

prompt 的影响因素
Motivation
- Prompt 中 Example 的排列顺序对模型性能有较大影响(即使已经校准参见好的情况下,选取不同的排列顺序依然会有很大的方差):
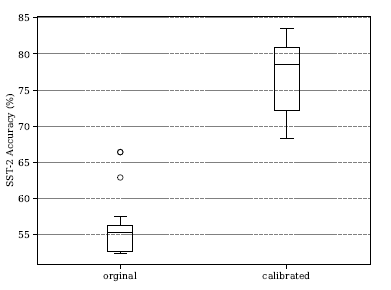
- 校准可以大幅度提高准确率,但是不同的排列顺序方差依然很大
Analysis
- 提出探测集(probing set),流程如下:
- 训练集 $S={(x_i, y_i)}$,模板转换函数(将一组数据转换为自然语言) $t_i=\tau (x_i,y_i)=input:x_i,type:y_y$,因此自然语言数据集 $S’=\{t_i\}$;
- 排列方程集合 $\mathfrak{F}=\{f_m\},m=1\rightarrow n!$,$f_m(S’)=c_m$ 为一种训练数据的组合顺序($m=1\rightarrow n!$);
- 对于每一种排列组合$c_m$,使用语言模型进行去预测后续的句子(注意这里没有加上测试集的问题,纯粹对训练集进行组合),得到模型生成的新的 example:$g_m\propto P(…|c_m;\theta)$,$\theta$为语言模型的参数,对生成序列解析得到模型生成的数据集:$D=\{\tau ^{-1}(g_m)\},m=1\rightarrow n!$。
- 针对探测集提出两种评估 prompt 的指标:
-
Global Entropy
- 对探测集合中探测数据$(x’_i, \sout{y’_i})\in D$(生成的 label 不需要,不具有参考意义),选择一种排列组合(上下文)$c_m$进行推理得到$\hat{y_{i,m}}$,即:
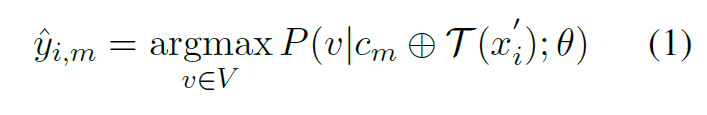
- 对探测集中的每个探测数据进行预测,求得每个预测的种类占探测集的比例:
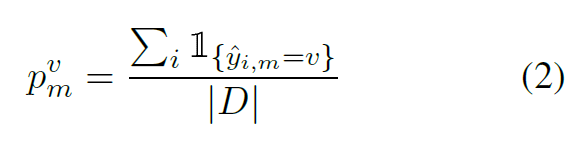
- 最后求熵(熵反应了预测各个种类的均匀程度,预测的正确与否并不重要,假如熵非常小,说明预测的结果 bias 非常大):
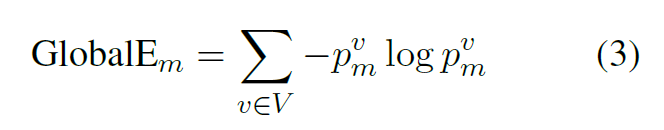
-
Local Entropy
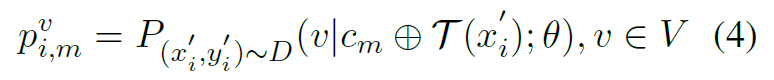
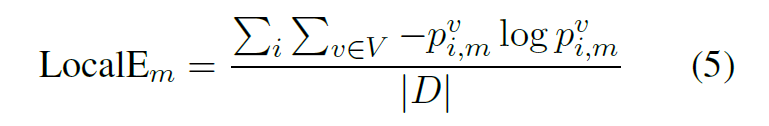
- 与全局熵类似,只不过先求熵再求和。
原文地址:http://www.cnblogs.com/metaz/p/16798692.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性