
1 # !/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 # 参考自:https://blog.csdn.net/qq_39395755/article/details/109305055?spm=1001.2014.3001.5502 4 5 import torch 6 import torch.nn as nn 7 import torch.nn.functional as func 8 import torchvision 9 import matplotlib.pylab as plt 10 import numpy as np 11 12 13 14 batch_size = 160 15 16 # 将读取的图片转换为tensor 并标准化 17 transform = torchvision.transforms.Compose([ 18 torchvision.transforms.ToTensor(), 19 torchvision.transforms.Normalize(mean=[0.5], std=[0.5]) 20 ]) 21 """ 22 ToTensor()能够把灰度范围从0-255变换到0-1之间,而后面的transform.Normalize()则把0-1变换到(-1,1).具体地说,对每个通道而言,Normalize执行以下操作: 23 image=(image-mean)/std 24 其中mean和std分别通过(0.5,0.5,0.5)和(0.5,0.5,0.5)进行指定。原来的0-1最小值0则变成(0-0.5)/0.5=-1,而最大值1则变成(1-0.5)/0.5=1. 25 因为用到的mnist为灰度图 单通道 所以mean和std 只用了一个值 26 数据如果分布在(0,1)之间,可能实际的bias,就是神经网络的输入b会比较大,而模型初始化时b=0的,这样会导致神经网络收敛比较慢,经过Normalize后,可以加快模型的收敛速度。 27 因为对RGB图片而言,数据范围是[0-255]的,需要先经过ToTensor除以255归一化到[0,1]之后,再通过Normalize计算过后,将数据归一化到[-1,1]。 28 """ 29 30 dataset = torchvision.datasets.MNIST("./MNIST", train=True, transform=transform, download=True)# 如果MNIST数据集有的话,download可以设置为False 31 data_loader = torch.utils.data.DataLoader(dataset=dataset, batch_size = batch_size, shuffle=True) # shuffle乱序 32 device = torch.device("cuda") 33 34 def denomalize(x): 35 """还原被标准化后的图像""" 36 out = (x+1) / 2 37 out = out.view(32, 28, 28).unsqueeze(1) # 添加channel 38 return out.clamp(0,1) 39 40 def imshow(img, epoch): 41 """打印生成器产生的图片""" 42 # torchvision.utils.make_grid用来连接一组图, img为一个tensor(batch, channel, height, weight) 43 # .detach()消除梯度 44 im = torchvision.utils.make_grid(img, nrow=8).detach().numpy() 45 # print(np.shape(im)) 46 plt.title("Epoch on %d" % (epoch+1)) 47 plt.imshow(im.transpose(1, 2, 0)) # 调整图形标签, plt的图片格式为(height, weight, channel) 48 plt.savefig('./save_pic/%d.jpg' % (epoch+1)) 49 plt.show() 50 51 # 判别器模型 52 class DNet(nn.Module): 53 def __init__(self): 54 super(DNet, self).__init__() 55 56 self.l1 = nn.Linear(28*28, 256) 57 self.a = nn.ReLU() 58 self.l2 = nn.Linear(256, 128) 59 self.l3 = nn.Linear(128, 1) 60 self.s = nn.Sigmoid() 61 62 63 def forward(self, x): 64 x = self.l1(x) 65 x = self.a(x) 66 x = self.l2(x) 67 x = self.a(x) 68 x = self.l3(x) 69 x = self.s(x) 70 71 return x 72 73 74 # 生成器模型 75 class GNet(nn.Module): 76 def __init__(self): 77 super(GNet, self).__init__() 78 79 self.l1 = nn.Linear(10, 128) 80 self.a = nn.ReLU() 81 self.l2 = nn.Linear(128, 256) 82 self.l3 = nn.Linear(256, 28*28) 83 self.tanh = nn.Tanh() 84 85 def forward(self, x): 86 x = self.l1(x) 87 x = self.a(x) 88 x = self.l2(x) 89 x = self.a(x) 90 x = self.l3(x) 91 x = self.tanh(x) 92 93 return x 94 95 # 构建模型并送入GPU 96 D = DNet().to(device) 97 G = GNet().to(device) 98 99 print(D) 100 print(G) 101 102 # 设置优化器 103 D_optimizer = torch.optim.Adam(D.parameters(), lr=0.001) 104 G_optimizer = torch.optim.Adam(G.parameters(), lr=0.001) 105 106 107 108 109 for epoch in range(250): 110 cerrent = 0.0 # 正确识别 111 for step, data in enumerate(data_loader): 112 # 获取真实图集 并拉直 113 real_images = data[0].reshape(batch_size, -1).to(device) 114 115 # 构造真假标签 116 real_labels = torch.ones(batch_size, 1).to(device) 117 fake_labels = torch.zeros(batch_size, 1).to(device) 118 119 # 训练辨别器 分别将真图片和真标签喂入判别器、生成图和假标签喂入判别器 120 # 判别器的损失为真假训练的损失和 121 # print(real_images.size()) 122 real_outputs = D(real_images) 123 real_loss = func.binary_cross_entropy(real_outputs, real_labels) 124 125 z = torch.randn(batch_size, 10).to(device) # 用生成器产生fake图喂入判别器网络 126 fake_images = G(z) 127 d_fake_outputs = D(fake_images) 128 fake_loss = func.binary_cross_entropy(d_fake_outputs, fake_labels) 129 130 d_loss = real_loss + fake_loss 131 G_optimizer.zero_grad() 132 D_optimizer.zero_grad() 133 d_loss.backward() 134 D_optimizer.step() 135 136 # 训练生成器 137 z = torch.randn(batch_size, 10).to(device) 138 fake_images = G(z) 139 fake_outputs = D(fake_images) 140 g_loss = func.binary_cross_entropy(fake_outputs, real_labels) # 将fake图和真标签喂入判别器, 当g_loss越小生成越真实 141 G_optimizer.zero_grad() 142 D_optimizer.zero_grad() 143 g_loss.backward() 144 G_optimizer.step() 145 146 147 if step % 20 == 19: 148 print("epoch: " , epoch+1, " step: ", step+1, " d_loss: %.4f" % d_loss.mean().item(), 149 " g_loss: %.4f" % g_loss.mean().item(), " d_acc: %.4f" % real_outputs.mean().item(), 150 " d(g)_acc: %.4f" % d_fake_outputs.mean().item()) 151 # 每10个epoch 进行一次生成 152 if epoch % 10 == 9: 153 z = torch.randn(32, 10).to(device) 154 img = G(z) 155 156 imshow(denomalize(img.to("cpu")), epoch) 157 158 159 160 torch.save(D.state_dict(), "./D.pth") 161 torch.save(G.state_dict(), "./G.pth")
250个epoch后:
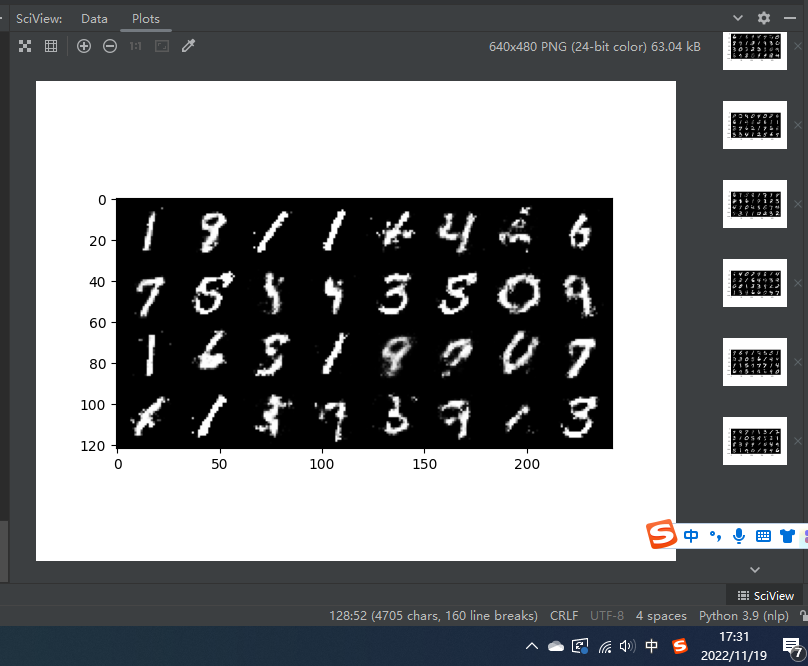
原文地址:http://www.cnblogs.com/zhouyeqin/p/16906603.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性