
Kubernetes网络组件之Calico策略实践(BGP、RR、IPIP)
原创
mb60ffb84ea57052021-07-27 16:29:41博主文章分类:k8s-docker©著作权
文章标签Kubernetes文章分类其它其它阅读数583
Pod 1 访问 Pod 2大致流程如下:
数据包从容器1出到达Veth Pair另一端(宿主机上,以cali前缀开头);
宿主机根据路由规则,将数据包转发给下一跳(网关);
到达Node2,根据路由规则将数据包转发给cali设备,从而到达容器2。
其中,这里最核心的“下一跳”路由规则,就是由 Calico 的 Felix 进程负责维护的。这些路由规则信息,则是通过 BGP Client 也就是 BIRD 组件,使用 BGP 协议传输而来的。
不难发现,Calico 项目实际上将集群里的所有节点,都当作是边界路由器来处理,它们一起组成了一个全连通的网络,互相之间通过 BGP 协议交换路由规则。这些节点,我们称为 BGP Peer。
而host-gw和calico的唯一不一样的地方就是当数据包下一跳到达node2节点的容器的时候发生变化了,并且出数据包也发生变化了,我们知道它是从veth的设备对让容器里面的数据包到达宿主机上数据包,这个数据包到达node2之后,它又根据一个特殊的路由规则,这个会记录目的通信地址的cni网络,然后通过cali的设备进去容器,这个就跟网线一样,数据包通过这个网线发到容器中,这也是一个二层的网络互通才能实现,如果二层不通的就可以使用IPIP模式了,
calico没有网桥数据包是怎么出去的?
pod1的数据包从veth的设备对到到宿主机的一段eth0上,之前的数据包其实是走的默认宿主机的网关将流量转发到calico的cali的设备上的,通过路由表信息下一跳地址到宿主机然后转发到对应的容器中
6、Route Reflector 模式(RR)(路由反射)
https://docs.projectcalico.org/master/networking/bgp
Calico 维护的网络在默认是(Node-to-Node Mesh)全互联模式,Calico集群中的节点之间都会相互建立连接,用于路由交换。但是随着集群规模的扩大,mesh模式将形成一个巨大服务网格,连接数成倍增加。
这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。
确定一个或多个Calico节点充当路由反射器,让其他节点从这个RR节点获取路由信息。
在BGP中可以通过calicoctl node status看到启动是node-to-node mesh网格的形式,这种形式是一个全互联的模式,默认的BGP在k8s的每个节点担任了一个BGP的一个喇叭,一直吆喝着扩散到其他节点,随着集群节点的数量的增加,那么上百台节点就要构建上百台链接,就是全互联的方式,都要来回建立连接来保证网络的互通性,那么增加一个节点就要成倍的增加这种链接保证网络的互通性,这样的话就会使用大量的网络消耗,所以这时就需要使用Route reflector,也就是找几个大的节点,让他们去这个大的节点建立连接,也叫RR,也就是公司的员工没有微信群的时候,找每个人沟通都很麻烦,那么建个群,里面的人都能收到,所以要找节点或着多个节点充当路由反射器,建议至少是2到3个,一个做备用,一个在维护的时候不影响其他的使用。
具体步骤如下:
1、关闭 node-to-node BGP网格
添加 default BGP配置,调整 nodeToNodeMeshEnabled和asNumber:
直接应用一下,当我们禁用node-to-node mesh的时候,网络立马就会断,所以断的话要提前做好影响的范围,也就是切换这个网络是需要断网的,使用node-to-node BGP这种也是建议100个节点以下,当超过100台节点一定要使用路由反射RR模式
查看bgp网络配置情况,false为关闭
去查看pod的网络测试已经断开了,这里是因为我们使用caclico的配置禁用了node-to-node mesh了
ASN号可以通过获取 # calicoctl get nodes –output=wide
这里有个编号,ASN64300,一个编号就是一个自治系统
2、配置指定节点充当路由反射器
为方便让BGPPeer轻松选择节点,通过标签选择器匹配,也就是可以去调用k8s里面的标签进行关联,我们可以给哪个节点作为路由发射器打个标签
给路由器反射器节点打标签,我这将node1打上标签[root@k8s-master1 calico]# kubectl label node k8s-node1 route-reflector=true
查看node BJP的节点状态,因为禁用了网格,所以这里都关闭了,所以也就不通了。
然后配置路由器反射器节点routeReflectorClusterID,增加一个集群节点的ID
下面的可以通过-o yaml输出出来
应用一下[root@k8s-master1 calico]# calicoctl apply -f node.yaml
现在,很容易使用标签选择器将路由反射器节点与其他非路由反射器节点配置为对等:现在也就是将其他的节点去连接这个k8s-node1打标签的路由发射器
#就是带route-reflector的都去连接匹配这个,刚才我们不是打上标签了嘛,所以需要我们去连接这个路由反射器
查看节点的BGP规则与连接状态,这样的话就显示一个路由反射器的节点
查看容器网络联通性
添加多个路由反射器
现在进行对路由反射器添加多个,100个节点以内建议2-3个路由反射器
1)进行对集群节点打标签
2)对k8s-node2添加然后配置路由器反射器节点
[root@k8s-master1 calico]# calicoctl get node k8s-node2 -o yaml
3)查看节点状态
4)测试网络连通性
所以这是使用路由反射器来解决节点增多BGP带来的消耗
7、IPIP模式
ipip模式与flannel的vxlan模式类似,这个也是对数据包的一个封装
在前面提到过,Flannel host-gw 模式最主要的限制,就是要求集群宿主机之间是二层连通的。而这个限制对于 Calico 来说,也同样存在,也是不能跨vlan的,主要局限就是数据包主要封装的是容器,源IP和目的IP,因为它们工作都是使用的二层,所以二层它不会考虑容器之间进行数据包转发的,但如果添加路由表,将目的的IP通过静态路由的方式也能实现,不同vlan的数据的通信,不过这种方式目前没有测试。
另外还有一个弊端,会发现calico的路由表比flannel的多一些,因为它里面还要加一些传入过来的到设备的路由表信息,就是每个pod都加一个路由表,所以它的路由表的量也比flannel大不少。
修改为IPIP模式:
创建好之后查看详细信息,已经开启ippool
查看网络设备会增加一个tunl0,增加了一个隧道的网卡
IPIP示意图: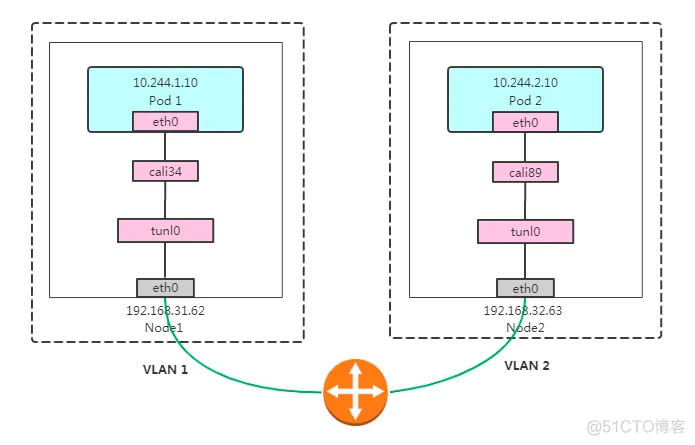
那么有这么一个需求,有两个不同vlan,因为需要突破2层,现在有两个vlan,这两个vlan它本身是三层可达的,三层可达就必须要借助路由器,也就是这两个节点,部署k8s集群可能是两个vlan里面的,但是它们网络是通的,你也可以组建成一个集群,但是要使用calico的BGP,如果只让它们三层可达的话,与BJP也是不可以用的,因为BJP使用的二层,因为数据源IP和目的IP都是pod的IP,而这个路由器并不知道这个源IP和目的IP应该发给谁,因为这没有写这个路由表信息,如果写了,理论上来讲节点不同网段也是可以通信的,那么不添加这个路由表的话,这个BGP是过不去的,那么这种情况下就得去启用ipip模式了,IPIP是linux内核的驱动程序,可以对数据包进行隧道,那么它看到两个不同的网络vlan1和vlan2,启动ipip模式也有个前提,它是属于4层的,因为它是基于现有的以太网的网络将你原来包里的原始IP,也是进行一次封装,因为现有的网络已经通了,三层的路由现实不同的vlan进行通信,所以通过tunl0解包,这个tunl0类似于ipip模块,这个就跟vxlan的veth类似,所以这个模式跟vxlan的模式大致是一样的
Pod 1 访问 Pod 2大致流程如下:
数据包从容器1出到达Veth Pair另一端(宿主机上,以cali前缀开头);
进入IP隧道设备(tunl0),由Linux内核IPIP驱动封装在宿主机网络的IP包中(新的IP包目的地之是原IP包的下一跳地址,即192.168.31.63),这样,就成了Node1 到Node2的数据包;
那么这个IPIP本身和vxlan一样,工作在三层的,因为它用现在的以太网进行传输的,现在物理机传输的,路由器这个方面达到另一个vlan2,这个网络之间肯定是可以访问的,那么IPIP之间就能和三层的路由到目的另一个vlan中
数据包经过路由器三层转发到Node2;
Node2收到数据包后,网络协议栈会使用IPIP驱动进行解包,从中拿到原始IP包;
然后根据路由规则,根据路由规则将数据包转发给cali设备,从而到达容器2。
路由表:
不难看到,当 Calico 使用 IPIP 模式的时候,集群的网络性能会因为额外的封包和解包工作而下降。所以建议你将所有宿主机节点放在一个子网里,避免使用 IPIP。
8、CNI 网络方案优缺点及最终选择
先考虑几个问题:
需要细粒度网络访问控制?这个flannel是不支持的,calico支持,所以做多租户网络方面的控制ACL,那么要选择calico
追求网络性能?这两个方案无疑是flannel和calico的路由方案是最高的,也就是flannel的host-gw和calico的BGP。
服务器之前是否可以跑BGP协议?很多的公有云是不支持跑BGP协议的,那么使用calico的BGP模式自然是不行的。
集群规模多大?如果规模不大,100节点以下维护起来比较方面之间可以使用flannel就可以
是否有维护能力?calico的路由表很多,而且走BGP协议,一旦出现问题排查起来也比较困难,上百台的,路由表去排查也是很麻烦,这个具体的需求也是跟自己饿的情况而定。
小话题:办公网络与k8s网络如何互通
现在架构也是微服务也比较流行,测试环境是在k8s集群中,开发人员是在办公网络中,网络显然是不同的,微服务是使用pod去通信的,办公网络访问pod自然是不同的,那么就需要将这个网络打通。
比如开发开发了一个微服务,不想启动整套,注册中心,服务发现了等等,但是它只想跑一个模块,直接调用测试环境中注册中心数据库了直接去用,那么就要考虑将这个网络打通了
比如一块是办公网络,然后开发人家使用的开发电脑,另一块是k8s集群跑着很多的微服务,那么pod的ip是10.244.0.0/16这个网段,那么service是10.0.0.10/24,宿主机是172.17.0.0/24,那么办公网络是192.168.1.0/24
那么办公网络去访问pod的IP肯定是不通的,除非做了路由,即使办公网络和k8s的宿主机网络能通,但是也需要做一些特殊的转发策略,现在解决的问题是办公网络可以访问pod的IP,访问service的IP,也就是让k8s内部的网络暴露出来,办公网络就像之间访问虚拟机一样去访问,所以去解决这个问题,分为两种情况。
第一种情况,k8s集群测试环境在办公网络的子网里面,那么这个实现就比较简单了,只需要在子网中上层的路由器添加一个规则就行了,ip route add,目的IP为10.244.0.0/16,到达的下一跳via为其中的k8s节点,比如k8s-node1 dev 接口A
ip route add 10.244.0.0/16 via <k8s-node1> dev A
添加这么一个规则,办公网络就能直接访问k8s的节点,直接就能访问pod IP,也就是下一跳地址之后,就能直接访问都podIP了。
第二种情况,k8s集群与办公网络在不同VLAN中,不同机房
前提是k8s集群与办公网络是互通的,三层可达
有两种方案1)在路由器上添加路由表,10.244.0.0/16 <k8s-node1>
2) 采用BGP,如果三层的路由支持BGP协议的话,直接就可以让路由器BGP与路由反射器BGP建立连接,这样的话路由器上的BGP就能获取到了k8s上的路由表信息了,然后经过下一跳来转发到目的的node的pod中。
总结:只要是不同vlan,必须是三层可达,能在上层的路由器上,访问集群的网段,pod网段还是service网段,一定要告知它,帮它转发到下一跳是谁,下一跳如果是目的的节点,那就直接转发数据包。
4.5 网络策略
1、为什么需要网络隔离?
CNI插件插件解决了不同Node节点Pod互通问题,从而形成一个扁平化网络,默认情况下,Kubernetes 网络允许所有 Pod 到 Pod 的流量,也就是在k8s网络中都是相互ping通,都是可以访问传输数据包的,在一些场景中,我们不希望Pod之间默认相互访问,例如:
应用程序间的访问控制。例如微服务A允许访问微服务B,微服务C不能访问微服务A
开发环境命名空间不能访问测试环境命名空间Pod
当Pod暴露到外部时,需要做Pod白名单
多租户网络环境隔离
比如这个命名空间与其他的命名空间进行互通,将你的pod暴露在外面了暴露在办公网络中了,为了方便,但是提高一些安全性,那么谁能访问,谁不能访问,直接做白名单也可以,然后微服务部署的也比较多,也希望做一些隔离,那么也可以使用网络隔离,那么就可以使用network policy进行pod网络的隔离。
既然说到了网络的限制也就是ACP访问控制,自然是有两个方向,一个是入口方向,一个是出口方向
一个用户去访问虚拟机,客户端访问这是入方向,对于客户端来说这是出方向,虚拟机访问外网自然是出方向,做ACL一个是入方向,一个是出方向,我们针对pod做谁能访问pod,pod能访问谁。
所以,我们需要使用network policy对Pod网络进行隔离。支持对Pod级别和Namespace级别网络访问控制。
Pod网络入口方向隔离
基于Pod级网络隔离:只允许特定对象访问Pod(使用标签定义),允许白名单上的IP地址或者IP段访问Pod
基于Namespace级网络隔离:多个命名空间,A和B命名空间Pod完全隔离。
Pod网络出口方向隔离
拒绝某个Namespace上所有Pod访问外部
基于目的IP的网络隔离:只允许Pod访问白名单上的IP地址或者IP段
基于目标端口的网络隔离:只允许Pod访问白名单上的端口
2、网络策略概述
一个NetworkPolicy例子:
配置解析:
podSelector:用于选择策略应用到的Pod组,也就是对哪个pod进行网络隔离
policyTypes:其可以包括任一Ingress,Egress或两者。该policyTypes字段指示给定的策略用于Pod的入站流量、还是出站流量,或者两者都应用。如果未指定任何值,则默认值为Ingress,如果网络策略有出口规则,则设置egress,这个也就是入口方向和出口方向,限制入口或者限制出口方向
Ingress:from是可以访问的白名单,可以来自于IP段、命名空间、Pod标签等,ports是可以访问的端口。入口的策略是什么,入口的策略是这么限制的,
Egress:这个Pod组可以访问外部的IP段和端口。出的策略是这么限制的,pod出去是这么限制的,是访问百度的ip,还是访问其他的ip,是哪个ip段还是哪个命名空间。
在172.17.0.0/16这个大子网里面除了这个172.17.1.0/24这个不能访问,其他的都能访问,命名空间也是可以哪个可以访问,哪个不可以访问。
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
pod还能定义你可以访问我哪个端口,这是出口策略的定义,就是出去可以访问谁,访问哪个ip段的端口
ports:- protocol: TCP
port: 6379
- protocol: TCP
根据上面的yaml的规则来说,结构是这样的,对pod命名空间的携带标签role:db的pod进行网络隔离,只有172.17.0.0/16子网下除了172.17.1.0/24其他的都可以访问我,
- namespaceSelector:
matchLabels:
project: myproject- podSelector:
matchLabels:
role: frontend
这个命名空间可以访问我,携带role:frontend的也可以访问我,这些只能访问我6379的端口,本身自己只能访问10.0.0.0/24IP段的ip的5978端口。
3、入站、出站网络流量访问控制案例
现在做对pod的访问限制
Pod访问限制
准备测试环境,一个web pod,两个client pod需求:将default命名空间携带run=nginx标签的Pod隔离,只允许default命名空间携带run=client1标签的Pod访问80端口
- podSelector:
隔离策略配置:
Pod对象:default命名空间携带run=nginx标签的Pod
允许访问端口:80
允许访问对象:default命名空间携带run=client1标签的Pod
拒绝访问对象:除允许访问对象外的所有对象
测试查看现在client的网络是不能通信的,而这个组件calico支持,像其他的flannel组件是不支持的
命名空间隔离
需求:default命名空间下所有pod可以互相访问,但不能访问其他命名空间Pod,其他命名空间也不能访问default命名空间Pod。
[root@k8s-master1 ~]# kubectl run client3 --generator=run-pod/v1 --image=busybox -n kube-system --command -- sleep 36000
default的pod都能互通,kube-system的pod不能与default的pod互通,default也不能访问kube-system的pod,也就是自己隔离到了自己网络命名空间下了
现在我们实现一下这个需求,创建好之后因为我们没有限制网络的隔离,所以默认情况下不同命名空间的网络也是互通的
创建一个default下的pod名字为nginx的pod
创建网络隔离yaml,实现default和kube-system下的pod不能互通
测试之后现在已经无法访问default下的pod了,这也就实现的网络隔离,相反反过来也不通
podSelector: {}:default命名空间下所有Pod
from.podSelector: {} : 如果未配置具体的规则,默认不允许
参考
https://blog.51cto.com/u_14143894/2463392
原文地址:http://www.cnblogs.com/gaoyuechen/p/16889157.html