
WordCount实例操作
本地执行wordcount操作
1、启动IDEA,在idea搭建maven项目
配置hadoop基本依赖,导入hadoop需要的一些包
pom.xml的文件配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hadoop</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<!--配置hadoop的依赖-->
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
<!-- 配置测试的依赖-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.1</version>
</dependency>
</dependencies>
</project>
2、书写MapReduce的代码
MapReduce实现分为三个阶段
-
Mapper阶段
-
Reduce阶段
-
Drive阶段
编写一个MapReduce程序,通常都需要分三步:
- 1、编写Mapper
- 2、编写Reducer
- 3、编写Driver
Mapper模块的书写
自定义Mapper的java文件名称,我的文件名称是WordCountMap
package MapReduce.wordcount;
/*
* 插件类型的开发套路:
* 1、继承类或者实现接口
* 2、实现或者重写相关的方法
* 3、提交执行
*
* 自定义Mapper的开发:
* 继承hadoop提供的Mapper类,提供输入和输出的KV的类型并重写map方法
*
*/
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMap extends Mapper<LongWritable, Text,Text, IntWritable> {
/*
* map方法是整个MapReduce中map阶段的和核心处理方法
* @param key 表示偏移量
* @param value 读取到一行的数据
* @param context 上下文对象,用于调度整个Mapper类中的方法的执行
* */
// 定义输出的k
private Text outk=new Text();
// 定义输出的v
private IntWritable outv=new IntWritable(1);
@Override
protected void map(LongWritable key,Text value, Context context) throws IOException, InterruptedException {
// 1、将读取到的一行数据从Text转到String(方便操作)
// 例如 :aaa,aaa
String line=value.toString();
//2、按照分隔符分割当前的数据
// 例如 [aaa,aaa]
String[] words=line.split(" ");
//3、将words进行迭代处理,吧迭代的每一个单词拼成kv写出
for (String word:words){
// 封装输出的k
outk.set(word);
//写出
context.write(outk,outv);
// aaa 1 两个kv
// aaa 1
}
}
}
Mapper的源码解析
Mapper 类的解析
- 2.1 setup(): 在MapTask开始执行前调用一次。Called once at the begining of the task
protected void setup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
// 每次启动Mapper的时候执行一次,每次输入的是
/*
* Mapper类的四个泛类(以word‘count来分析)
* KYEIN : 输入数据的key的类型 LongWriter,用于表示偏移量(从文件的哪个位置读取数据)
* VALUEIN : 输入数据的value类型 Text,从文件中读取的一行数据
* KEYOUT : 输出数据的key的类型 Text,表示一个单词
* VALUEOUT : 输出数据的value的类型 IntWritable,表示这个单词出现了一次
*/
- 2.2 map(): 输入数据的每个kv都需要执行一次map方法。Called once for each key/value pair in the input split
protected void map(KEYIN key, VALUEIN value, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
context.write(key, value);
}
//对于每一个数据都会通过指定的方式进行切割,我使用的是"空格",将处理后的数据形成kv键值对的形式进行存储。输入数据和输出数据的格式keyin,values,keyout,values,是setup的指定的类型
/*比如aaa,aaa,bbb 的数据 通过一次map()方法后,就会形成kv键值对
* k v
* aaa 1
* aaa 1
* bbb 1
*/
- 2.3 cleanup(): 在MapTask结束调用一次,Called once at the end of the task
protected void cleanup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
/*
* 输入数据和输出数据的格式需要指定,当然在开始阶段(setup指定的类型)
* 在整个MapTask任务结束后,会执行cleanup,类似于清理所有的数据或者给一个确定所有数据处理完成的信号
*/
- 2.4 run():
public void run(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
this.setup(context);
//执行一次setup方法
try {
while(context.nextKeyValue()) {
//判断是否还有下个kv,如果没有kv数据,就会执行cleanup操作,进入下一个阶段;如果存在kv数据,则继续执行map()操作,直到所有的kv操作都结束,会将所有处理后的数据丢给reduce模块进行处理
this.map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
this.cleanup(context); //执行一次cleanup方法
}
}
Reducer模块的书写
自定义Mapper的java文件名称,我的文件名称是WordCountReducer
package MapReduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/*
* 基于Reducer类需要继承Haoop中华的Reducer类,指定四个泛型,重写Reducer方法
*
* 4、四个泛型
* KEYIN:输入的数据key的类型,Text对应Mapper输出的key的剋行,表示一个单词
* VALUEIN:输入数据的value类型,IntWriter对应Mapper输出的value的类型,表示单词出现的次数
*
* KEYOUT:输出数据的key类型 ,Text 表示一个单词
* VALUEOUT:输出数据的value的类型 IntWriter 表示某个单词出现的总次数
* */
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
//定义输出的v
private IntWritable outv=new IntWritable();
/*
多个相同的key的kv对,会组成一组数据,一组相同kv对会执行一次reduce方法
* reducer方法是MapReducer的reduce阶段的核心处理过程
* @param key 输入数据key,表示一个单词
* param values 当前key对应的所有value
* param context 负责调度整个Reduce中的方法执行
* @throws IOExpection
* @throws InterruptedExpcetion
* */
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 1、迭代values,去除每隔value,进行汇总
int sum=0;
for(IntWritable value:values){
sum+=value.get();
}
// 2、封装value
outv.set(sum);
// 3、写出
context.write(key,outv);
}
}
Reducer的源码解析
Reducer 类的解析
- 1.1 setup() : 在ReducerTask开始执行前调用一次。Called once at the start of the task。
protected void setup(Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
/*
* KEYIN:输入的数据key的类型,Text对应Mapper输出的key的剋行,表示一个单词
* VALUEIN:输入数据的value类型,IntWriter对应Mapper输出的value的类型,表示单词出现的次数
*
* KEYOUT:输出数据的key类型 ,Text 表示一个单词
* VALUEOUT:输出数据的value的类型 IntWriter 表示某个单词出现的总次数
*/
- 1.2 reduce(): 每一个key汇总都需要执行一次reduce方法,相同对的kv对
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
Iterator i$ = values.iterator();
while(i$.hasNext()) {
VALUEIN value = i$.next();
// 会一直读取数据,如果一直存在kv就持续写入,没有kv数据则结束操作
context.write(key, value);
}
// 这是的keyin、values、keyout、values来自setup方法里面的数据格式
- 1.3 cleanup():在ReducerTask结束前调用一次。Called once at the end od task
protected void cleanup(Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
// 当ReduceTask任务结束的时候,会进行调用。和MapTask方法中的cleanup方法一样
- 1.4 run() 执行一次map方法
public void run(Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
this.setup(context);
try {
while(context.nextKey()) {
// 判断是否有下一个key,如果有kv数据,继续执行reduce()方法,否则,执行cleanup()方法
this.reduce(context.getCurrentKey(), context.getValues(), context); //执行reduce方法
Iterator<VALUEIN> iter = context.getValues().iterator();
if (iter instanceof ValueIterator) {
((ValueIterator)iter).resetBackupStore();
}
}
} finally {
this.cleanup(context); //执行clearnup方法
}
}
Driver模块的书写
自定义Mapper的java文件名称,我的文件名称是WordCountDriver
package MapReduce.wordcount;
/*
* 驱动类, 主要将我们写好的MapReduce 封装成为一个job对象,进行提交,然后执行
* */
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1、创建配置对象
Configuration conf=new Configuration();
// 2、创建Job对象
Job job=Job.getInstance(conf);
// 3、关联驱动类
job.setJarByClass(WordCountDriver.class);
// 4、关联Mapper 和Reducer 的类型
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReducer.class);
// 5 设置mapper输入的key和value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 6、设置Reducer 最总输出的key和value的值
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 7、设置输入和输出路径
// 如果是本地的话就要手动指定inputPath的路径而且这个路径存在
FileInputFormat.setInputPaths(job,new Path(args[0]));
// "C:\\Users\\xxx\\Desktop\\input"
// output的路径也需要指定,但是这个这个文件output是不存在的,是执行MapReduce程序生成的
FileOutputFormat.setOutputPath(job,new Path(args[1]));
// "C:\\Users\\xxx\\Desktop\\output"
// 8、提交Job
job.waitForCompletion(true);
}
}
注意!!!
如果执行出现了这个问题
org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
说明没有导入hadoop.dll文件,将和hadoop版本一致的hadoop.dll放在hadoop文件路径的bin目录下即可
本地写的MapReduce放在集群执行
1、修改代码
修改关联驱动类和设置参数(上述的代码,路径采用的是本地放在集群中运行的方式)
// 3、关联驱动类
job.setJarByClass(WordCountDriver.class);
换为
job.setJar(jar包的路径) // 刚刚导入的jar包的路径 在target文件目录中可以找到
// 在配置conf的时候需要指定用户和一些配置
Configuration conf=new Configuration();
// 设置namenode的地址
conf.set("fs.defaultFS","hdfs://hadoop:9000");
//指定mapreduce运行在yarn上
conf.set("mapreduce.framework.name","yarn");
// 指定mapreduce可以在远程集群运行
conf.set("mapreduce.app-submission.cross-platform","true");
// 指定yarn resourcemanager的位置
conf.set("yarn.resourcemanager.hostname","hadoop2");
2、打包
将MapReduce程序打成jar包,将jar包上传到集群中,通过hadoop jar来运行。IDEA的maven工程自带package打包成jar包的功能。
3、指定上传的参数
指定用户,以及两个文件的参数。如图
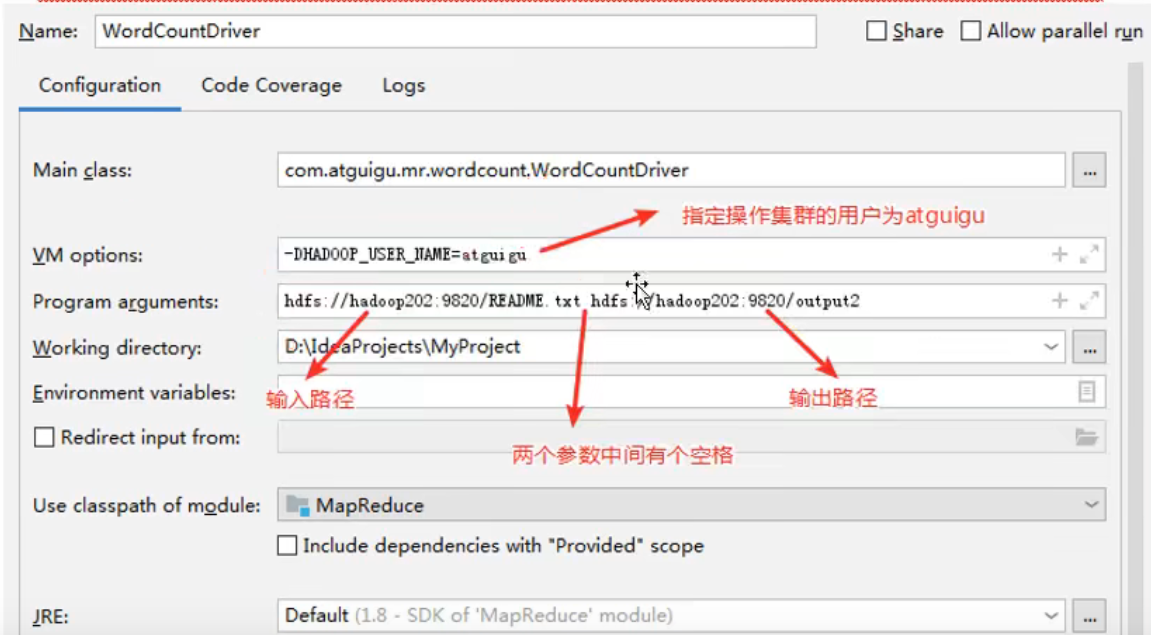
在Linux运行手写的jar包
1、将生成的jar包放在Linux中
将上述的本地写的MapReduce的打包的jar包,传入Linux中。
xshell可以直接输入 rz 进行上传文件(前提是已经安装好 lrzsz 软件包),将打好的jar包放在Linux的指定位置
2、执行MapReduce程序
在hadoop路径下执行代码即可
# 格式 hadoop jar 刚刚上传jar的路径 主程序的全类名(我的主程序是WordCountDriver) /输入数据路径 /输出数据路径
# 注意输出数据路径之前不能有
hadoop jar jar包路径 MapReduce.wordcount.WordCountDriver /input /output
3、在hadoop文件系统(网页端)中查看
可以查看到/output这个目录,在output目录中part-r-00000文件,即是处理后的内容
原文地址:http://www.cnblogs.com/zt123456/p/16881814.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性