
目录
1. RDD的创建方式
1.1 从内存创建RDD
主要依赖如下两个方法
- parallelize
- makeRDD
- 底层调用的还是
parallelize
- 底层调用的还是
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
val rdd1: RDD[Int] = sparkContext.parallelize(
List(1, 2, 3, 4)
)
// makeRDD 底层调用的还是parallelize
val rdd2: RDD[Int] = sparkContext.makeRDD(
List(1, 2, 3, 4)
)
}
1.2 从外部存储(文件)创建RDD
由外部存储系统的数据集创建RDD包括
- 本地文件系统
- 所有Hadoop支持的数据集,比如HDFS、HBase等
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
val rdd1: RDD[String] = sparkContext.textFile("data") // 或者 hdfs://master:7077/input
rdd1.collect().foreach(println)
sparkContext.stop()
}
1.3 从其他的RDD创建
下述的flatMap map reduceByKey 每个操作都是以上一个RDD为基础创建另一个RDD
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
val rdd1: RDD[String] = sparkContext.textFile("data") // 或者 hdfs://master:7077/input
rdd1
.flatMap(word => word.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
.collect()
.foreach(println)
sparkContext.stop()
}
1.4 直接 new RDD
spark框架中会这么操作
2. 分区(partition)
2.1 makeRDD的分区
可以通过以下优先级方式指定分区
- 优先使用
makeRDD的第二个参数指定的分区数量 - 使用默认的配置的分区数量
- SparkConf 若指定了
spark.default.parallelism, 则用这个 - 否则使用CPU的核数(这里的CPU的核数在本地模式下,如
local[3]则为3,local[*]等于物理机真实的CPU核数)
- SparkConf 若指定了
// 第二个参数指定numSlices, 即分区的数量
val rdd: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 2)
完整的表现分区的例子
package com.lzw.bigdata.spark.core.rdd_basic_usage_1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Rdd_4_Partition_From_Mem {
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
// .set("spark.default.parallelism", "5")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
val rdd: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 2)
// 保存成分区文件,每个分区会生成一个文件,可以借此查看真实生成了几个分区
rdd.saveAsTextFile("output")
sparkContext.stop()
}
}
2.2 读取文件的分区例子
spark读取文件借助的是hadoop的方法, 所以以下的读取规则是hadoop的规则
// 可以指定 minPartitions, 不指定默认是 math.min(defaultParallelism, 2)
sparkContext.textFile("data/word.txt", 2)
以以下一个文件word.txt为例, 该文件算上换行符\n一共13个字节
1234
567
8900
2.2.1 读取文件分区规则
所以分区数计算方式为
分区数: 13 bytes / 2(这里2是minPartitions) = 6
13 bytes / 6 bytes = 2分区 + 剩余的1byte => 1/6 > 0.1 => 3分区
2.2.2 每个分区的数据
每个分区里面的数据, (hadoop按偏移量之后按行读取):
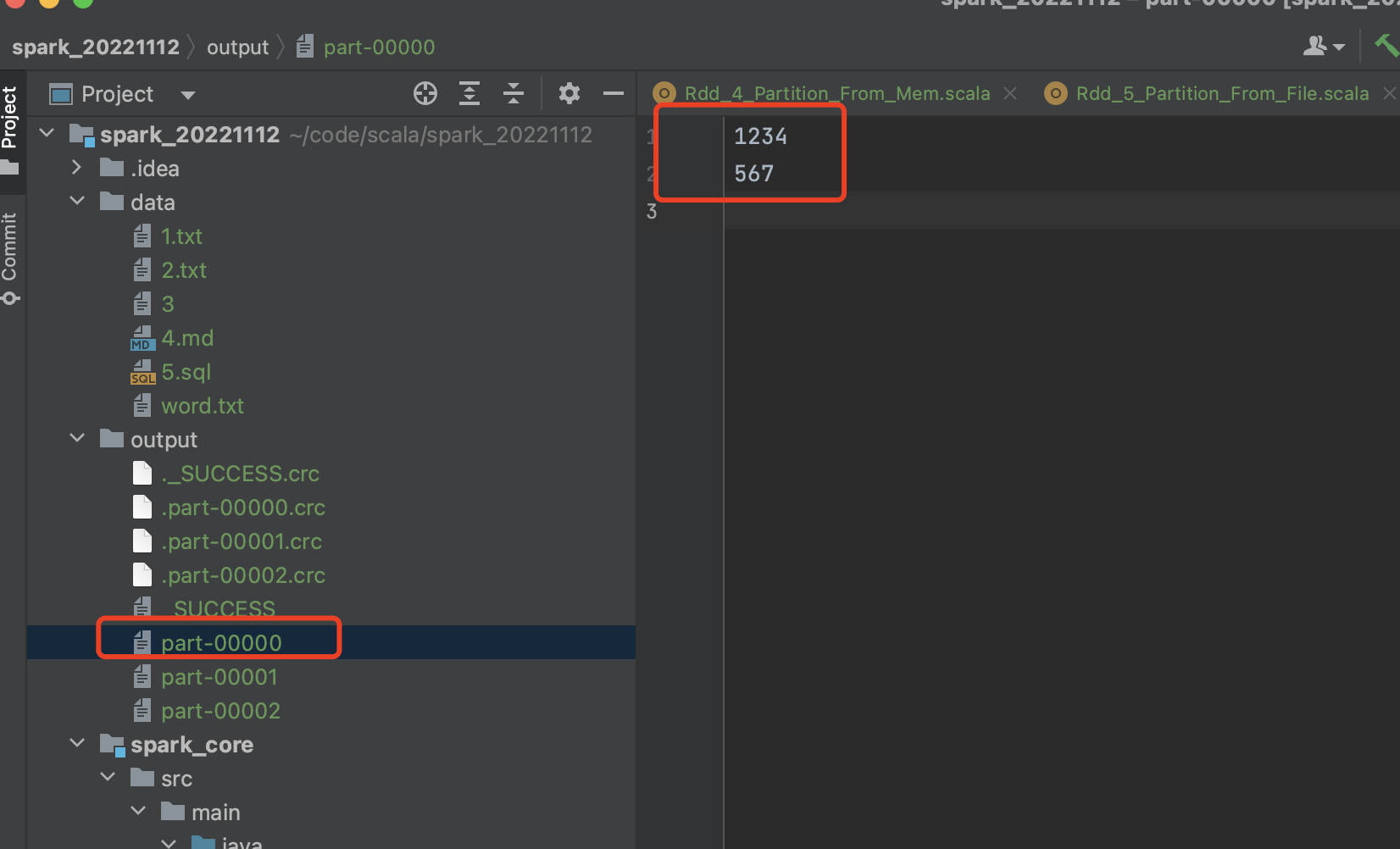
分区1预期 [0, 6] => 1234\n
567\n
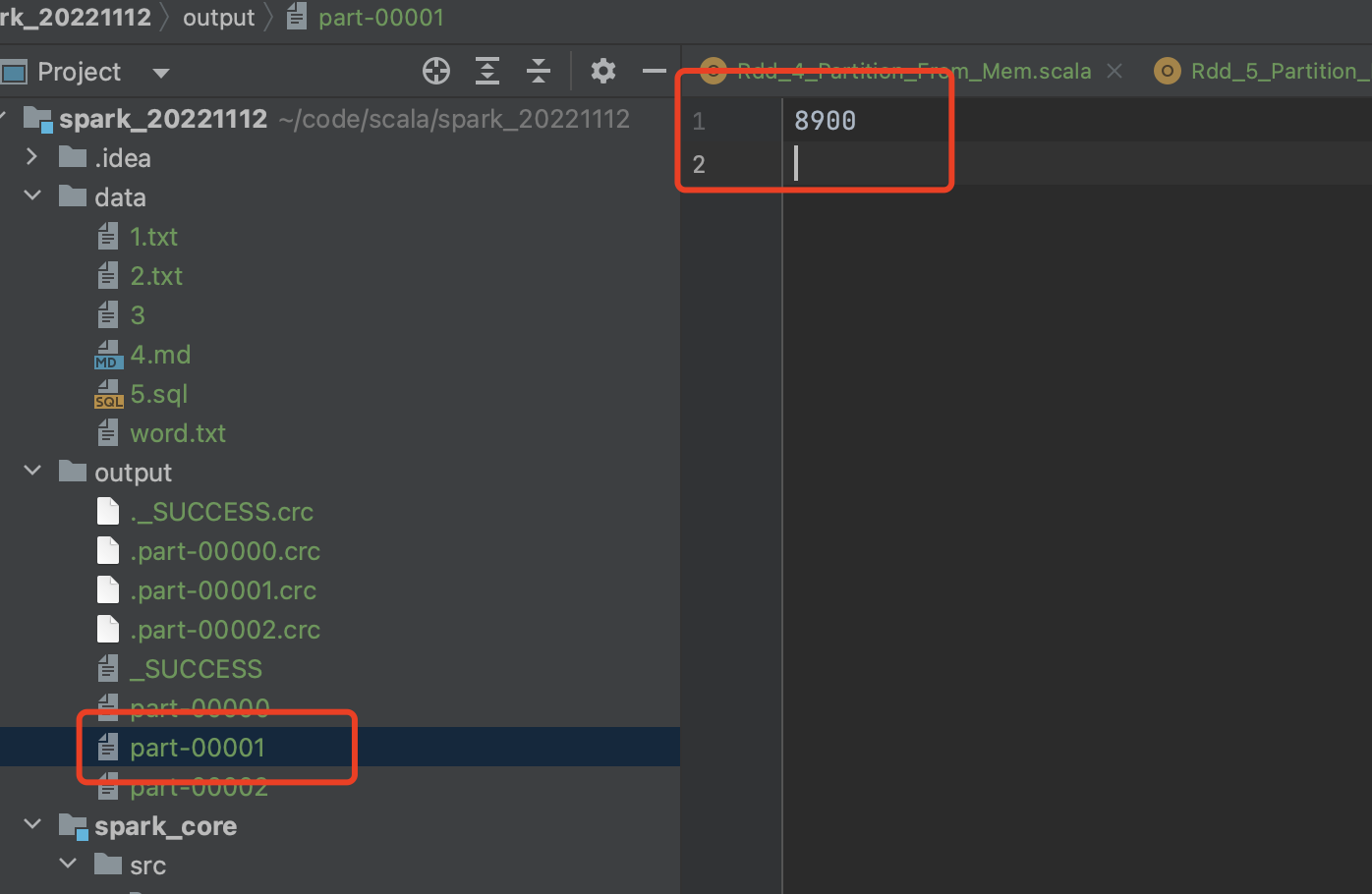
分区2预期[6, 12] => 但是上一个分区因为是偏移量到了某一行,某行就都被读走了,所以真实的
=> 8900
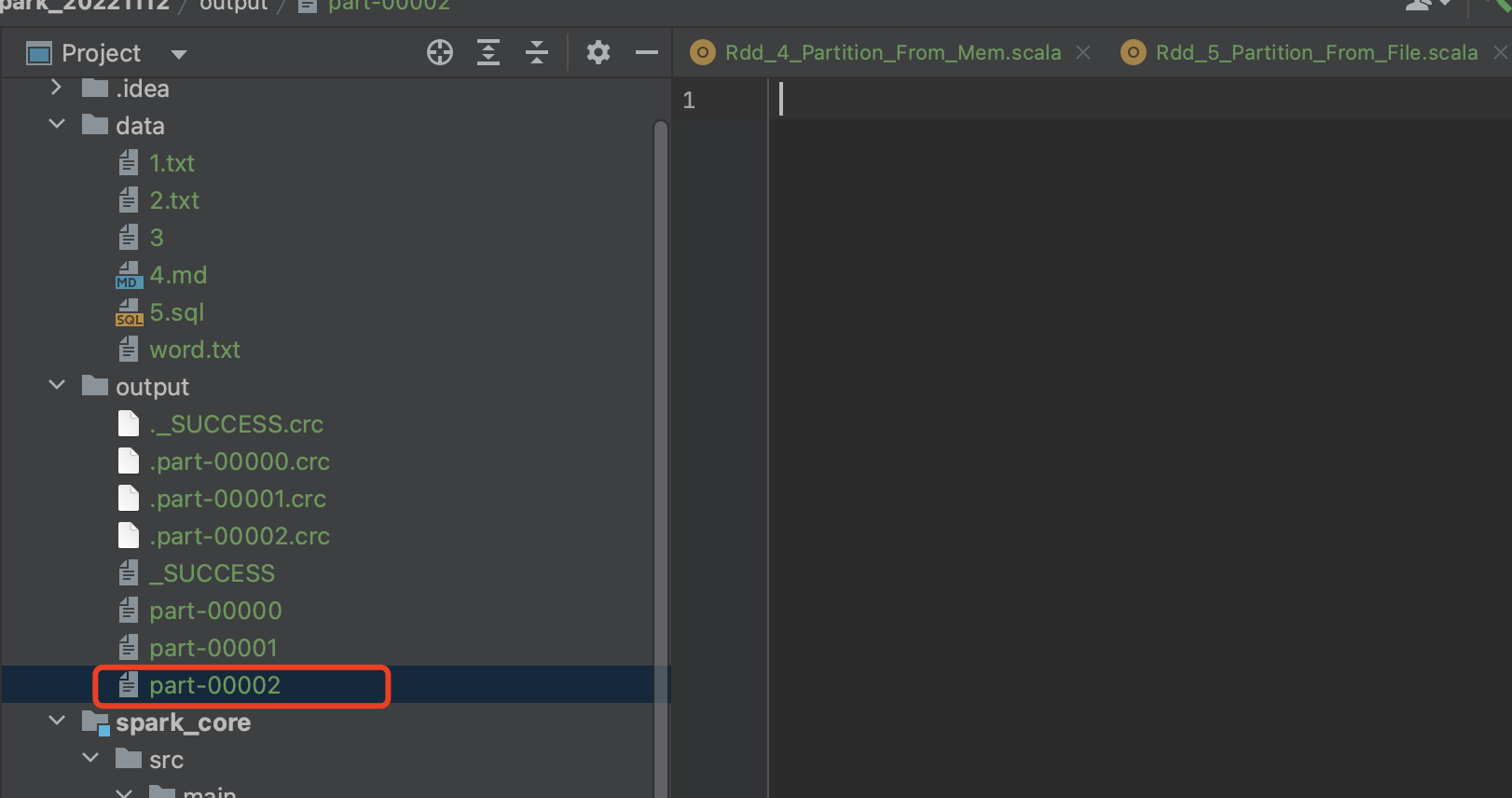
分区3预计[12, 13] => 已无数据可读
2.2.3 完整示例
package com.lzw.bigdata.spark.core.rdd_basic_usage_1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Rdd_5_Partition_From_File {
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
// .set("spark.default.parallelism", "5")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
/*
1234\n
567\n
8900
分区数: 13 bytes / 2(这里2是minPartitions) = 6
13 bytes / 6 bytes = 2分区 + 剩余的1byte => 1/6 > 0.1 => 3分区
每个分区里面的数据, (hadoop按偏移量之后按行读取):
分区1预期 [0, 6] => 1234\n
567\n
分区2预期[6, 12] => 但是上一个分区因为是偏移量到了某一行,某行就都被读走了,所以真实的
=> 8900
分区3预计[12, 13] => 已无数据可读
*/
val rdd: RDD[String] = sparkContext.textFile("data/word.txt", 2)
rdd.saveAsTextFile("output")
sparkContext.stop()
}
}
原文地址:http://www.cnblogs.com/baoshu/p/spark_5.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性