

💡 作者:韩信子@ShowMeAI
📘 机器学习实战系列:https://www.showmeai.tech/tutorials/41
📘 本文地址:https://www.showmeai.tech/article-detail/337
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容

近年来,可解释的人工智能(XAI)和可解释的机器学习引起了越来越多的关注,因为直接把模型当做黑箱使用信任度和可控度都会受影响。有一些领域,模型的可解释性更加重要,例如在医疗领域,患者会质疑为什么模型诊断出他们患有某种疾病。
在本篇内容中, ShowMeAI 将给大家讲解一个流行的模型解释方法 SHAP(SHapley Additive exPlanations),并基于实际案例讲解如何基于工具库对模型做解释。
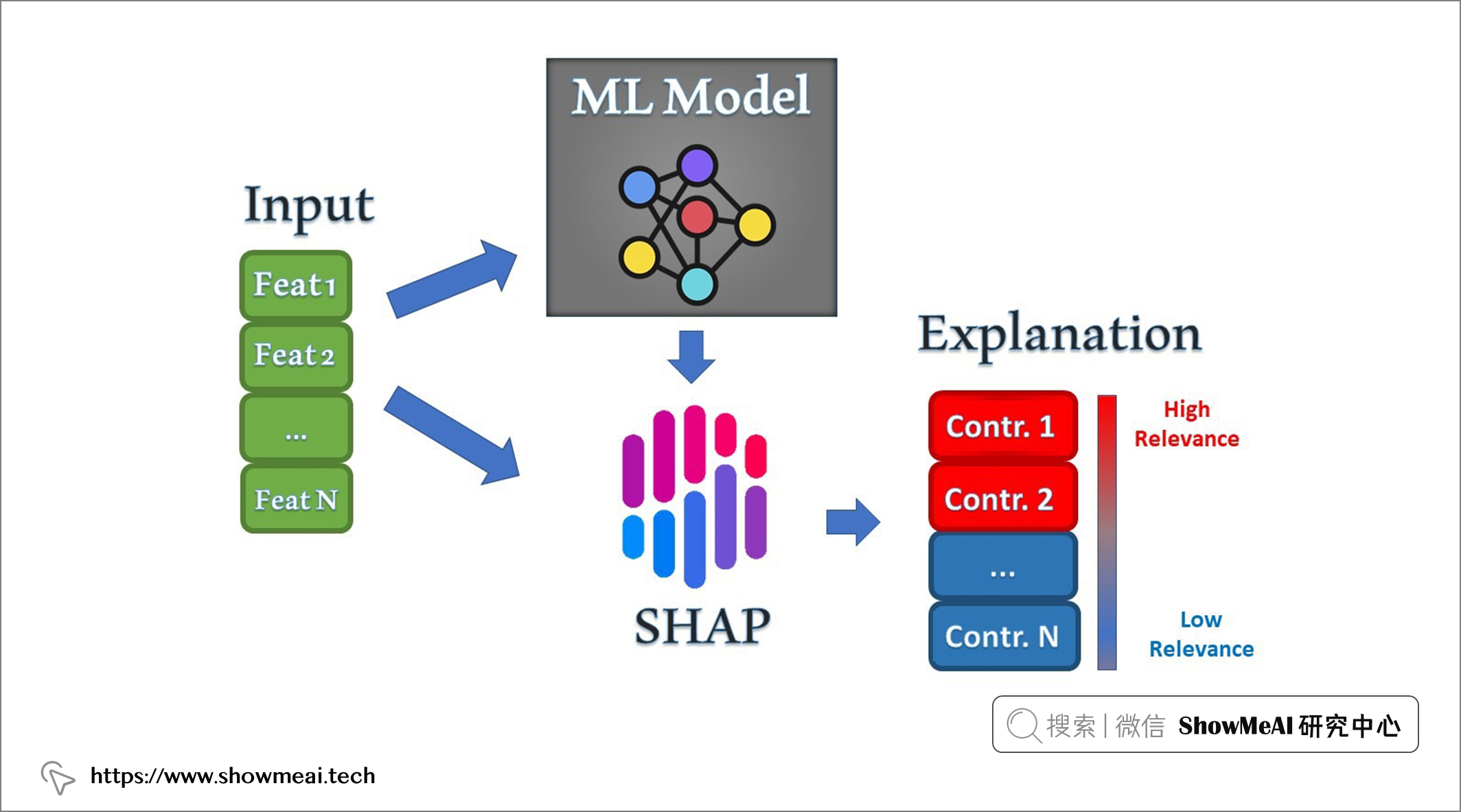
💡 模型可解释方法的划分
我们对各类模型可解释方法进行划分,有以下一些划分维度:
- 模型无关和模型特定:一些方法可用于各种模型,而另一些方法是为解释特定模型而创建的。
- 全局和局部解释:本地意味着进行分析以了解如何做出特定预测。 另一方面,全局解释研究了影响所有预测的因素。
- 基于模型和事后归因:基于模型的模型是我们可以直接理解的模型,例如线性回归模型。 另一类是事后解释模型的归因方法,大多数方法都属于这一类。
💡 SHAP 原理
📘SHAP 全称是 SHapley Additive exPlanation,是比较全能的模型可解释性的方法,既可作用于全局解释,也可以局部解释,即单个样本来看,模型给出的预测值和某些特征可能的关系,可以用SHAP来解释。

SHAP 属于模型事后解释的方法,核心思想是计算特征对模型输出的边际贡献,再从全局和局部两个层面对『黑盒模型』进行解释。SHAP 构建一个加性的解释模型,所有的特征都视为『贡献者』。
对于每个预测样本,模型都产生一个预测值,SHAP value 就是该样本中每个特征所分配到的数值。

基本思想:计算一个特征加入到模型时的边际贡献,然后考虑到该特征在所有的特征序列的情况下不同的边际贡献,取均值,即某该特征的 SHAP baseline value。
💡 案例实战讲解
我们来拿一个场景案例讲解一下SHAP如何进行模型可解释分析,用到的数据是人口普查数据,我们会调用 Python 的工具库库 SHAP 直接分析模型。
💦 数据说明
ShowMeAI在本例中使用到的是 🏆美国人口普查收入数据集,任务是根据人口基本信息预测其年收入是否可能超过 50,000 美元,是一个二分类问题。
数据集可以在以下地址下载: 📘 https://archive.ics.uci.edu/ml/datasets/Adult 📘 https://archive.ics.uci.edu/ml/machine-learning-databases/adult/
数据从美国1994年人口普查数据库抽取而来,可以用来预测居民收入是否超过50K/year。
该数据集类变量为年收入是否超过50k,属性变量包含年龄、工种、学历、职业、人种等重要信息,值得一提的是,14个属性变量中有7个类别型变量。
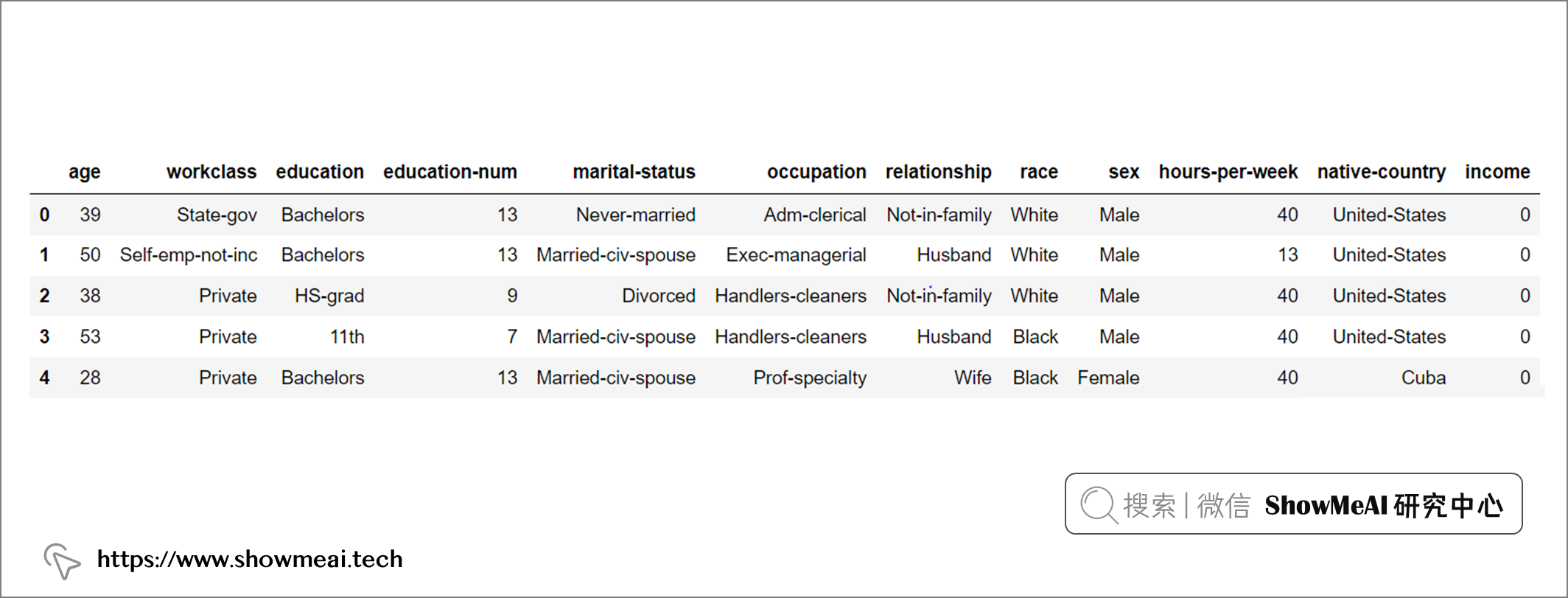
数据集各属性是:其中序号0~13是属性,14是类别。
| 字段序号 | 字段名 | 含义 | 类型 |
|---|---|---|---|
| 0 | age | 年龄 | Double |
| 1 | workclass | 工作类型* | string |
| 2 | fnlwgt | 序号 | string |
| 3 | education | 教育程度* | string |
| 4 | education_num | 受教育时间 | double |
| 5 | maritial_status | 婚姻状况* | string |
| 6 | occupation | 职业* | string |
| 7 | relationship | 关系* | string |
| 8 | race | 种族* | string |
| 9 | sex | 性别* | string |
| 10 | capital_gain | 资本收益 | string |
| 11 | capital_loss | 资本损失 | string |
| 12 | hours_per_week | 每周工作小时数 | double |
| 13 | native_country | 原籍* | string |
| 14(label) | income | 收入标签 | string |
💦 SHAP计算 & 模型解释
from sklearn.model_selection import train_test_split
import lightgbm as lgb
import shap
shap.initjs()
X,y = shap.datasets.adult()
X_display,y_display = shap.datasets.adult(display=True)# create a train/test split
# 训练集与测试集切分及处理
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)
d_train = lgb.Dataset(X_train, label=y_train)
d_test = lgb.Dataset(X_test, label=y_test)# create a simple model
# 模型参数
params = {
"max_bin": 512,
"learning_rate": 0.05,
"boosting_type": "gbdt",
"objective": "binary",
"metric": "binary_logloss",
"num_leaves": 10,
"verbose": -1,
"min_data": 100,
"boost_from_average": True
}
# 模型训练
model = lgb.train(params, d_train, 10000, valid_sets=[d_test], early_stopping_rounds=50, verbose_eval=1000)# explain the model
# 模型解释
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)# visualize the impact of each features
shap.summary_plot(shap_values, X)
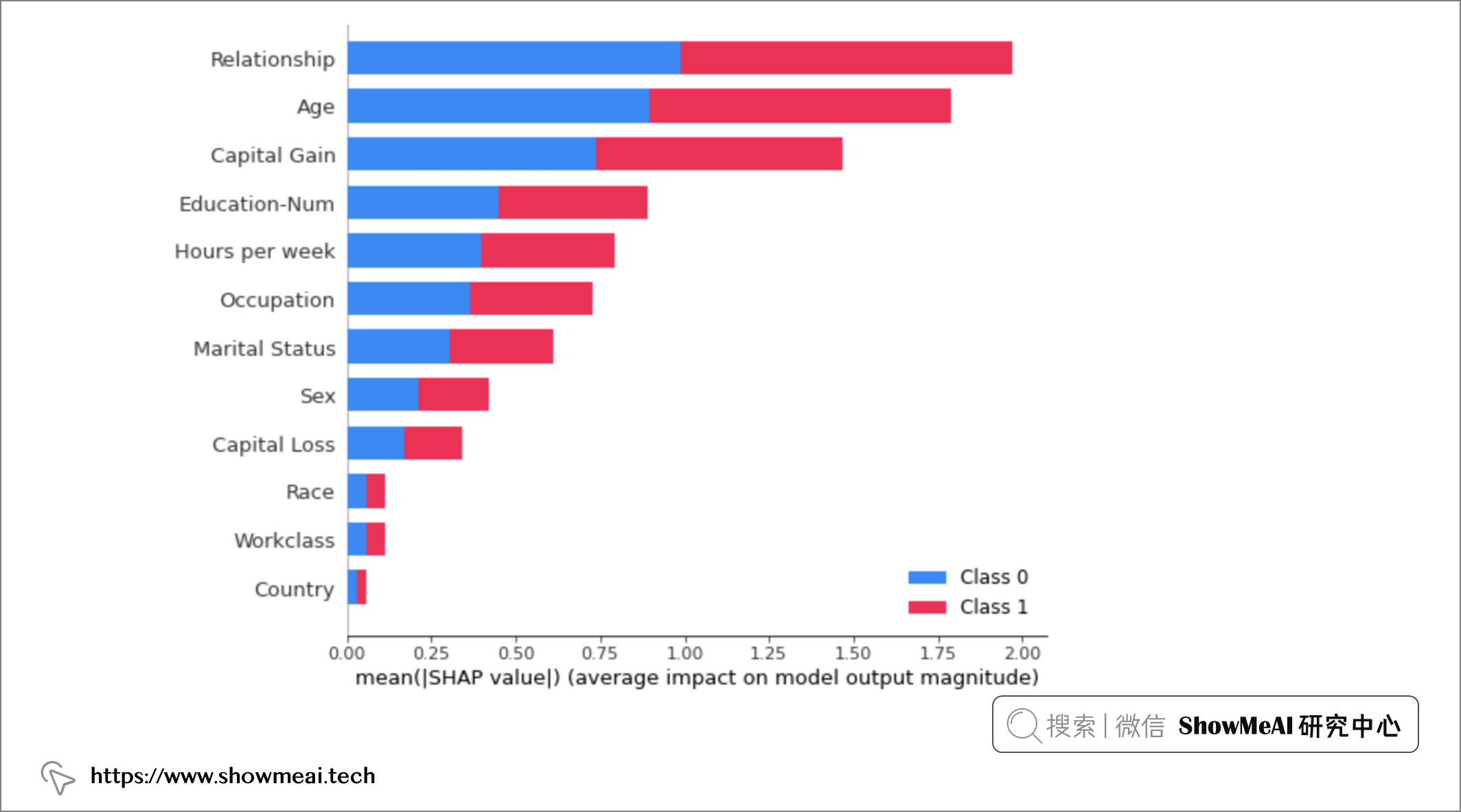
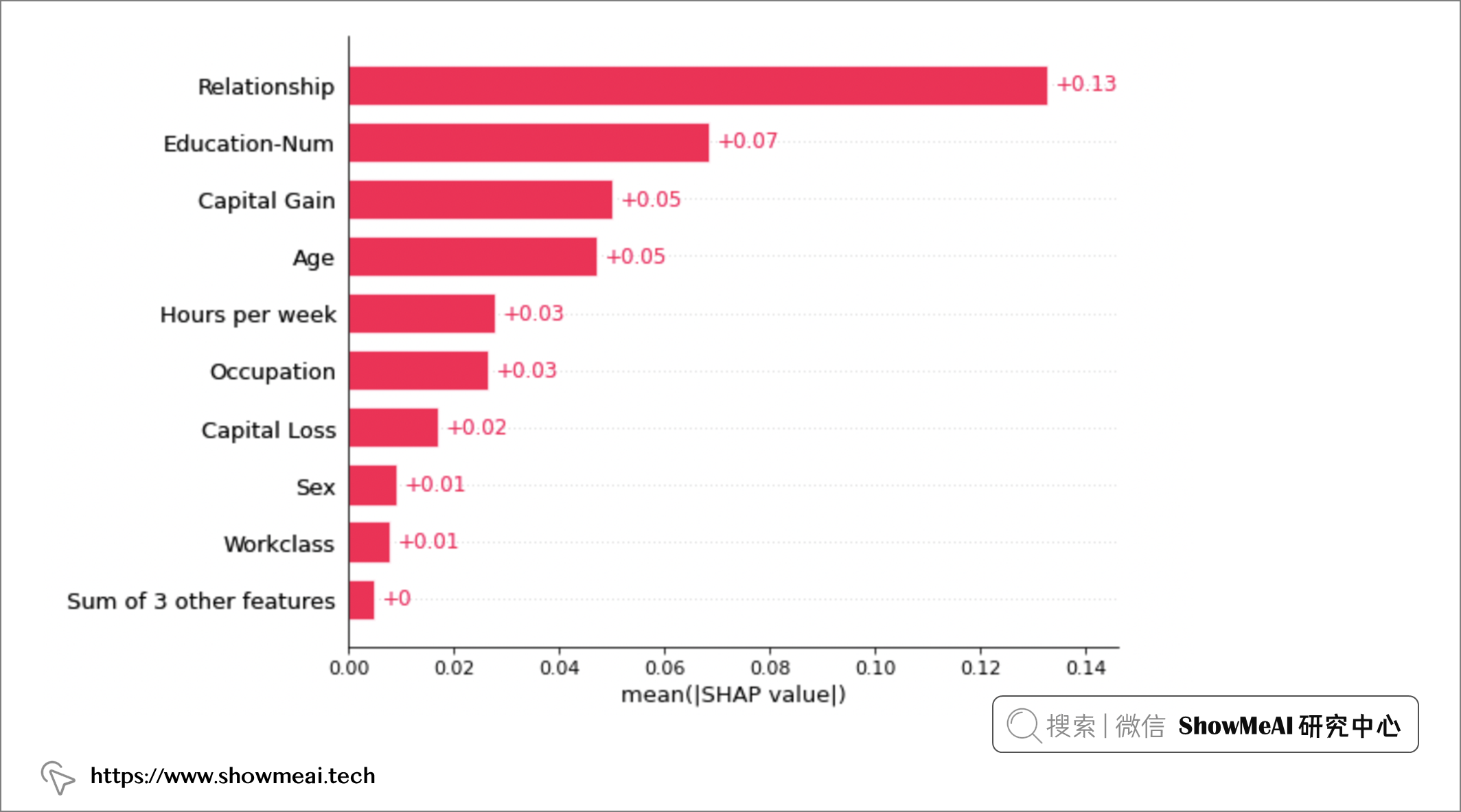
上图中的SHAP结果值,告诉我们不同的特征维度(输入)对于当前模型的重要程度,包括总体的重要程度,以及对每个类别的判定的影响程度。
参考资料
- 📘 SHAP 文档:https://shap.readthedocs.io/en/latest/index.html
- 📘 美国人口普查收入数据集:https://archive.ics.uci.edu/ml/datasets/census+income
推荐阅读
- 🌍 数据分析实战系列 :https://www.showmeai.tech/tutorials/40
- 🌍 机器学习数据分析实战系列:https://www.showmeai.tech/tutorials/41
- 🌍 深度学习数据分析实战系列:https://www.showmeai.tech/tutorials/42
- 🌍 TensorFlow数据分析实战系列:https://www.showmeai.tech/tutorials/43
- 🌍 PyTorch数据分析实战系列:https://www.showmeai.tech/tutorials/44
- 🌍 NLP实战数据分析实战系列:https://www.showmeai.tech/tutorials/45
- 🌍 CV实战数据分析实战系列:https://www.showmeai.tech/tutorials/46
- 🌍 AI 面试题库系列:https://www.showmeai.tech/tutorials/48

原文地址:http://www.cnblogs.com/showmeai/p/16921564.html