
首先进行单机安装,见以下:
Elasticsearch + Kibana + IK分词器安装 – 檀潇兵 – 博客园 (cnblogs.com)
1 集群搭建
1.1 修改配置
每台机器修改elasticsearch.yml配置文件
cd /usr/local/es/elasticsearch-7.6.1/config/ sudo vim elasticsearch.yml #修改以下配置,保存后重启elasticsearch即可 discovery.seed_hosts: ["124.221.237.87","124.221.243.252","180.76.177.17"] cluster.initial_master_nodes: ["node-1","node-2","node-3"]
1.2 检查集群情况
选择其中一个节点进行访问124.221.243.252:9200/_cat/health?v

出现以上节点信息即搭建集群成功。
其中参数说明:
cluster:集群名称
status:集群状态 green 表示集群一切正常;yellow 表示集群不可靠但可用(单节点状态);red 集群不可用,有故障。
node.total:节点总数量
node.data:数据节点的数量
shards:存活的分片数量
pri:主分片数量
relo:迁移中的分片数量
init:初始化中的分片数量
unassign:未分配的分片
pending_tasks:准备中的任务
max_task_wait_time:任务最长等待时间
active_shards_percent:激活的分片百分比
2 ElasticSearch-Head插件安装
由于es服务启动之后,访问界面比较丑陋,为了更好的查看索引库当中的信息, 我们可以通过安装elasticsearch-head这个插件来实现,这个插件可以更方便快 捷的看到es的管理界面 elasticsearch-head这个插件是es提供的一个用于图形化界面查看的一个插件工 具,可以安装上这个插件之后,通过这个插件来实现我们通过浏览器查看es当中 的数据 安装elasticsearch-head这个插件这里提供两种方式进行安装,第一种方式就是 自己下载源码包进行编译,耗时比较长,网络较差的情况下,基本上不可能安装 成功。 第二种方式就是直接使用我已经编译好的安装包,进行修改配置即可 要安装elasticsearch-head插件,需要先安装Node.js。
2.1 安装node.js

cd /usr/local/es wget https://npm.taobao.org/mirrors/node/v8.1.0/node-v8.1.0-linux-x64.tar.gz tar -zxvf node-v8.1.0-linux-x64.tar.gz -C /usr/local/es/ sudo ln -s /usr/local/es/node-v8.1.0-linux-x64/lib/node_modules/npm/bin/npm-cli.js /usr/local/bin/npm sudo ln -s /usr/local/es/node-v8.1.0-linux-x64/bin/node /usr/local/bin/node vi /etc/profile export NODE_HOME=/usr/local/es/node-v8.1.0-linux-x64 export PATH=:$PATH:$NODE_HOME/bin source /etc/profile
#验证安装成功
node -v
npm -v
2.2 安装ElasticSearch-Head
链接:https://pan.baidu.com/s/1bPQU9AXMmLYlil_wirpfCw
提取码:89av
通过百度网盘获取安装包并上传至/usr/local/es并解压。
tar -zxvf elasticsearch-head-compile-after.tar.gz cd /usr/local/es/elasticsearch-head vim Gruntfile.js
connect: { server: { options: { hostname: '*', port: 9100, base: '.', keepalive: true } } }
cd /usr/local/es/elasticsearch-head/_site vim app.js 在Vim中输入「:4354」,定位到第4354行,修改 http://localhost:9200为http://124.221.237.87:9200
#启动 cd /usr/local/es/elasticsearch-head/node_modules/grunt/bin/ ./grunt server #后台启动 nohup ./grunt server >/dev/null 2>&1 &
Running "connect:server" (connect) taskWaiting forever...Started connect web server on http://192.168.52.100:9100
如何停止:elasticsearch-head进程
执行以下命令找到elasticsearch-head的插件进程,然后使用kill -9 杀死进程即可
netstat -nltp | grep 9100
kill -9 8328
访问http://ip:9100/地址出现以下界面即配置成功。
3 集群原理详解
# 创建指定分片数量、副本数量的索引 PUT /job_idx_shard_temp { "mappings":{ "properties":{ "id":{"type":"long","store":true}, "area":{"type":"keyword","store":true}, "exp":{"type":"keyword","store":true}, "edu":{"type":"keyword","store":true}, "salary":{"type":"keyword","store":true}, "job_type":{"type":"keyword","store":true}, "cmp":{"type":"keyword","store":true}, "pv":{"type":"keyword","store":true}, "title":{"type":"text","store":true}, "jd":{"type":"text"} } }, "settings":{ "number_of_shards":3, "number_of_replicas":2 } } # 查看分片、主分片、副本分片 GET /_cat/indices?v
3.3 Elasticsearch重要工作流程
3.3.1 ElasticSearch文档写入原理
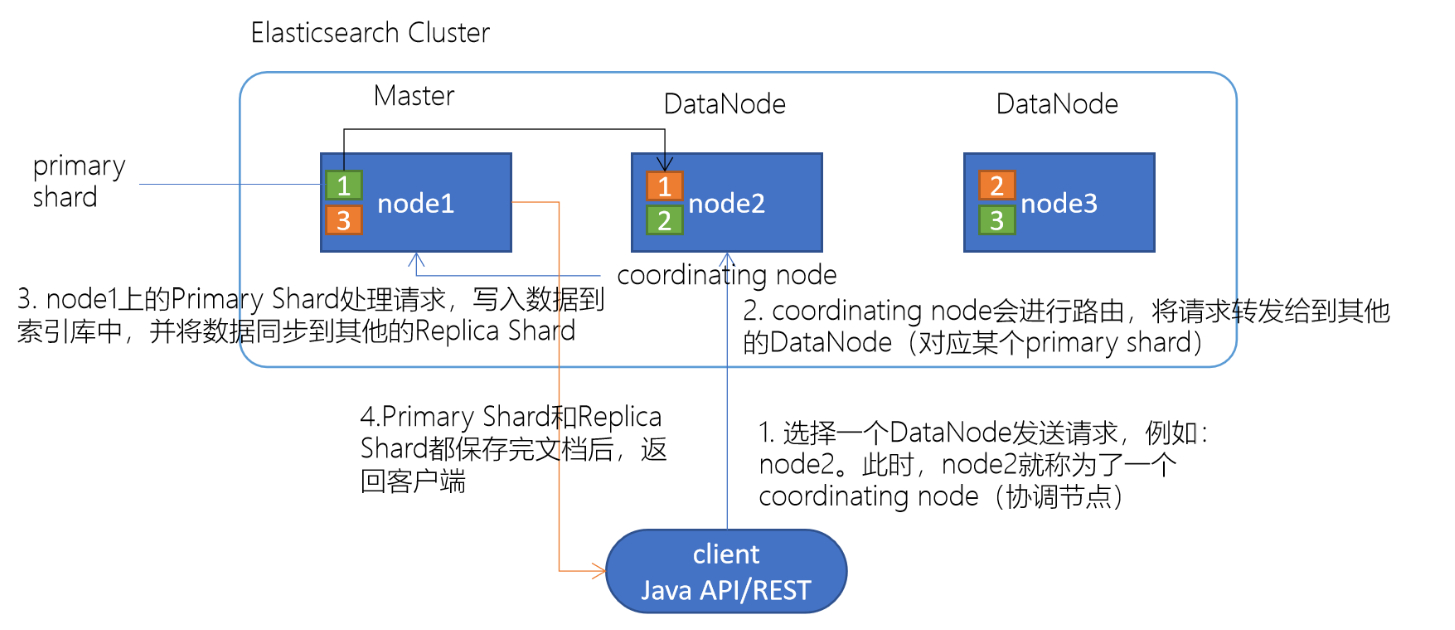
1.选择任意一个DataNode发送请求,例如:node2。此时,node2就成为一个coordinating node(协调节点)。
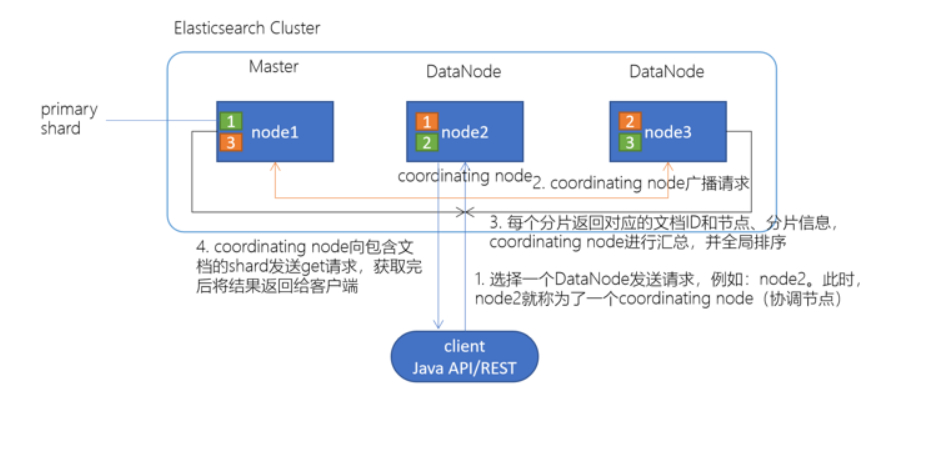
client发起查询请求,某个DataNode接收到请求,该DataNode就会成为协调节点(Coordinating Node),协调节点(Coordinating Node)将查询请求广播到每一个数据节点,这些数据节点的分片会处理该查询请求,每个分片进行数据查询,将符合条件的数据放在一个优先队列中,并将这些数据的文档ID、节点信息、分片信息返回给协调节点,协调节点将所有的结果进行汇总,并进行全局排序,协调节点向包含这些文档ID的分片发送get请求,对应的分片将文档数据返回给协调节点,最后协调节点将数据返回给客户端。
3.4 ElasticSearch准实时索引实现
3.4.1 溢写到文件系统缓存
原文地址:http://www.cnblogs.com/licaibin666/p/16917596.html