
socket粘包现象
粘包现象(TCP模式才会出现)
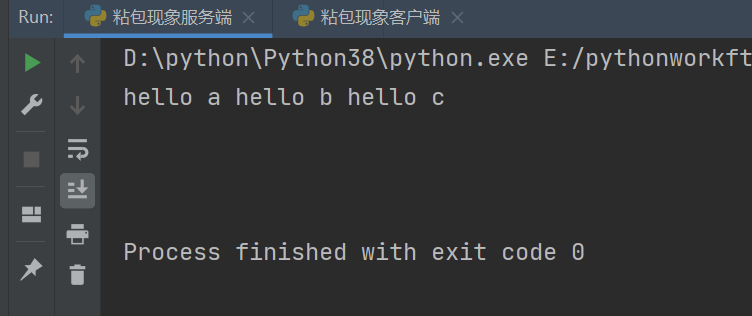
1.服务端连续执行三次recv
2.客户端连续执行三错send
问题:服务端一次性接收到了客户端三次的消息 该现象称为"粘包现象"
# 服务端
import socket
# tcp模式
server = socket.socket()
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # IP端口复用
server.bind(('127.0.0.1', 8889)) # 绑定IP与端口
server.listen(5) # 半连接,缓冲池
conn, addr = server.accept()
res1 = conn.recv(1024) # 接收消息
print(res1.decode('utf8'))
res1 = conn.recv(1024)
print(res1.decode('utf8'))
res1 = conn.recv(1024)
print(res1.decode('utf8'))
# 客户端
import socket
client = socket.socket() # 创建socket对象
client.connect(('127.0.0.1', 8889)) # 连接服务端地址
client.sendall(b'hello a ')
client.sendall(b'hello b ') # 发送消息
client.sendall(b'hello c ')
被一次性接收完了,数据粘在一起了
粘包现象产生的原因
1.不知道每次的数据流到底多大
2.TCP也称为流式协议:数据像水流一样绵绵不绝没有间隔(TCP会针对数据量较小且发送间隔较短的多余数据一次性合并打包发送)
避免粘包现象的核心思路\关键点
如何明确即将接收的数据具体由多大
也就是如何将长度变化的数据全部制作成固定长度的数据
struct模块
# 服务端
import socket
import struct
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8899))
server.listen(5)
while True:
conn, addr = server.accept()
try:
while True:
res_head = conn.recv(4)
head_len = struct.unpack('i', res_head)[0] # 是个元组(长度)# (14,) 根据固定长度的报头 解析出真实数据的长度
res_data = conn.recv(head_len)
print(res_data.decode('utf8'))
except BaseException:
conn.close()
# 客户端
import socket
import struct
client = socket.socket()
client.connect(('127.0.0.1', 8899)) # 连接服务端地址
msg1 = b'hello a '
msg2 = b'hello b '
msg3 = b'hello c '
send_head1 = struct.pack('i', len(msg1)) # 将数据打包成固定的长度 i是固定的打包模式
send_head2 = struct.pack('i', len(msg2))
send_head3 = struct.pack('i', len(msg3))
client.sendall(send_head1)
client.sendall(msg1)
client.sendall(send_head2)
client.sendall(msg2)
client.sendall(send_head3)
client.sendall(msg3)
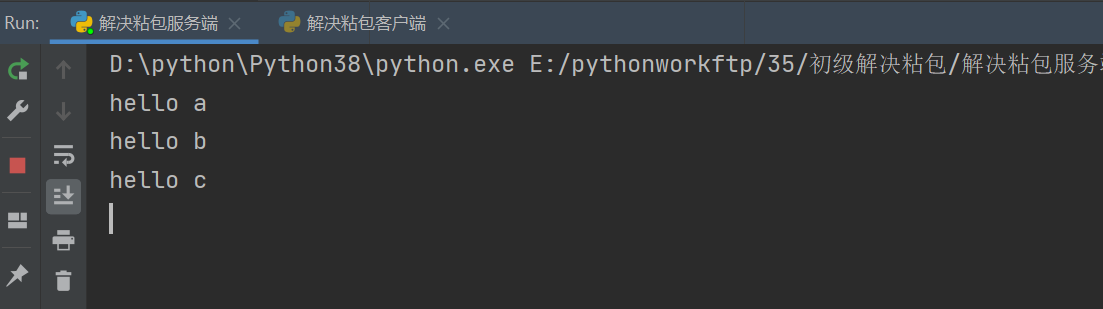
# 解决粘包
"""
解决粘包问题的初次版本
客户端
1.将真实数据转成bytes类型并计算长度
2.利用struct模块将真实长度制作一个固定长度的报头
3.将固定长度的包头先发送给服务端 服务端只需要在recv括号内填写固定长度的报头数字即可
4.然后再发送真实数据
服务端
1.服务端先接收固定长度的报头
2.利用struct模块反向解析出真实数据长度
3.recv接收真实数据长度即可
"""
"""
struct模块无法打包数据量较大的数据 就算换更大的模式也不行
# res = struct.pack('i', 12313213123)
# print(res)
"""
'''问题2:报头能否传递更多的信息 比如电影大小 电影名称 电影评价 电影简介'''
'''终极解决方案:字典作为报头打包 效果更好 数字更小'''
"""
黏包问题终极方案
客户端
1.制作真实数据的信息字典(数据长度、数据简介、数据名称)
2.利用struct模块制作字典的报头
3.发送固定长度的报头(解析出来是字典的长度)
4.发送字典数据
5.发送真实数据
服务端
1.接收固定长度的字典报头
2.解析出字典的长度并接收
3.通过字典获取到真实数据的各项信息
4.接收真实数据长度
"""
粘包终极解决办法实操
# 服务端
import socket
import struct
import json
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8889))
server.listen(5)
while True:
conn, addr = server.accept()
try:
while True:
res_head = conn.recv(4)
res_head_len = struct.unpack('i', res_head)[0]
res_file_bytes = conn.recv(res_head_len)
res_file_dict = json.loads(res_file_bytes)
real_name = res_file_dict.get('file_name')
real_size = res_file_dict.get('file_size')
print(res_file_bytes)
chunk = 0
base_len = 1024
'''接收真实数据的时候 如果数据量非常大 recv括号内直接填写该数据量 不太合适 我们可以每次接收一点点 反正知道总长度'''
with open(real_name, 'wb') as f:
while chunk < real_size:
res_data = conn.recv(base_len if real_size - chunk > base_len else real_size - chunk)
chunk += len(res_data)
f.write(res_data)
except BaseException:
conn.close()
# 客户端
import socket
import os
import struct
import json
client = socket.socket()
client.connect(('127.0.0.1', 8889))
file_dict = {
'file_name': 'avi.txt',
'file_size': os.path.getsize(r'E:\pythonworkftp\35\粘包\粘包现象服务端.py'),
'file_path': r'E:\pythonworkftp\35\粘包\粘包现象服务端.py'
}
file_bytes = json.dumps(file_dict).encode('utf8')
head_len = struct.pack('i', len(file_bytes))
client.sendall(head_len)
client.sendall(file_bytes)
with open(file_dict.get('file_path'), 'rb') as f:
for data in f:
client.sendall(data)
UDP协议(了解)
1.UDP服务端和客户端'各自玩各自的'
2.UDP不会出现多个消息发送合并
并发编程理论
理论非常多 实战很多
研究网络编程其实就是再研究计算机的底层原理及发展史
"""
计算机中真正干活的是CPU
"""
操作系统发展史
-
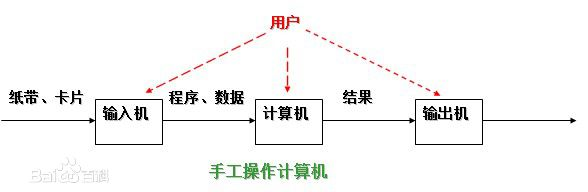
穿孔卡片阶段
计算机很庞大 使用很麻烦 一次只能给一个人使用 期间很多时候计算机都不工作好处:程序员独占计算机 为所欲为
坏处:计算机利用率太低 浪费资源
-
联机批处理系统
提前使用磁带一次性录入多个程序员编程的程序 然后交给计算机执行CPU工作效率有所提升 不用反复等待程序录入
-
脱机批处理系统|
极大地提升了CPU的利用率
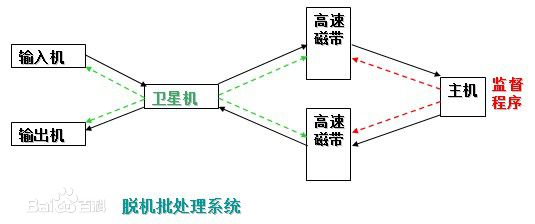
卫星机:一台不与主机直接相连而专门用于与输入/输出设备打交道的。
其功能是:
(1)从输入机上读取用户作业并放到输入磁带上。
(2)从输出磁带上读取执行结果并传给输出机。
这样,主机不是直接与慢速的输入/输出设备打交道,而是与速度相对较快的磁带机发生关系,有效缓解了主机与设备的矛盾。主机与卫星机可并行工作,二者分工明确,可以充分发挥主机的高速计算能力。
脱机批处理系统:20世纪60年代应用十分广泛,它极大缓解了人机矛盾及主机与外设的矛盾。
不足:每次主机内存中仅存放一道作业,每当它运行期间发出输入/输出(I/O)请求后,高速的CPU便处于等待低速的I/O完成状态,致使CPU空闲。
为改善CPU的利用率,又引入了多道程序系统。
-
总结:CPU提升利用率的过程
多道技术
再学习并发编程的过程中 不做刻意提醒的情况下 默认一台计算机就是一个cpu(只有一个干活的人)
-
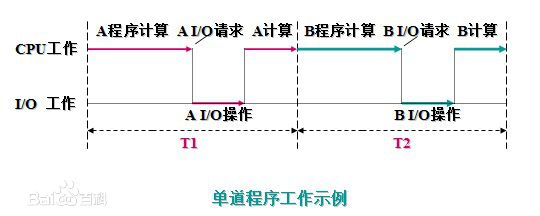
单道技术
所有的程序排队执行 过程中不能重合
-
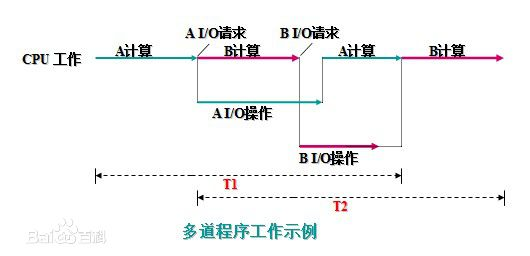
多道技术
利用空闲时间提前准备其他数据 最大化提升CPU利用率
-
多道技术详细
-
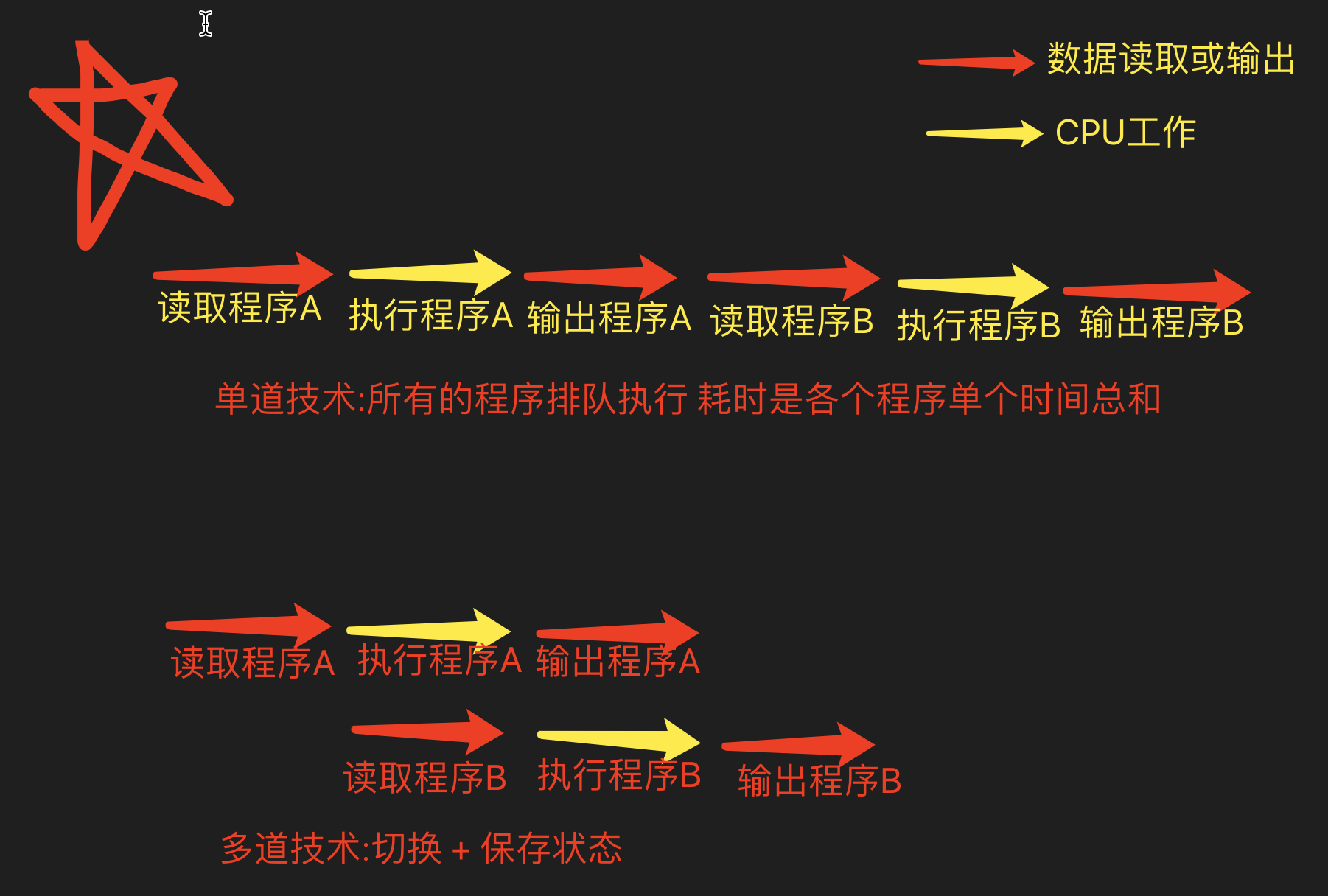
切换
计算机的CPU再两种情况下会切换(不让你用,给别人也)
-
程序有IO操作
输入输出操作input time.sleep read write 网络
-
程序长时间占用CPU
雨露均沾,让多个程序都能被cpu运行一下
-
-
保存状态
CPU每次切换走之前都需要保存当前操作的状态下次切换回来基于上次的进度继续执行
开了一家饭店 只有一个服务员 但是同时来了五桌客人
请问:如何让五桌客人都感觉到服务员在服务他们
让服务员化身为闪电侠 只要客人有停顿 就立刻切换到其他桌 如此往复
-
进程理论
进程与程序的区别
程序:一堆死代码(还没有被运行起来)
进程:正在运行的程序(被允许起来了)
进程的调度算法(重要)
-
FCFS(先来先服务)
对短作业不友好
-
短作业优先调度
对长作业不友好
-
时间轮转法+多级反馈队列(目前还在用)
将时间均分 然后根据进程时间长短再分多个等级
等级越靠下表示耗时越长 每次分到的时间越多 但是优先级越低
进程的并行与并发
-
并行
多个进程同时执行 必须有多个CPU参与 单个CPU无法实现并行 -
并发
多个进程看上去像是同时执行 单个CPU可以实现 多个CPU肯定也可以区别:
并行是从微观上,也就是在一个精确的时间片刻,有不同的程序在执行,这就要求必须有多个处理器。
并发是从宏观上,在一个时间段上可以看出是同时执行的,比如一个服务器同时处理多个session。判断下列两句话孰对孰错
我写的程序很牛逼,运行起来之后可以实现14个亿的并行量
并行量必须要有对等的CPU才可以实现
我写的程序很牛逼,运行起来之后可以实现14个亿的并发量
合情合理 完全可以实现 以后我们的项目一般都会追求高并发
ps:目前国内可以说是最牛逼的>>>:12306
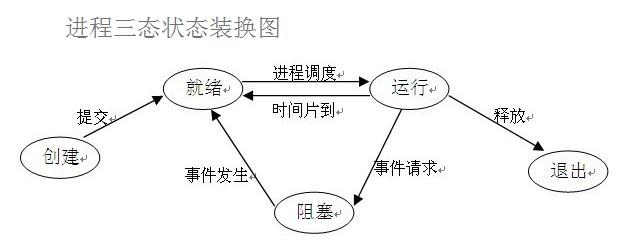
进程的三状态
-
就绪态
所有的程序再被CPU执行之前都必须先进入就绪态等待
-
运行态
CPU正在执行
-
阻塞态
进程运行过程中出现了IO操作 阻塞态无法直接进入运行态需要先进入就绪态

原文地址:http://www.cnblogs.com/clever-cat/p/16901240.html