
一、背景
- 神经网络中有两种超参数
- 优化器参数:关于优化和训练过程的超参数(学习率、批大小、训练轮数、优化器、激活函数、初始权重)
- 模型参数:关于模型结构的超参数(隐藏层单元数量、隐藏层数、过滤器大小、卷积块数量)
- 侧信道攻击中通常会使用 SNR 确定 POIs,这样将会降低分类复杂度
- 贡献:
- 使用梯度可视化观察网络如何选取特征,以评估模型超参数
- 使用两种新方法:权重可视化和热力图来观察网络卷积部分的作用
- 提出高效 CNN 的创建方法
二、预备知识
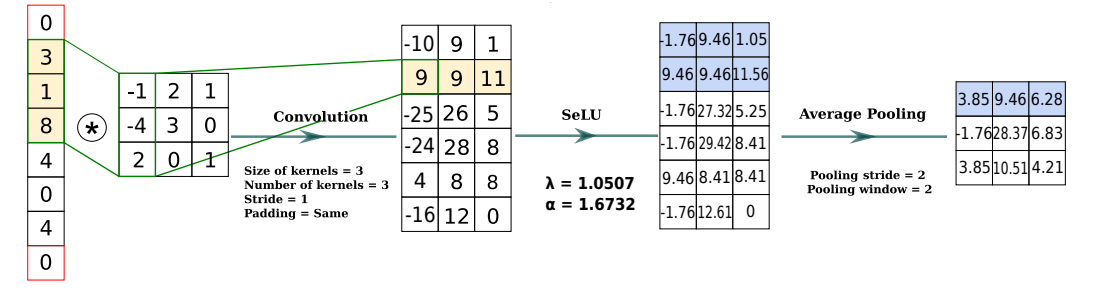
1 卷积层
卷积层输出揭示了影响分类的特征
-
模型超参数配置
- 过滤器长度:即过滤器单次匹配的能量迹样本点个数,长度较大的过滤器倾向于提取全局特征而长度较小的过滤器倾向于提取局部特征
- 过滤器步长:即过滤器窗口单次移动的距离,小步长重叠程度较大,大步长输出维度较小
- 填充方式(padding):即在能量迹上下各增加若干 0 样本点保证池化层输出与能量迹样本点数相同,防止丢失边界信息
-
激活函数 \(\sigma\) 用于判断哪些特征与分类相关,选用 SeLU 激活函数见式(1),即 ELU 的变形,乘以一个固定系数,将均值为 0 方差为 1 的输入映射到均值为 0 方差为 1 的输出,避免梯度消失和梯度爆炸问题
\[\begin{eqnarray} selu(x) = \lambda \begin{cases} x & x>0 \\ \alpha(e^x-1) & x \leq 0 \end{cases} \end{eqnarray} \]
2 池化层
池化层是通过下采样保留最相关信息的非线性层
- 模型超参数配置
- 池化窗口:单次池化操作匹配的输入特征个数
- 池化步长:池化窗口单次移动的距离
- 池化函数
- 最大池化:输出定义为池化窗口中最大值
- 平均池化:输出定义为池化窗口中平均值
3 Flatten 层
Flatten 层连接卷积块输出,将二维向量转化为一维向量
4 全连接层
全连接层结合 Flatten 层每个神经元准确分类输入
三、特征选取评估
1 State of the art
1.1 信噪比(SNR)
信噪比是侧信道领域常用的选取特征(POIs)工具,但反制措施如非同步化存在时,使用 SNR 分析比较困难
1.2 可视化技术
梯度可视化计算对输入迹特征的偏导数,找到对分类影响最大的特征
1.3 局限
上述技术只给出了找到有效特征的方法,而没有理解卷积和分类部分选取特征的方式 / 准则
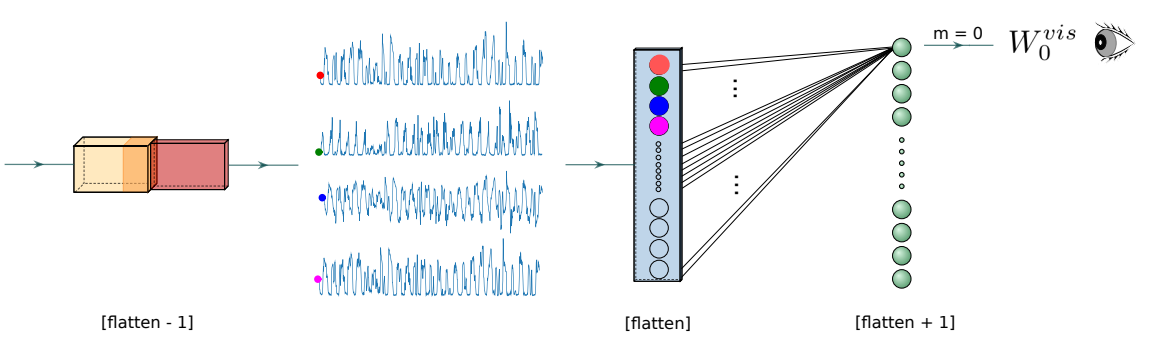
2 权重可视化
-
原理:训练过程中网络评估神经元对于有效分类的影响力,如果网络对一些神经元的预测非常信任,将会给予它们很大的权重,通过可视化可训练参数(权重)即可观察出网络如选择特征
-
方法:可视化 Flatten 层权重,找到对分类影响大的中间迹样本点,再通过前向传播得到对分类影响大的能量迹样本点
-
\(n_u^{[flatten+1]}\) 表示 Flatten 层后神经元数量
\(n_f^{[flatten-1]}\) 表示最后一个卷积块中过滤器数量,也即中间迹个数
\(dim_{trace}^{[flatten-1]}\) 表示中间迹维度
\(W_m^{vis}[i]=\frac{1}{n_f^{[flatten-1]}}\sum_{j=i×n_f^{[flatten-1]}}^{(i+1)×n_f^{[flatten-1]}}|W_m^{[flatten|}[j]|\)
\(W^{vis}[i]=\frac{1}{n_u^{[flatten+1]}}\sum_{m=0}^{n_u^{[flatten+1]}}W_m^{vis}[i]\)
上式将所有中间迹样本点 trace[i] 和神经元 m 之间平均权重
下式将所有神经元对应的样本点 trace[i] 平均权重进行算术平均
3 热图
-
权重可视化虽然有用但仍然无法帮助我们理解每个过滤器选取了哪些特征,即中间迹样本点和能量迹样本点的关系
-
\(n_f^{[h]}\) 表示卷积部分第 h 个隐藏层中过滤器数量
\(input^{[h]}\) 表示第 h 个卷积块的输入
\(f_i^{[h]}\) 表示卷积部分第 h 个隐藏层中第 i 个过滤器
第 h 层热图即求输入向量与过滤器卷积操作(即中间迹)的算术平均值,表示为下式
\(H^{[h]}=\frac{1}{n_f^{[h]}}\sum_{i=0}^{n_f^{[h]}}(input^{[h]}\otimes f_i^{[h]})\)
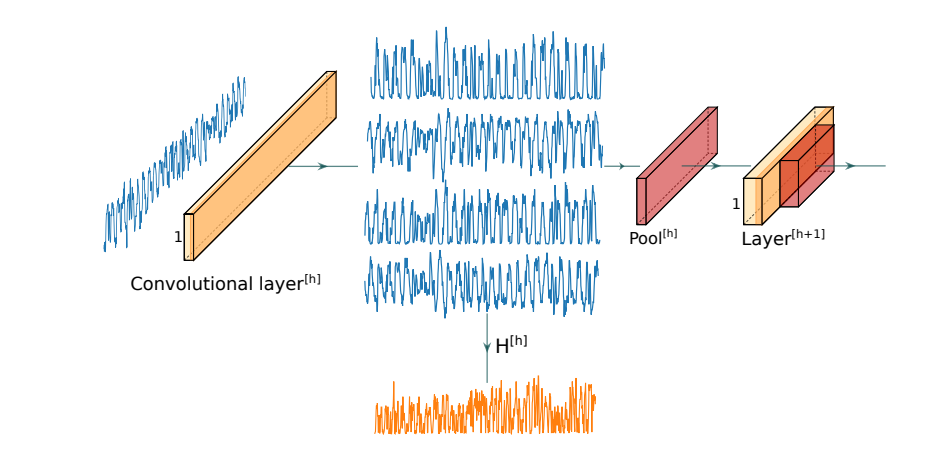
- 通过热图可以评估哪些神经元被过滤器激活,以理解神经网络对特征的选择策略
四、创建有效 CNN 结构
分析卷积部分模型超参数对于模型效果的影响
1 配置
2 过滤器长度
-
增加过滤器长度将导致神经元之间的纠缠,降低关于单个信息的权重和正确检测 POIs 的能力
-
为了最大化对 l 个 POIs 的检测,将卷积操作定义为 \((t \otimes W)[i]=\sum_{j=0}^n(t[j+i-\frac{n}{2}]×W[j])\),其中
\[\begin{eqnarray} t[j+i-\frac{n}{2}]×W[j]= \begin {cases} w_j×t[j+i-\frac{n}{2}] & j∈E \\ \epsilon & otherwise \end{cases}\end{eqnarray} \]i 为卷积层输出索引,j 为样本点索引,n 为过滤器长度
-
输入特征将会分散到长度为 2n 的样本点区间内,为了保证降低神经元纠缠而导致特征分散的风险,建议最小化过滤器长度
3 卷积块数量
-
平均池化相比于其它池化的好处是保留非共享信息(?),但即使如此池化层仍然会减少相关信息
当对一个泄露信息进行两个连续池化操作,该信息将在样本中传播,则相应泄露权重就会降低,并且其它较小的泄露将会被丢弃
-
增大卷积块数量能够在保留相关信息的条件下降低中间迹维度,就可以允许每个卷积块中的池化步长减小
-
在第一隐藏层中使用平均池化更有利于提取特征,而最大池化更适用于深度较大的网络层
网络深度越大,对于特征的提取越模糊,但处理非同步问题的效果越好
4 网络构建方法
\(N^{[h]}\) 表示第 h 卷积块处理后最大非同步程度,\(N^{[h]}=\frac{N^{[h-1]}}{pooling_stride^{[h-1]}}\)
\(pooling\_stride^{[h]}\) 表示第 h 个卷积块池化步长
\(D^{[h]}\) 表示第 h 卷积块处理后中间迹维度,\(D^{[h]}=\frac{D^{[h-1]}}{pooling_stride^{[h-1]}}\)
4.1 同步迹
- 当训练集、验证集、测试集同步时建立网络不需要多个卷积块数量,因为存在两个缺点,当没有非同步的情况时建议使用一个卷积块
- POIs 位置接近时,多个卷积块容易导致特征的纠缠(相关信息在神经元上的传播)
- 池化层将导致部分信息丢失
- 在处理同步迹时,相比于 MLP 的全连接层,CNN 更专注于小部分对分类决策贡献大的样本
4.2 非同步迹(随机延迟)
-
将 \(Nt_{GE}(model_{N^{[0]}})\) 定义为猜测熵固定为 1 时所需要的训练能量迹个数
\(Nt_{GE}(model_{N^{[0]}}):=min\{t_{test}|\forall t>=t_{test},g(k^*)(model_{N^{[0]}}(t))=1\}\)
-
将卷积部分划分为三块
-
第一卷积块减少纠缠
最小化过滤器长度为 1 以降低 POIs 之间的纠缠,以便于提取秘密信息
将池化窗口设置为 2 以降低中间迹维度
-
第二卷积块探测非同步
过滤器长度设置为 \(\frac{N^{[0]}}{2}\) 将网络的注意力放在对每条中间迹的非同步检测上
池化窗口设置 \(\frac{N^{[0]}}{2}\) 以最大化降低中间迹维数
-
第三卷积块去除不相关信息
将中间迹维度降低到 L(即 POI 个数),极大限制了非同步效应
-
4.3 讨论
利用差分绝对组合函数(见附录),该网络不受布尔掩码实现的 AES 算法负面影响
原文地址:http://www.cnblogs.com/buaa19231055/p/16903773.html