
0. 前言
- 本系列文章主要是源于对《搜索引擎的技术架构》一书的读书笔记,其中会掺杂在其他文章或书籍的内容以及我个人对搜索引擎的理解,阅读顺序也没有按照书中目录的顺序来,相比于单纯的知识点总结,本系列更像是我借由此书来谈一谈我对搜索引擎的理解。
- 本系列文章专注于描述搜索引擎的技术架构,对搜索引擎的历史发展和当下定位不过多赘述。
1. 目标
简单来说,搜索引擎的目标可以用三个词来概括:更全、更快、更准。
更全:针对搜索引擎的所索引网页数量,当前所有的商业搜索引擎的索引网页覆盖范围都能只能覆盖互联网网页的一部分,
更快:即是指数据的时效性,也是指用户搜索时的响应速度。
更准:搜索结果更加准确。
对于搜索引擎来说,“更准”是最为关键的目标,是其核心竞争力。
2.搜索引擎的技术架构
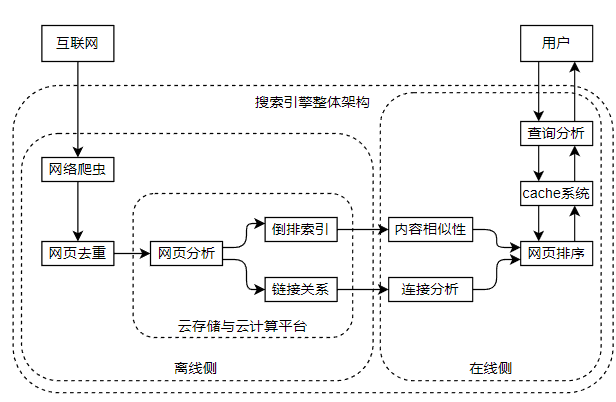
搜索引擎在整体架构上可以分为离线和在线,离线的生效发生在用户查询之前,在线发生在用户查询之后。
2.1 离线侧
离线侧的目标是将海量的互联网的信息转化为结构化的本地信息,通过存储在倒排索引的方式供在线进行高效的查询。
离线整体流程可以描述为
- 搜索引擎通过网络爬虫将互联网信息获取到本地,对于内容相似或者完全重复的内容,通过网页去重进行检测并去掉重复的内容。
- 接着搜索引擎会对网页进行分析,抽取出网页主体内容等网页相关信息以及其与其他网页的连接关系。
- 其中网页相关内容使用“倒排索引”这种高效查询结构来保存,可以加快用户的查询速度。
- 保存链接关系的目的在于通过链接分析可以从另一方面感知页面的重要性,帮助网页进行排序
- 对于百亿级别网页的分析和计算,使用少量的机器是不现实的,目前的商业搜索引擎为此开发或者使用一整套的云存储与云计算平台,使用上万台服务器来搭建可靠的信息存储与计算架构。
2.2 在线侧
在线侧做的事情发生在用户输出查询词之后,其目的是分析出用户的意图并从索引中找到与之匹配的网页。
在线整体流程可以描述为
- 当搜索引擎接收到查询词之后,首先对查询词进行分析,从而推导用户的真实意图
- 在缓存中进行查找,搜索引擎的cache系统存储了不同查询意图对应的搜索结果,目的是节省一些热门意图的重复资源消耗,也能加快响应速度。
- 当缓存内容无法满足需求的时候,搜索引擎会进入网页排序阶段,根据用户的查询词与倒排索引中的网页内容,计算出内容的相似性,通过链接分析计算出网页的重要性,两者作为参考对网页进行排序并作为查询结果返回。
原文地址:http://www.cnblogs.com/Hugh-Locke/p/16930496.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性