
归一化层
1. 内部协变量偏移(Internal Covariate Shift)
- 深层神经网络中,由于前输出为后节点输入,使用梯度下降更新参数进而改变 前一层输出,会导致后续的 输入分布 在每层之间发生较大的变化。
- 这种现象称为 内部协变量偏移(Internal Covariate Shift)。越深的层,其偏移的越明显。
- 简单理解可以为“高层大厦底部发生了微小偏移,楼层越高,偏移越严重”。
2. 解决问题的方法
- 本质:使得每一层的输入分布在 训练过程 保持一致。
2.1 批量归一化(Batch Normalization,BN)
- 某层的计算公式,表示为第 \(l\) 层的净输入为 \(z^{(l)}\),神经元的输出为 \(a^{(l)}\) ,其中 \(z^{(l)}=Wa^{(l-1)}+b\) 。
\[a^{(l)}=f(z^{(l)})=f(Wa^{(l-1)}+b) \]
- 要解决内部协变量偏移问题,需要使 \(z^{(l)}\) 的分布一致。一般使用标准归一化,将净输入 \(z^{(l)}\) 的每一维都归一到标准正态分布。
\[\bar{z}^{\left( l \right)}=\frac{z^{\left( l \right)}-E\left( z^{\left( l \right)} \right)}{\sqrt{var\left( z^{\left( l \right)}+\varepsilon \right)}} \]
- 那么均值期望和方差哪里来?
按批次或者样本数量去求。给定一个包含 \(K\) 个样本的小批量样本集合,第 \(l\) 层神经元的净输入 的均值和方差为:
\[u_{\left( l \right)}=\frac{1}{K}\sum_{k=1}^K{z^{\left( k,l \right)}} \]
\[\sigma _{\left( l \right)}^{2}=\frac{1}{K}\sum_{k=1}^K{\left( z^{\left( k,l \right)}-\mu _{\left( l \right)} \right) \odot \left( z^{\left( k,l \right)}-\mu _{\left( l \right)} \right)} \]
- 对净输入的标准归一化会使得其取值集中在0附近,如果使用sigmoid型函数时,这个取值区间刚好接近线性变换区间,减弱了神经网络的非线性性质,因此,为了使得归一化不对网络的表示能力造成负面影响,我们可以通过一个附加的缩放和平移变换改变取值区间。
\[\bar{z}^{\left( l \right)}=\frac{z^{\left( l \right)}-\mu _{\left( l \right)}}{\sqrt{\sigma _{\left( l \right)}^{2}+\varepsilon}}\odot \gamma +\beta \Rightarrow BN_{r,\beta}\left( z^{\left( l \right)} \right) \]
- 其中\(\gamma\)和\(\beta\)分别代表缩放和平移的参数向量,当\(\gamma =\sqrt{\sigma _{\left( l \right)}^{2}}\), \(\beta =\mu _{\left( l \right)}\)时, \(\bar{z}^{\left( l \right)}=z^{\left( l \right)}\)。
- 批量归一化可以看作是一个特殊的神经层,加在每一层非线性激活函数之前,即
\[a^{\left( l \right)}=f\left( BN_{\gamma ,\beta}\left( z^{\left( l \right)} \right) \right) =f\left( BN_{\gamma ,\beta}\left( Wa^{\left( l-1 \right)} \right) \right) \]
2.1.1 BN 的优势
- 解决“internal covariate shift”的问题。
- \(\gamma\) 和 \(\beta\) 的作用:
- γ 和 β 作为调整参数,既可以统一分布,同时也可以保持原输入,提升模型的容纳能力(capacity)。
- 如果是 sigmoid 函数,BN后的分布在0-1之间,在接近0的地方趋于线性,通过 γ 和 β 可以自动调整输入分布,使得其非线性能力不至于减弱。
- 如果为 ReLU 函数,意味着将有一半的激活函数无法使用,那么通过 β 可以进行调整参与激活的数据的比例,防止 dead-Relu 问题。
- 可以控制数据的分布范围,避免了梯度消失和爆炸。
- 降低权重初始化的困难。
- BN 可以起到和 dropout 一样的正则化效果,一般全连接层用dropout,卷积层用 BN。
2.2 层归一化(Layer Normalization,LN)
- LN的思路和BN相似,只不过归一化的整体选取不同。
- F为特征轴,N为样本轴,C为通道轴,左为LN, 右为BN。
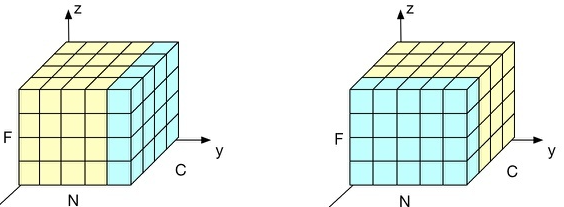
- 看出 BN 是 N 和 F 上归一化,LN 是 C 和 F 上归一化。
- 如果结合到时间序列预测 [N, C, F] 对应 [batch_size, seq_len, hidden_dim],即总时间步长上进行归一化。
- 何时要用 LN?
BN 是按照样本数计算归一化统计量。- 所以当样本数很少时,其均值和方差便不能反映全局的统计分布息,效果会变得很差。
- 在一些场景中,比如说硬件资源受限,在线学习等场景,BN是非常不适用的。
- 其次像 RNN 这种类型的网络,每个bacth的样本长度可能不一样长度,所以 BN 再次不能代表全体,转换到每层去处理的 LN 更合理一些。
2.3 其他归一化(IN/GN)比较
- 这里的 W*H 就是之前的 F 轴。
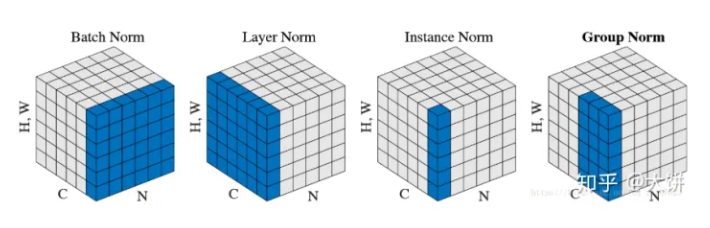
- 其实思路都一样,只不过是归一化的部分不同。
- 四种归一化比较:
- BN:batch方向做归一化,计算NHW的
- FN:channel方向做归一化,计算CHW的
- InstanceNorm:一个channel内做归一化,计算H*W的
- GroupNorm:先将channel方向分group,然后每个group内做归一化,计算(C//G)HW的
- GN 与 LN 和 IN 有关,LN 和 IN 在 RNN 系列 或 GAN 模型方面特别成功。
原文地址:http://www.cnblogs.com/sdlwh/p/16793746.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性