
最近又用到了,感觉机器学习中数据集处理还比较常用
关于模型的数据集划分
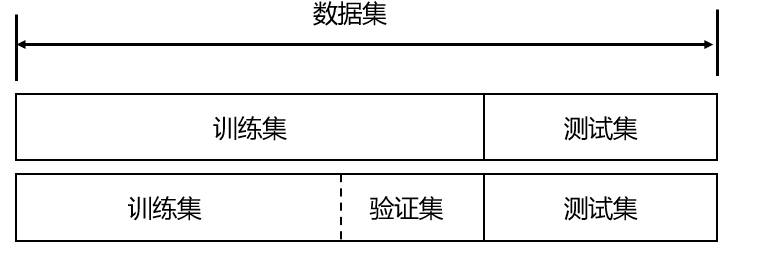
为了保证模型能起到预期的作用,一般需要将样本分成独立的三部分,分别为:
- 训练集:用于估计模型
- 验证集:用于确定网络结构或者控制模型复杂程度的参数。
- 测试集:用于检验最优的模型的性能。
其中,最典型的划分方式就是 训练集50%,验证集25%,测试集25%
在训练集上训练模型,在验证集上评估模型。一旦找到了最佳参数,就在测试集数据上最后测试一次。
K折交叉验证
原因:不同的训练集和测试集的划分方式和比例差距很大,对预测模型的准确率影响也很大,因此划分方式就需要优化。
为了避免因为数据集划分的偏差,通俗点儿也就是为什么这一部分被划分为训练集,而那一部分就是规定是测试集,难免会划分不公平或者不太合理。那么,就有一个很好的想法:
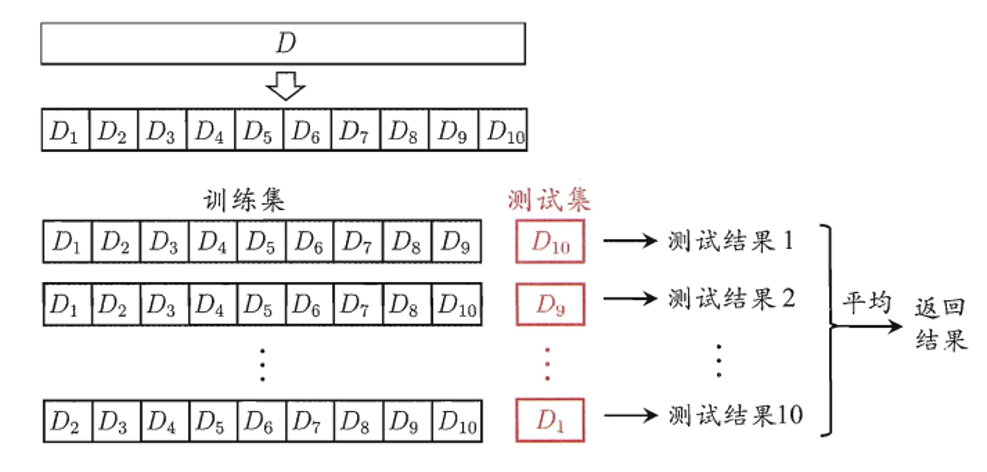
交叉验证。即每组训练集中都调一份作为测试集
K折交叉验证的基本步骤与思路
- 将样本随机打乱shuffle,同时均匀分为k份(这就是为啥叫K折)
- 划分为K份,就代表了验证集的组成就有K种。即轮流不重复地选择K-1份作为训练集,而每次的剩下那份就是验证集。
- 把K次的评估标准的均值作为选择最优模型结构的依据
选择最入门的数据集之一:鸢尾花数据集作为样例
import sklearn.datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
dataset = sklearn.datasets.load_iris()
X, y = dataset.data, dataset.target
model = KNeighborsClassifier() # 模型选择
kfold = KFold(n_splits=5, random_state=3,shuffle = ‘True’)
results = cross_val_score(model, X, y, cv=kfold, scoring='accuracy')
print("acc: %.3f (%.3f)" % (results.mean(), results.std()))
# 得出结果为acc:0.913(0.083),这里选择了用5折交叉验证的方法(因为n_splits=5)
原文地址:http://www.cnblogs.com/sdnu-dfl/p/16908589.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性