
问题:怎么将源代码中的加密字体正常显示?
当爬取数据时,经常会发现一些既不是想要的对应文字,也不是乱码。那么该网站是进行了字体加密的反爬虫。如何解决这一问题呢?
那么就会用到了我们的TTFont模块:
from fontTools.ttLib import TTFont那么我们来看一下解决的流程,以实习僧网为例:
实习僧:https://www.shixiseng.com
1、获取网页源代码
url = "https://www.shixiseng.com/interns?keyword=python&city=%E5%85%A8%E5%9B%BD&type=intern"
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.52"}
resp = requests.get(url,headers=headers)
print(resp.text)找到加密的字体,如:

2、在网页中找到加密字体格式
通常在网页的(网络-字体-url)中,可直接转码下载。

下载后点击打开即可,这里会用到一个浏览文件的辅助性软件(High-Logic FontCreator),下载打开查看。
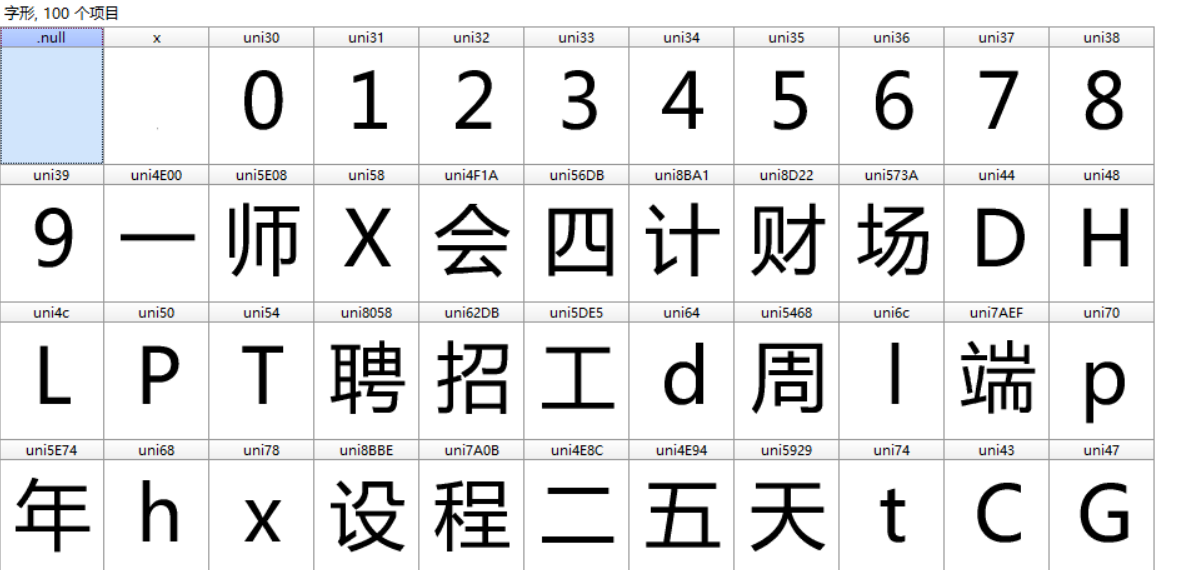
然后将文件放到pycharm中。
3、添加解密字体
找到相应文件(file),将数据进行手动整理至glyfmap字典中以用于读取。(数据不多手动整理即可,若编程能力底子厚可写一个程序自动提取内容,不过这个过程太麻烦0.0)。
font = TTFont("file")
glyf = font["glyf"]
glyfmap={
0: glyf['uni30'],
1: glyf['uni31'],
2: glyf['uni32'],
3: glyf['uni33'],
4: glyf['uni34'],
5: glyf['uni35'],
6: glyf['uni36'],
7: glyf['uni37'],
8: glyf['uni38'],
9: glyf['uni39'],
'p': glyf['uni70'],
'y': glyf['uni79'],
't': glyf['uni74'],
'h': glyf['uni68'],
'o': glyf['uni6f'],
'n': glyf['uni6e'],
'工': glyf['uni5DE5'],
'程': glyf['uni7A0B'],
'师': glyf['uni5E08'],
}4、寻找对应关系
在这里观察到&#由0代替,运用.replace代替即可。
resp = requests.get(url,headers=headers)
response = resp.text.replace("&#",str(0))- 读取解密字体
cont = font.getBestCmap()
- 遍历键和值,将键转化为十六进制。
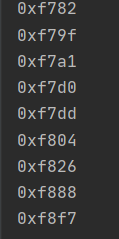
- 将cont中的值转化为glyfmap中的值(赋值)。
name = glyf[name]遍历glyfmap字典中的值,若其值与cont中的值相同,将源代码中的加密字体转换成解密后的字体。
for data,name in cont.items():
hex_data = hex(data)
print(hex_data)
name = glyf[name]
for data_new,name_new in glyfmap.items():
if name_new == name:
response = re.sub(hex_data,str(data_new),response)- 打印后就可以看到解密好的字体了。

5、完整代码展示
import requests
from fontTools.ttLib import TTFont
import re
url = "https://www.shixiseng.com/interns?keyword=python&city=%E5%85%A8%E5%9B%BD&type=intern"
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.52"}
# resp = requests.get(url,headers=headers)
# print(resp.text)
font = TTFont("file1")
glyf = font["glyf"]
glyfmap={
0: glyf['uni30'],
1: glyf['uni31'],
2: glyf['uni32'],
3: glyf['uni33'],
4: glyf['uni34'],
5: glyf['uni35'],
6: glyf['uni36'],
7: glyf['uni37'],
8: glyf['uni38'],
9: glyf['uni39'],
'p': glyf['uni70'],
'y': glyf['uni79'],
't': glyf['uni74'],
'h': glyf['uni68'],
'o': glyf['uni6f'],
'n': glyf['uni6e'],
'工': glyf['uni5DE5'],
'程': glyf['uni7A0B'],
'师': glyf['uni5E08'],
}
# 寻找对应关系
resp = requests.get(url,headers=headers)
response = resp.text.replace("&#",str(0))
# 读取解密字体
cont = font.getBestCmap()
for data,name in cont.items():
hex_data = hex(data)
print(hex_data)
name = glyf[name]
for data_new,name_new in glyfmap.items():
if name_new == name:
response = re.sub(hex_data,str(data_new),response)
print(response)
原文地址:http://www.cnblogs.com/LoLong/p/16916744.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性