
黏包现象
黏包现象
1.服务端连续执行三次recv
2.客户端连续执行三次send
执行上述两端的操作,服务端一次性接收到客户端三次的消息,该现象称为‘粘包现象’,如下图:
黏包现象如下:
1.执行上述两端的操作,服务端一次性接收到客户端三次的消息:发送端需要等缓冲区满才发送出去,造成黏包(发送数据时间间隔很短,数据很小,会合并一起,产出黏包)
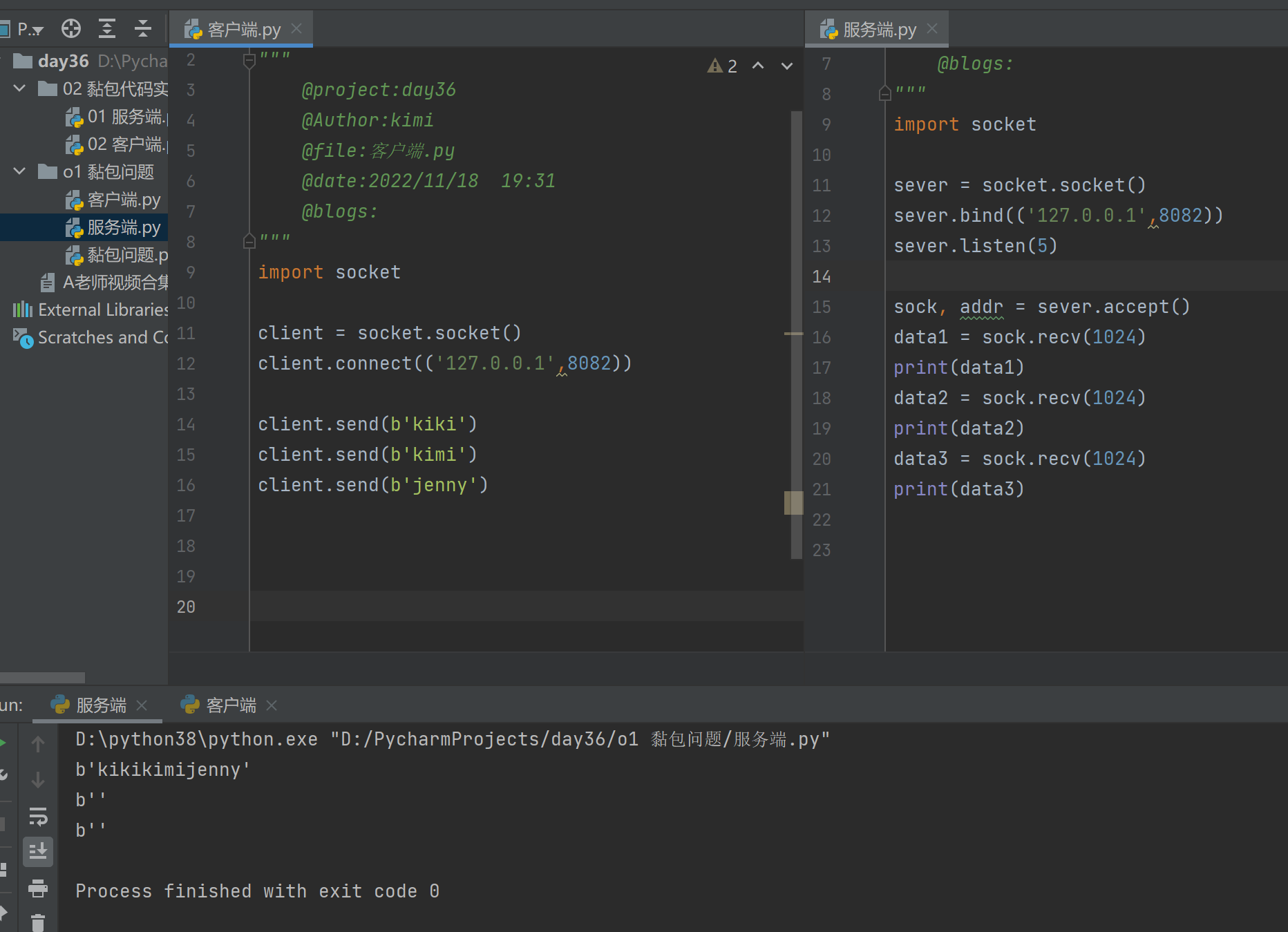
2.同时将接收的字节数改为5个字节,服务端接收客户端的字节不够,就会朝着第二次客户端发送的字节拿一个字节,第二次打印就会从上次断开的地方接着打印(接收方不及时接收缓冲区的包,造成多个包接收)
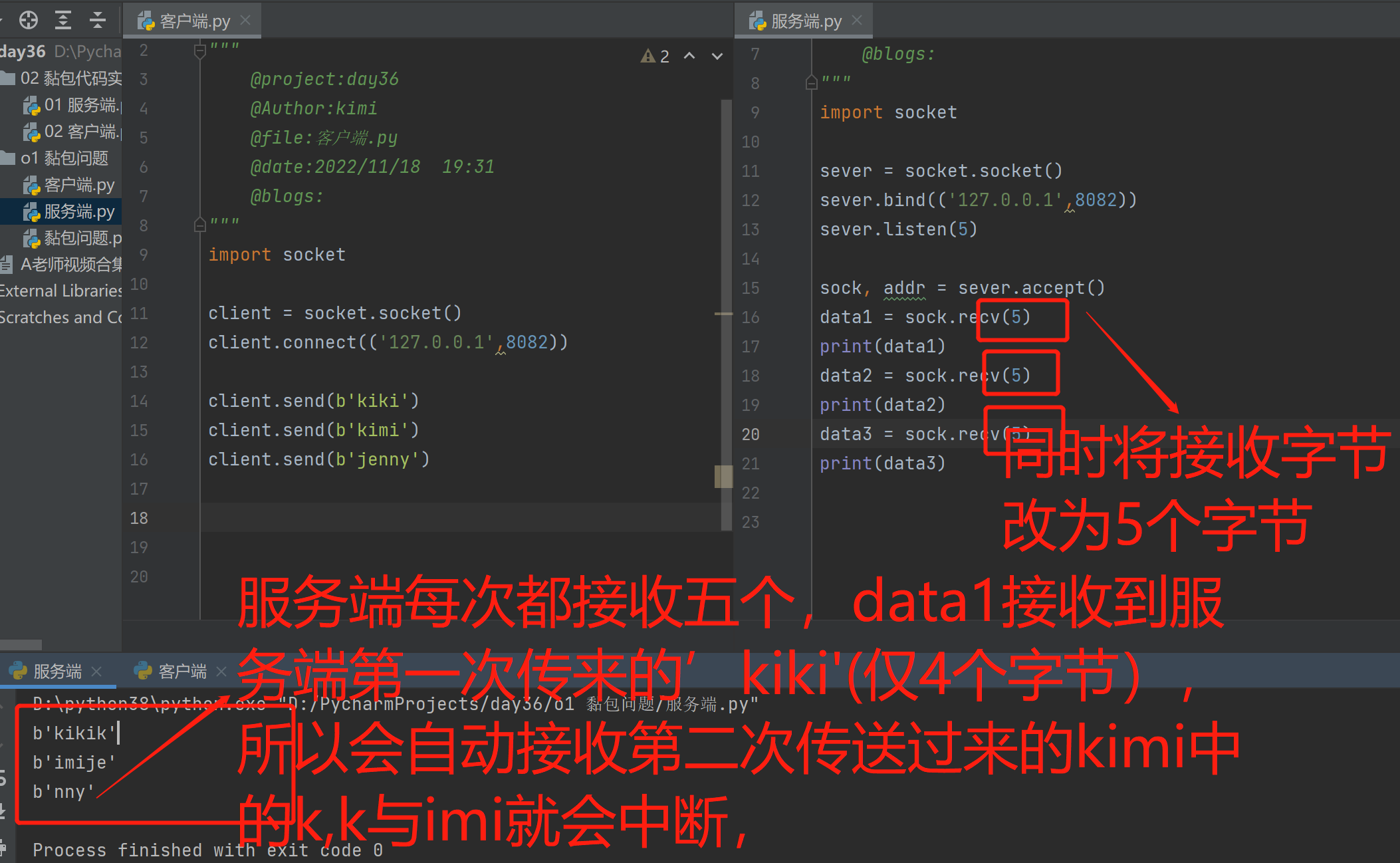
3.要是想解除上述现象,服务端接收的字节数就必须根据客户端发送的数据大小
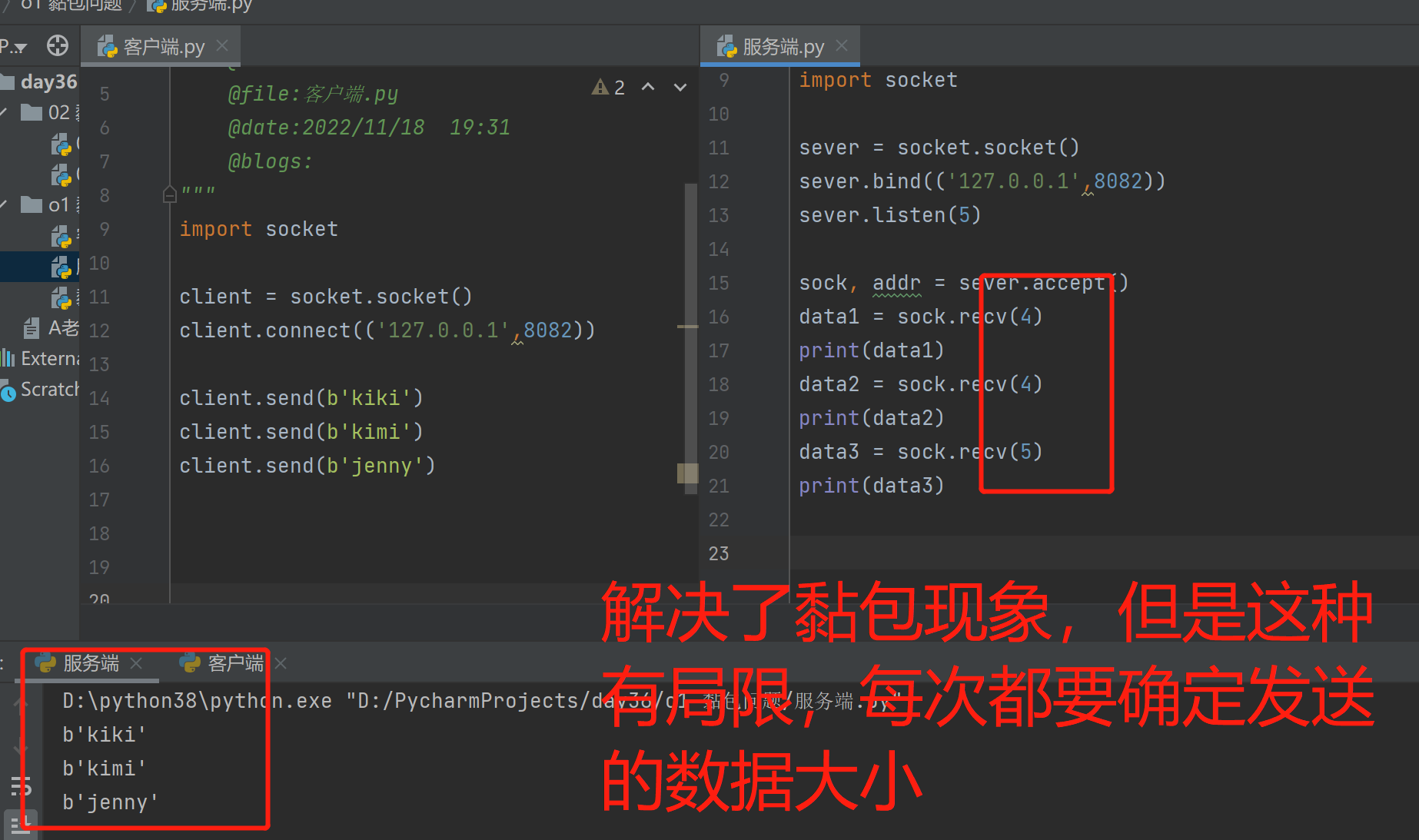
黏包现象的产生的原因:
1.不知道每次的数据的大小
2.TCP也称为流式协议,数据像水流一样绵绵不绝没有间断,一条直线的传,不会间断。(TCP会针对数据量较小且发送间隔较短的多条数据一次性合并打包发送)
总结:黏包现象只发生在TCP协议中:
1.从表面上看,黏包问题主要是因为发送方和接收方的缓存机制、tcp协议面向流通信的特点。
2.实际上,主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的
存在的问题:
程序的运行速度远快于网络传输速度,所以在发送一段字节前,先用send去发送该字节流长度,这种方式会放大网络延迟带来的性能损耗
如何避免黏包现象的核心思路/关键点
如何明确服务端每次接收的数据字节的数量?如何将长度变化的数据全部制作成固定长度的数据>>>>引入了struct模块
struct模块
我们可以借助一个模块,这个模块可以把要发送的数据长度转换成固定长度的字节。这样客户端每次接收消息之前只要先接受这个固定长度字节的内容看一看接下来要接收的信息大小,那么最终接受的数据只要达到这个值就停止,就能刚好不多不少的接收完整的数据了。
struct模块可以将非固定长度的数字转为固定长度(len=4)的数字,语法结构为:struct.pack(‘i’, len(数据变量名)),其中’i’是固定的参数。打包的过程也称为’报头’。
案例1
import struct # 引入模块
info = b'hello my friend'
1.数据真实的长度(bytes)
# print(len(info)) # 15
2.# 将数据打包成固定的长度。i 是固定的打包模式
res = struct.pack('i',len(info))
3.# 打包之后的长度为(bytes) 也称为报头
print(len(res)) # 4
4.根据固定长度的报头解析出真实数据的长度
real_len = struct.unpack('i',res)
5.打印解析真实数据的长度
print(real_len) # (15,)
案例2
import struct # 引入模块
desc = b'hello my sister want to buy some fruit'
# 1. 数据真实的长度(bytes)
print(len(desc)) # 38
# 2. # 将数据打包成固定的长度。
res1 = struct.pack('i',len(desc))
# 3.打印打包之后的长度为(bytes)
print(len(res1)) # 4 报头
# 4.解析出真实数据的长度
real_desc = struct.unpack('i',res1)
print(real_desc) # (38,)
解决黏包现象
解决黏包问题的初次版本
客户端
1.将真实数据转为bytes类型并计算长度
desc = b'hello my sister want to buy some fruit'
# 1. 数据真实的长度(bytes)
print(len(desc)) # 38
2.利用struct模块将真实长度制作一个固定长度的报头
res1 = struct.pack('i',len(desc))
3.将固定长度的报头先发送给服务端,服务端只需要在recv括号内填写固定长度的报头数据即可
4.然后发送真实数据
服务端
1,服务端先接收固定长度的报头
2.利用struct模块反向解析出真实数据长度
3.recv接收真实数据长度即可
字节有限制:
问题1:struct模块无法打包数据量较大的数据,就算换更大的模式也不行。
允许的字节范围为:-2147483647<真实长度>2147483647(字节)
import struct
res = struct.pack('i',12313213123)
print(res) # struct.error: argument out of range
问题2:报头是否传递更多的信息,比如电影的大小、电影的名字、电影评价、电影简介
解除黏包问题的终极版本
解决上述两个问题:使用字典作为报头,效果更好
data_dict = {
'file_name':'xxx老师教学',
'file_size':1245323445325433455434654365465,
'file_info':'教学课程还可以',
'file_desc':'可以来听一听'
}
import json
data_json = json.dumps(data_dict)
print(len(data_json.encode('utf8'))) # 真实字典的长度 202
res = struct.pack('i',len(data_json.encode('utf8')))
print(len(res)) # 4
客户端
1.制作真实数据的信息字典(数据长度、数据简介、数据名称)
2.利用struct模块制作字典的报头
3.发送固定长度的报头(解析出来的是字典的长度)
4.发送字典数据
5.发送真实数据
服务端
1.接收固定长度的字典报头
2.解析出字典的长度并接收
3.通过字典获取真实数据的各项信息
4.接收真实数据长度
上述就基本解决了黏包的问题,但是上述的解决了方案,却忽视了struct模块能压缩数字是有限的,具体如下图:
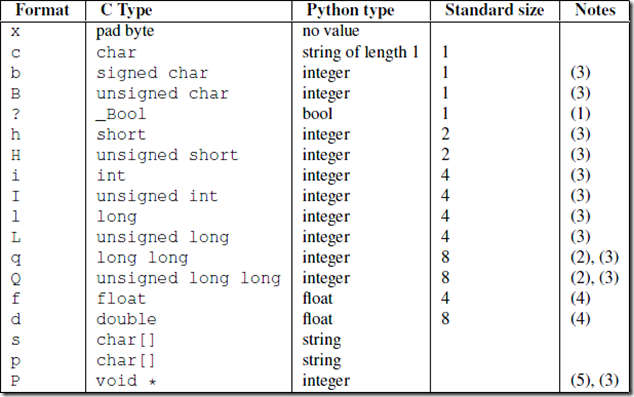
struct模块是用i模式来压缩的,不过无论用什么模式,这个数字都有上限。所以解决方案就是下载之前就要看被下载的文件的详细信息
黏包代码实操
服务端
import socket
import struct
import json
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
sock,addr = server.accept()
# 1.接受固定长度的字典报头
data_dict_head = sock.recv(4)
#2.根据报头解析出字典数据的长度
data_dict_len = struct.unpack('i',data_dict_head)[0]
# 3.接收字典数据
data_dict_bytes = sock.recv(data_dict_len)
data_dict = json.loads(data_dict_bytes) # 自动解码再反序列化
# 4.获取真实数据的各项信息
# total_size = data_dict.get('file_size')
# with open(data_dict.get('file_name'),'wb')as f:
# f.write(sock.recv(total_size))
'''接收真实数据的时候 如果数据量非常大 recv括号内直接填写该数据量 不太合适 我们可以每次接收一点点 反正知道总长度'''
total_size = data_dict.get('file_size')
recv_size = 0 # 初始接收了0字节的数据
with open(data_dict.get('file_name'),'wb') as f:
while recv_size<total_size: # 当接收量不在小于文件总大小,则停止接收
data = sock.recv(1024) # 每次接收1024个字节
f.write(data) # 写入本地
recv_size += len(data) # 每次接收后,将接收到的数据量记录下来
print(recv_size)
客户端
import socket
import os
import struct
import json
client = socket.socket()
client.connect(('127.0.0.1',8080))
"""任何文件都是下列思路 图片 视频 文本。。。"""
# 1.获取真实数据大小
file_size = os.path.getsize(r'D:\PycharmProjects\day36\A老师视频合集.txt')
# 2.制作真实数据的字典数据
data_dict = {
'file_name':'视频题材不错.txt',
'file_size':file_size,
'file_desc':'看电影标配奶茶和爆米花',
'file_info':'这是我喜欢的系列之一'
}
# 3.制作字典报头
data_dict_bytes = json.dumps(data_dict).encode('utf8')
data_dict_len = struct.pack('i',len(data_dict_bytes))
# 4.发送字典报头
client.send(data_dict_len) # 报头本身也是bytes类型,我们在看到的时候len长度是4
# 5.发送字典
client.send(data_dict_bytes)
# 6.最后发送真实数据
with open(r'D:\PycharmProjects\day36\A老师视频合集.txt','rb') as f:
for line in f: # 一行行发送 ,和直接一起发送效果是一样的,因为TCP流式协议的特性
client.send(line) # 最终发送文件本身
import time
time.sleep(10)
UDP协议(了解)
1.UDP服务端和客户端‘各自玩各自’
2.UPD不会出现多个消息发送合并
服务端代码:
import socket
sever = socket.socket(type=socket.SOCK_DGRAM)
sever.bind(('127.0.0.1', 8081))
while True:
data, addr = sever.recvfrom(1024)
print('客户端地址>>>:', addr)
print('上述地址罚送的消息>>>:', data.decode('utf8'))
msg = input('>>>').strip()
sever.sendto(msg.encode('utf8'), addr)
客户端1:
import socket
client = socket.socket(type=socket.SOCK_DGRAM)
sever_addr = ('127.0.0.1', 8081)
while True:
msg = input('>>>').strip()
client.sendto(msg.encode('utf8'), sever_addr)
data, addr = client.recvfrom(1024)
print(data.decode('utf8'), addr)
客户端2:
import socket
client = socket.socket(type=socket.SOCK_DGRAM)
sever_addr = ('127.0.0.1', 8081)
while True:
msg = input('>>>').strip()
client.sendto(msg.encode('utf8'), sever_addr)
data, addr = client.recvfrom(1024)
print(data.decode('utf8'), addr)
原文地址:http://www.cnblogs.com/zhanglanhua/p/16904991.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性