前两者强,如感冒和外界环境声音干扰,商用化步伐不如前两者。据悉,目前声纹满足安全性级别、作为个体生物信息解锁和认证媒介的应用是在金融领域——由中国建设银行、清华大学、得意音通等起草的金融行业标准由中国人民银行正式发布并实施;该标准是我国金融行业第一个生物特征识别技术标准。除金融领域,声纹识别更多地应用于刑侦破案、罪犯跟踪、国防监听等领域。
本系列博文旨在回顾声纹发展历程,介绍声纹识别基本算法,希望为大家提供些许帮助。
声纹识别算法
声纹识别,又称说话人识别(speaker recognition),是从某段语音中识别出说话人身份的过程。与指纹类似,每个人说话过程中蕴含的语音特征和发声习惯等几乎是唯一的。与语音识别不同,语音识别是共性识别,即判定说话内容,说话人识别是个性识别,即判定说话人身份。
1. 分类
说话人识别可根据不同任务可分为两类,
- 说话人辨识(speaker identification):确定一组已知语音样本中,哪一个与输入语音样本最匹配。
- 说话人确认(speaker verification):从语音样本中确定某人是否是他所声称的那个人。
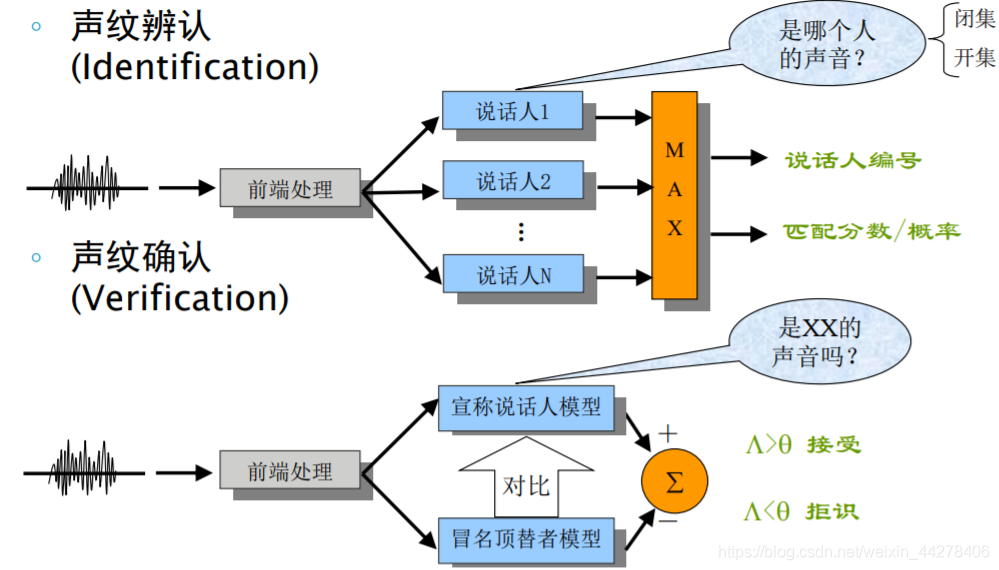
对于上述两个任务,根据说话内容语音片段(utterance)又可分为两类, - 文本相关(text dependent):语音片段只能是特定语句,如iPhone 手机的唤醒词“Hey Siri”。
- 文本无关(text independent):语音片段的内容不限。
一般来说,文本相关的说话人识别会有较高的识别率,这就是为什么许多手机厂商使用固定的唤醒词做声纹识别。
2. 性能评价标准
- 对于说话人辨识(SI)系统,其性能的评价标准主要是正确识别率及及前 N 正确率(Top N Correctness)作为评价系统性能的指标。
- 对于说话人确认(SV)系统,其最重要的两个指标是错误拒绝率(False Reject Rate,FRR)与错误接受率(False Acceptation Rate, FAR),前者是拒绝真实的说话人,又称“拒真率”,后者是接受冒认者而造成的错误,又称“认假率”,两者均与阈值的设定相关。这两种错误率很难都为零且在实际运用情况下,这两种指标是相关的,当FRR降低时,FAR就会升高,安全性就会降低;当FAR降低时,FRR就会升高,用户使用体验就会降低。两种错误率是个跷跷板,实际应用时常常在这两种情况下取一个折衷。
DET(Detection Error Trade-offs Curve)曲线能够较好的反映这两类错误率之间的关系:对声纹(一个特定的生物特征)识别系统,以FAR为横坐标轴,以FRR为纵坐标轴,通过调整其参数得到的FAR与FRR之间关系的曲线图,就是DET曲线。显然DET曲线离原点越近,系统性能越好。在当前的技术不能使得两类错误率同时降为最低的情况下,我们根据具体应用的需要,调节阈值使得两类错误率可以满足实际应用需求。通常,研究者常用等错误率(Equal Error Rate,简称EER)来描述总体性能,等错误率就是在DET曲线上两类错误率相等时所对应的错误率取值,是衡量系统性能的重要参数。DET曲线与EER的取值如下图所例示。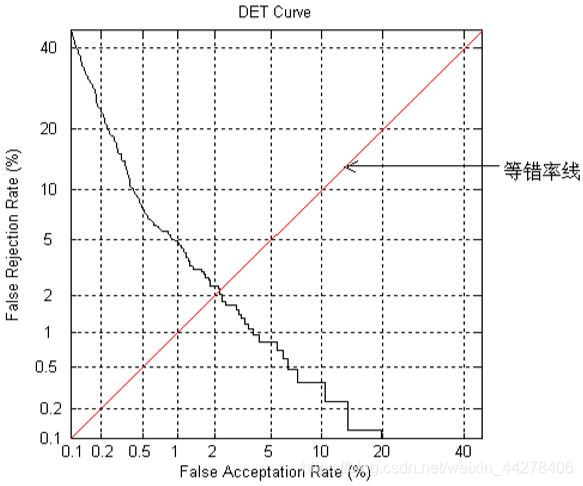
DET曲线来源于如下过程,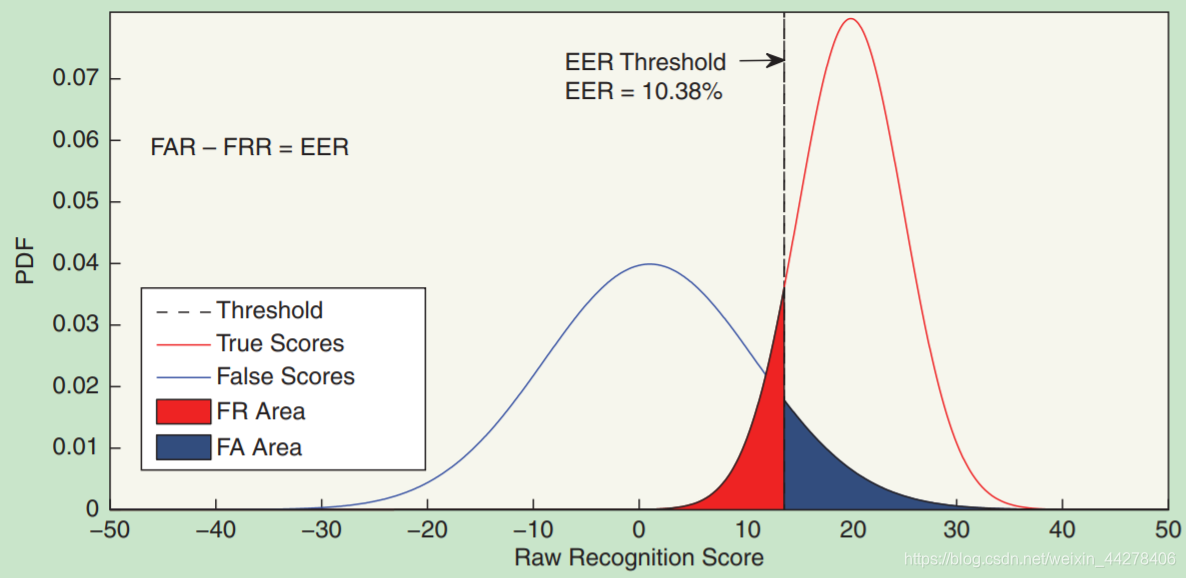
不同的阈值对应不同的FAR和FRR,实际上要做的事情是根据实际应用场景设定合适的阈值。
3. 说话人识别特征
说话人识别(或确认)经历的特征描述方式是与算法息息相关的,如i-vector代表着i-vector/PLDA算法体系下的特征,d-vector,x-vector代表着深度神经网络算法体系下的特征。
- 帧级别(Frame-level):一般情况下采用语音识别中的MFCCs(Mel Frequency Cepstral Coefficient) 特征或者其他特征。
- 语音片段级别(Utterance/speaker-level): 由于我们需要直接判定语音片段,需要片段级别的特征,如GMM supervectors,i-vectors,DNN embeddings(d-vectors,x-vectors)
4. 算法归纳
| 类型 | 主要算法 |
|---|---|
| 文本无关 | GMM-UBM (D.A. Reynolds, 2000) GMM-SVM (W.M. Campbell, 2006) JFA(联合因子分析, P. Kenny, 2007) i-vector/PLDA (N. Dehak, 2011) DNN i-vector (Y. Lei, 2014) Deep Embedding (2017) x-vectors (Snyder et al, 2018) GE2E(2017-2019) |
| 文本相关 | GMM-UBM HMM-UBM TMM-UBM (TMM – Tied Mixture Model) i-vector DNN-ivector |
表格中展现的说话人识别算法包含传统的统计学习方法和深度学习算法,后续篇幅中着重介绍GMM-UBM,i-vector/PLDA和GE2E,因为这三个算法分别代表着统计学分类,声道和信道抽象建模及DNN embedding。
Reference
- The University of Edinburgh, Automatic Speech Recognition(ASR)2018-19: Lectures 17
- 洪青阳,智能语音技术机器应用(2018春季)- 声纹识别
- J Hansen and T Hasan (2015), Speaker Recognition by Machines and Humans: A tutorial review, IEEE Signal Processing Magazine, 32(6): 74-99.
- 郑方,李蓝天等,声纹识别技术及其应用现状
- Roger Jang (張智星),Audio Signal Processing and Recognition (音訊處理與辨識)-Speaker Recognition
原文地址:http://www.cnblogs.com/wcxia1985/p/16881316.html