
基于强化学习的多智能体系统合作伙伴选择
总结:
- 提出了一个合作伙伴选择模型,模型中的智能体先由单独的奖励目标函数用Q-learnng训练(环境为重复的囚徒困境,进行一定轮次),并且训练过程中的交互信息都会被呈现给其他智能体。基于该信息每个智能体在每一轮开始时挑选合作伙伴并一起参与该困境并从经验中学习。(目标是在一定轮次后各自获得尽可能高的个人奖励)
- 每一轮分为两个阶段:第一阶段,每个代理选择一个合作伙伴(不能选择自己,被选中的人也不能拒绝);第二阶段一起进行困境游戏,并得到各自的动作选择(合作或背叛)最终得到奖励,奖励必须互相告知(智能体的奖励只能从困境中获得)
- 选择过程中每个代理的最近一个动作是可见的(四种动作:ALL-C,ALL-D,TFT,revTFT)
- 贡献主要在于提出了合作伙伴选择的机制,每个智能体有两个策略,一个是选择伙伴的策略根据其他智能体之前的表现,一个是训练过程中的动作选择策略(合作或者背叛)
环境
主要是重复的囚徒困境,连续性的游戏,上一轮的结果关系到下一轮的伙伴选择
主要内容
- Q-learning,采用e-贪婪策略
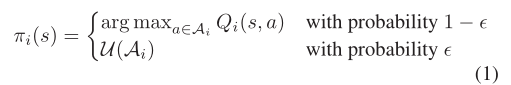
- 更新函数
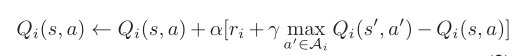
- 四个阶段:
- 一开始没有伙伴选择,智能体都将得到背叛的动作
- 智能体开始选择伙伴,刚开始选择的伙伴都是具有合作倾向的智能体并与之合作
- 智能体开始学会惩罚那些背叛的智能体,当被其他合作倾向智能体选择时也开始选择合作
- 最后得到整体收益稳步上升,智能体开始整体倾向合作提高社会收益
原文地址:http://www.cnblogs.com/e557/p/16926252.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性